 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy-Preserving Structureless Visual Localization via Image Obfuscation
Apr 13, 2026Visual localization is the task of estimating the camera pose of an image relative to a scene representation. In practice, visual localization systems are often cloud-based. Naturally, this raises privacy concerns in terms of revealing private details through the images sent to the server or through the representations stored on the server. Privacy-preserving localization aims to avoid such leakage of private details. However, the resulting localization approaches are significantly more complex, slower, and less accurate than their non-privacy-preserving counterparts. In this paper, we consider structureless localization methods in the context of privacy preservation. Structureless methods represent the scene through a set of reference images with known camera poses and intrinsics. In contrast to existing methods proposing representations that are as privacy-preserving as possible, we study a simple image obfuscation approach based on common image operations, e.g., replacing RGB images with (semantic) segmentations. We show that existing structureless pipelines do not need any special adjustments, as modern feature matchers can match obfuscated images out of the box. The results are easy-to-implement pipelines that can ensure both the privacy of the query images and the scene representations. Detailed experiments on multiple datasets show that the resulting methods achieve state-of-the-art pose accuracy for privacy-preserving approaches.
The Role and Relationship of Initialization and Densification in 3D Gaussian Splatting
Mar 21, 20263D Gaussian Splatting (3DGS) has become the method of choice for photo-realistic 3D reconstruction of scenes, due to being able to efficiently and accurately recover the scene appearance and geometry from images. 3DGS represents the scene through a set of 3D Gaussians, parameterized by their position, spatial extent, and view-dependent color. Starting from an initial point cloud, 3DGS refines the Gaussians' parameters as to reconstruct a set of training images as accurately as possible. Typically, a sparse Structure-from-Motion point cloud is used as initialization. In order to obtain dense Gaussian clouds, 3DGS methods thus rely on a densification stage. In this paper, we systematically study the relation between densification and initialization. Proposing a new benchmark, we study combinations of different types of initializations (dense laser scans, dense (multi-view) stereo point clouds, dense monocular depth estimates, sparse SfM point clouds) and different densification schemes. We show that current densification approaches are not able to take full advantage of dense initialization as they are often unable to (significantly) improve over sparse SfM-based initialization. We will make our benchmark publicly available.
Benchmarking Efficient & Effective Camera Pose Estimation Strategies for Novel View Synthesis
Mar 20, 2026Novel view synthesis (NVS) approaches such as NeRFs or 3DGS can produce photo-realistic 3D scene representation from a set of images with known extrinsic and intrinsic parameters. The necessary camera poses and calibrations are typically obtained from the images via Structure-from-Motion (SfM). Classical SfM approaches rely on local feature matches between the images to estimate both the poses and a sparse 3D model of the scene, using bundle adjustment to refine initial pose, intrinsics, and geometry estimates. In order to increase run-time efficiency, recent SfM systems forgo optimization via bundle adjustment. Instead, they train feed-forward (transformer-based) neural networks to directly regress camera parameters and the 3D structure. While orders of magnitude more efficient, such recent works produce significantly less accurate estimates. To stimulate research on developing SfM approaches that are both efficient \emph{and} effective, this paper develops a benchmark focused on SfM for novel view synthesis. Using existing datasets and two simple strategies for making the reconstruction process more efficient, we show that: (1) simply using fewer features already significantly accelerates classical SfM methods while maintaining high pose accuracy. (2) using feed-forward networks to obtain initial estimates and refining them using classical SfM techniques leads to the best efficiency-effectiveness trade-off. We will make our benchmark and code publicly available.
Benchmarking the Effects of Object Pose Estimation and Reconstruction on Robotic Grasping Success
Feb 19, 20263D reconstruction serves as the foundational layer for numerous robotic perception tasks, including 6D object pose estimation and grasp pose generation. Modern 3D reconstruction methods for objects can produce visually and geometrically impressive meshes from multi-view images, yet standard geometric evaluations do not reflect how reconstruction quality influences downstream tasks such as robotic manipulation performance. This paper addresses this gap by introducing a large-scale, physics-based benchmark that evaluates 6D pose estimators and 3D mesh models based on their functional efficacy in grasping. We analyze the impact of model fidelity by generating grasps on various reconstructed 3D meshes and executing them on the ground-truth model, simulating how grasp poses generated with an imperfect model affect interaction with the real object. This assesses the combined impact of pose error, grasp robustness, and geometric inaccuracies from 3D reconstruction. Our results show that reconstruction artifacts significantly decrease the number of grasp pose candidates but have a negligible effect on grasping performance given an accurately estimated pose. Our results also reveal that the relationship between grasp success and pose error is dominated by spatial error, and even a simple translation error provides insight into the success of the grasping pose of symmetric objects. This work provides insight into how perception systems relate to object manipulation using robots.
