 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDepth2Pose: A Pose-Based Benchmark for Monocular Depth Estimation without Ground-Truth Depth
May 19, 2026Monocular depth estimation has improved significantly in recent years, driven by increasingly powerful models and large-scale training data. Predicted depth is increasingly used as an input signal for downstream tasks such as Structure-from-Motion (SfM), visual localization, and SLAM. However, monocular depth estimators (MDEs) are still primarily evaluated in terms of depth accuracy. Standard metrics aggregate errors globally and may not reflect the usefulness of depth for downstream geometric tasks. We therefore propose Depth2Pose, a framework for evaluating MDEs in the context of downstream tasks. By combining depth predictions with feature correspondences in depth-aware geometric solvers, we use relative camera pose estimation accuracy as a task-driven proxy for depth quality. Traditional benchmarks require dense ground truth in the form of per-pixel depth, which is expensive to obtain. In contrast, our formulation requires only camera poses, which can be estimated efficiently, e.g., using Structure-from-Motion pipelines. As a result, our framework can be applied to scenes where ground-truth depth is difficult to obtain, for example due to large scene scale or heavy occlusions (e.g., vegetated environments). Leveraging this, we introduce the D2P dataset, which contains challenging scenes outside the distribution of commonly used training data. We show that methods performing well under standard depth error metrics on existing benchmarks also perform well under our pose-based metric when evaluated on the same datasets, but do not necessarily generalize to our more challenging dataset. Finally, we provide a simple and extensible evaluation framework. The dataset and code are available at kocurvik.github.io/depth2pose.
Pointing-Based Object Recognition
Mar 16, 2026This paper presents a comprehensive pipeline for recognizing objects targeted by human pointing gestures using RGB images. As human-robot interaction moves toward more intuitive interfaces, the ability to identify targets of non-verbal communication becomes crucial. Our proposed system integrates several existing state-of-the-art methods, including object detection, body pose estimation, monocular depth estimation, and vision-language models. We evaluate the impact of 3D spatial information reconstructed from a single image and the utility of image captioning models in correcting classification errors. Experimental results on a custom dataset show that incorporating depth information significantly improves target identification, especially in complex scenes with overlapping objects. The modularity of the approach allows for deployment in environments where specialized depth sensors are unavailable.
Detecting 3D Line Segments for 6DoF Pose Estimation with Limited Data
Jan 17, 2026The task of 6DoF object pose estimation is one of the fundamental problems of 3D vision with many practical applications such as industrial automation. Traditional deep learning approaches for this task often require extensive training data or CAD models, limiting their application in real-world industrial settings where data is scarce and object instances vary. We propose a novel method for 6DoF pose estimation focused specifically on bins used in industrial settings. We exploit the cuboid geometry of bins by first detecting intermediate 3D line segments corresponding to their top edges. Our approach extends the 2D line segment detection network LeTR to operate on structured point cloud data. The detected 3D line segments are then processed using a simple geometric procedure to robustly determine the bin's 6DoF pose. To evaluate our method, we extend an existing dataset with a newly collected and annotated dataset, which we make publicly available. We show that incorporating synthetic training data significantly improves pose estimation accuracy on real scans. Moreover, we show that our method significantly outperforms current state-of-the-art 6DoF pose estimation methods in terms of the pose accuracy (3 cm translation error, 8.2$^\circ$ rotation error) while not requiring instance-specific CAD models during inference.
Billboard in Focus: Estimating Driver Gaze Duration from a Single Image
Jan 11, 2026Roadside billboards represent a central element of outdoor advertising, yet their presence may contribute to driver distraction and accident risk. This study introduces a fully automated pipeline for billboard detection and driver gaze duration estimation, aiming to evaluate billboard relevance without reliance on manual annotations or eye-tracking devices. Our pipeline operates in two stages: (1) a YOLO-based object detection model trained on Mapillary Vistas and fine-tuned on BillboardLamac images achieved 94% mAP@50 in the billboard detection task (2) a classifier based on the detected bounding box positions and DINOv2 features. The proposed pipeline enables estimation of billboard driver gaze duration from individual frames. We show that our method is able to achieve 68.1% accuracy on BillboardLamac when considering individual frames. These results are further validated using images collected from Google Street View.
Efficient Vision-based Vehicle Speed Estimation
May 02, 2025This paper presents a computationally efficient method for vehicle speed estimation from traffic camera footage. Building upon previous work that utilizes 3D bounding boxes derived from 2D detections and vanishing point geometry, we introduce several improvements to enhance real-time performance. We evaluate our method in several variants on the BrnoCompSpeed dataset in terms of vehicle detection and speed estimation accuracy. Our extensive evaluation across various hardware platforms, including edge devices, demonstrates significant gains in frames per second (FPS) compared to the prior state-of-the-art, while maintaining comparable or improved speed estimation accuracy. We analyze the trade-off between accuracy and computational cost, showing that smaller models utilizing post-training quantization offer the best balance for real-world deployment. Our best performing model beats previous state-of-the-art in terms of median vehicle speed estimation error (0.58 km/h vs. 0.60 km/h), detection precision (91.02% vs 87.08%) and recall (91.14% vs. 83.32%) while also being 5.5 times faster.
Are Minimal Radial Distortion Solvers Really Necessary for Relative Pose Estimation?
May 01, 2025Estimating the relative pose between two cameras is a fundamental step in many applications such as Structure-from-Motion. The common approach to relative pose estimation is to apply a minimal solver inside a RANSAC loop. Highly efficient solvers exist for pinhole cameras. Yet, (nearly) all cameras exhibit radial distortion. Not modeling radial distortion leads to (significantly) worse results. However, minimal radial distortion solvers are significantly more complex than pinhole solvers, both in terms of run-time and implementation efforts. This paper compares radial distortion solvers with two simple-to-implement approaches that do not use minimal radial distortion solvers: The first approach combines an efficient pinhole solver with sampled radial undistortion parameters, where the sampled parameters are used for undistortion prior to applying the pinhole solver. The second approach uses a state-of-the-art neural network to estimate the distortion parameters rather than sampling them from a set of potential values. Extensive experiments on multiple datasets, and different camera setups, show that complex minimal radial distortion solvers are not necessary in practice. We discuss under which conditions a simple sampling of radial undistortion parameters is preferable over calibrating cameras using a learning-based prior approach. Code and newly created benchmark for relative pose estimation under radial distortion are available at https://github.com/kocurvik/rdnet.
Three-view Focal Length Recovery From Homographies
Jan 13, 2025



In this paper, we propose a novel approach for recovering focal lengths from three-view homographies. By examining the consistency of normal vectors between two homographies, we derive new explicit constraints between the focal lengths and homographies using an elimination technique. We demonstrate that three-view homographies provide two additional constraints, enabling the recovery of one or two focal lengths. We discuss four possible cases, including three cameras having an unknown equal focal length, three cameras having two different unknown focal lengths, three cameras where one focal length is known, and the other two cameras have equal or different unknown focal lengths. All the problems can be converted into solving polynomials in one or two unknowns, which can be efficiently solved using Sturm sequence or hidden variable technique. Evaluation using both synthetic and real data shows that the proposed solvers are both faster and more accurate than methods relying on existing two-view solvers. The code and data are available on https://github.com/kocurvik/hf
Fixing the Scale and Shift in Monocular Depth For Camera Pose Estimation
Jan 13, 2025



Recent advances in monocular depth prediction have led to significantly improved depth prediction accuracy. In turn, this enables various applications to use such depth predictions. In this paper, we propose a novel framework for estimating the relative pose between two cameras from point correspondences with associated monocular depths. Since depth predictions are typically defined up to an unknown scale and shift parameter, our solvers jointly estimate both scale and shift parameters together with the camera pose. We derive efficient solvers for three cases: (1) two calibrated cameras, (2) two uncalibrated cameras with an unknown but shared focal length, and (3) two uncalibrated cameras with unknown and different focal lengths. Experiments on synthetic and real data, including experiments with depth maps estimated by 11 different depth predictors, show the practical viability of our solvers. Compared to prior work, our solvers achieve state-of-the-art results on two large-scale, real-world datasets. The source code is available at https://github.com/yaqding/pose_monodepth
On Representation of 3D Rotation in the Context of Deep Learning
Oct 15, 2024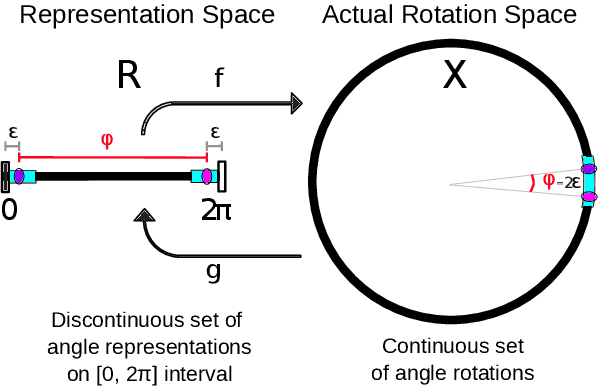

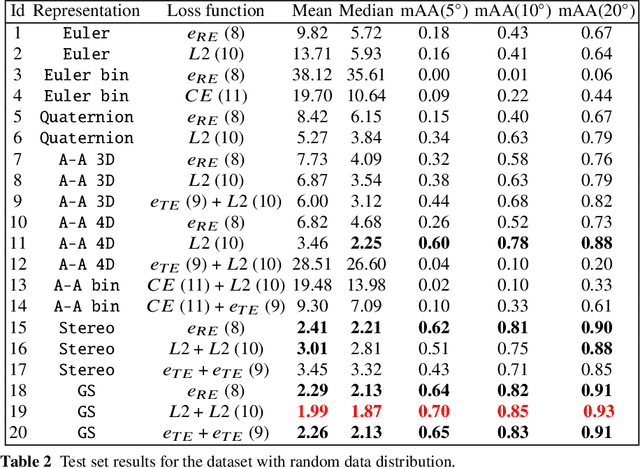
This paper investigates various methods of representing 3D rotations and their impact on the learning process of deep neural networks. We evaluated the performance of ResNet18 networks for 3D rotation estimation using several rotation representations and loss functions on both synthetic and real data. The real datasets contained 3D scans of industrial bins, while the synthetic datasets included views of a simple asymmetric object rendered under different rotations. On synthetic data, we also assessed the effects of different rotation distributions within the training and test sets, as well as the impact of the object's texture. In line with previous research, we found that networks using the continuous 5D and 6D representations performed better than the discontinuous ones.