Can we make NeRF-based visual localization privacy-preserving?
Aug 26, 2025Visual localization (VL) is the task of estimating the camera pose in a known scene. VL methods, a.o., can be distinguished based on how they represent the scene, e.g., explicitly through a (sparse) point cloud or a collection of images or implicitly through the weights of a neural network. Recently, NeRF-based methods have become popular for VL. While NeRFs offer high-quality novel view synthesis, they inadvertently encode fine scene details, raising privacy concerns when deployed in cloud-based localization services as sensitive information could be recovered. In this paper, we tackle this challenge on two ends. We first propose a new protocol to assess privacy-preservation of NeRF-based representations. We show that NeRFs trained with photometric losses store fine-grained details in their geometry representations, making them vulnerable to privacy attacks, even if the head that predicts colors is removed. Second, we propose ppNeSF (Privacy-Preserving Neural Segmentation Field), a NeRF variant trained with segmentation supervision instead of RGB images. These segmentation labels are learned in a self-supervised manner, ensuring they are coarse enough to obscure identifiable scene details while remaining discriminativeness in 3D. The segmentation space of ppNeSF can be used for accurate visual localization, yielding state-of-the-art results.
LODGE: Level-of-Detail Large-Scale Gaussian Splatting with Efficient Rendering
May 29, 2025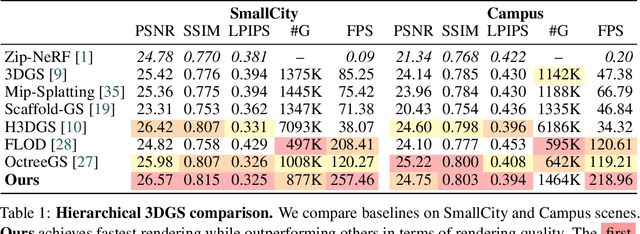
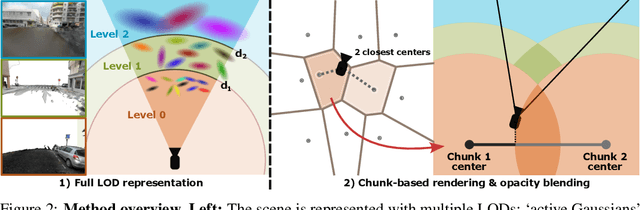
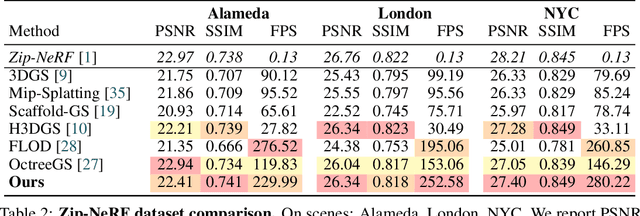
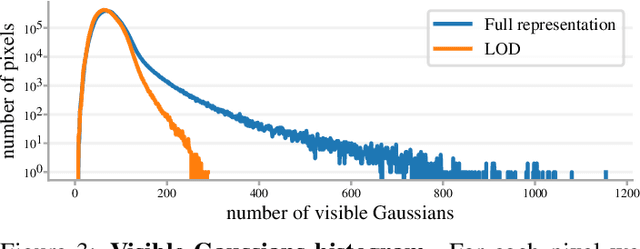
In this work, we present a novel level-of-detail (LOD) method for 3D Gaussian Splatting that enables real-time rendering of large-scale scenes on memory-constrained devices. Our approach introduces a hierarchical LOD representation that iteratively selects optimal subsets of Gaussians based on camera distance, thus largely reducing both rendering time and GPU memory usage. We construct each LOD level by applying a depth-aware 3D smoothing filter, followed by importance-based pruning and fine-tuning to maintain visual fidelity. To further reduce memory overhead, we partition the scene into spatial chunks and dynamically load only relevant Gaussians during rendering, employing an opacity-blending mechanism to avoid visual artifacts at chunk boundaries. Our method achieves state-of-the-art performance on both outdoor (Hierarchical 3DGS) and indoor (Zip-NeRF) datasets, delivering high-quality renderings with reduced latency and memory requirements.
Are Minimal Radial Distortion Solvers Really Necessary for Relative Pose Estimation?
May 01, 2025Estimating the relative pose between two cameras is a fundamental step in many applications such as Structure-from-Motion. The common approach to relative pose estimation is to apply a minimal solver inside a RANSAC loop. Highly efficient solvers exist for pinhole cameras. Yet, (nearly) all cameras exhibit radial distortion. Not modeling radial distortion leads to (significantly) worse results. However, minimal radial distortion solvers are significantly more complex than pinhole solvers, both in terms of run-time and implementation efforts. This paper compares radial distortion solvers with two simple-to-implement approaches that do not use minimal radial distortion solvers: The first approach combines an efficient pinhole solver with sampled radial undistortion parameters, where the sampled parameters are used for undistortion prior to applying the pinhole solver. The second approach uses a state-of-the-art neural network to estimate the distortion parameters rather than sampling them from a set of potential values. Extensive experiments on multiple datasets, and different camera setups, show that complex minimal radial distortion solvers are not necessary in practice. We discuss under which conditions a simple sampling of radial undistortion parameters is preferable over calibrating cameras using a learning-based prior approach. Code and newly created benchmark for relative pose estimation under radial distortion are available at https://github.com/kocurvik/rdnet.
Large-scale visual SLAM for in-the-wild videos
Apr 29, 2025Accurate and robust 3D scene reconstruction from casual, in-the-wild videos can significantly simplify robot deployment to new environments. However, reliable camera pose estimation and scene reconstruction from such unconstrained videos remains an open challenge. Existing visual-only SLAM methods perform well on benchmark datasets but struggle with real-world footage which often exhibits uncontrolled motion including rapid rotations and pure forward movements, textureless regions, and dynamic objects. We analyze the limitations of current methods and introduce a robust pipeline designed to improve 3D reconstruction from casual videos. We build upon recent deep visual odometry methods but increase robustness in several ways. Camera intrinsics are automatically recovered from the first few frames using structure-from-motion. Dynamic objects and less-constrained areas are masked with a predictive model. Additionally, we leverage monocular depth estimates to regularize bundle adjustment, mitigating errors in low-parallax situations. Finally, we integrate place recognition and loop closure to reduce long-term drift and refine both intrinsics and pose estimates through global bundle adjustment. We demonstrate large-scale contiguous 3D models from several online videos in various environments. In contrast, baseline methods typically produce locally inconsistent results at several points, producing separate segments or distorted maps. In lieu of ground-truth pose data, we evaluate map consistency, execution time and visual accuracy of re-rendered NeRF models. Our proposed system establishes a new baseline for visual reconstruction from casual uncontrolled videos found online, demonstrating more consistent reconstructions over longer sequences of in-the-wild videos than previously achieved.
A Guide to Structureless Visual Localization
Apr 24, 2025Visual localization algorithms, i.e., methods that estimate the camera pose of a query image in a known scene, are core components of many applications, including self-driving cars and augmented / mixed reality systems. State-of-the-art visual localization algorithms are structure-based, i.e., they store a 3D model of the scene and use 2D-3D correspondences between the query image and 3D points in the model for camera pose estimation. While such approaches are highly accurate, they are also rather inflexible when it comes to adjusting the underlying 3D model after changes in the scene. Structureless localization approaches represent the scene as a database of images with known poses and thus offer a much more flexible representation that can be easily updated by adding or removing images. Although there is a large amount of literature on structure-based approaches, there is significantly less work on structureless methods. Hence, this paper is dedicated to providing the, to the best of our knowledge, first comprehensive discussion and comparison of structureless methods. Extensive experiments show that approaches that use a higher degree of classical geometric reasoning generally achieve higher pose accuracy. In particular, approaches based on classical absolute or semi-generalized relative pose estimation outperform very recent methods based on pose regression by a wide margin. Compared with state-of-the-art structure-based approaches, the flexibility of structureless methods comes at the cost of (slightly) lower pose accuracy, indicating an interesting direction for future work.
Fixing the Scale and Shift in Monocular Depth For Camera Pose Estimation
Jan 13, 2025



Recent advances in monocular depth prediction have led to significantly improved depth prediction accuracy. In turn, this enables various applications to use such depth predictions. In this paper, we propose a novel framework for estimating the relative pose between two cameras from point correspondences with associated monocular depths. Since depth predictions are typically defined up to an unknown scale and shift parameter, our solvers jointly estimate both scale and shift parameters together with the camera pose. We derive efficient solvers for three cases: (1) two calibrated cameras, (2) two uncalibrated cameras with an unknown but shared focal length, and (3) two uncalibrated cameras with unknown and different focal lengths. Experiments on synthetic and real data, including experiments with depth maps estimated by 11 different depth predictors, show the practical viability of our solvers. Compared to prior work, our solvers achieve state-of-the-art results on two large-scale, real-world datasets. The source code is available at https://github.com/yaqding/pose_monodepth