Are Minimal Radial Distortion Solvers Necessary for Relative Pose Estimation?
Oct 08, 2024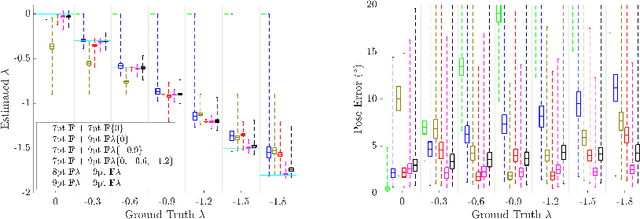
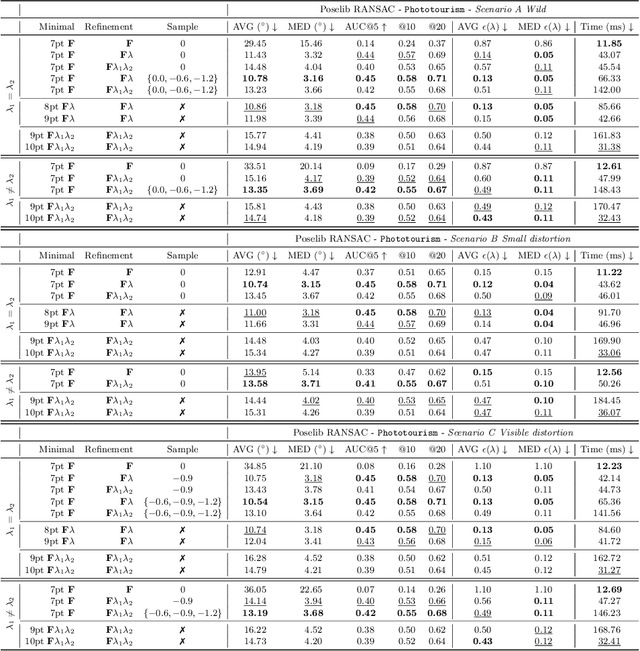
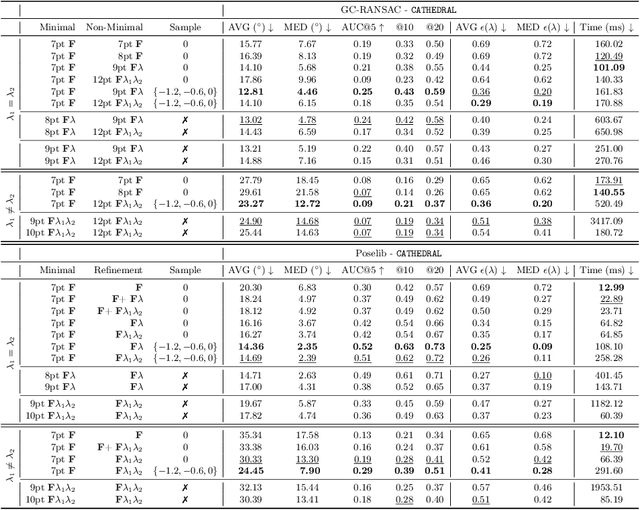
Estimating the relative pose between two cameras is a fundamental step in many applications such as Structure-from-Motion. The common approach to relative pose estimation is to apply a minimal solver inside a RANSAC loop. Highly efficient solvers exist for pinhole cameras. Yet, (nearly) all cameras exhibit radial distortion. Not modeling radial distortion leads to (significantly) worse results. However, minimal radial distortion solvers are significantly more complex than pinhole solvers, both in terms of run-time and implementation efforts. This paper compares radial distortion solvers with a simple-to-implement approach that combines an efficient pinhole solver with sampled radial distortion parameters. Extensive experiments on multiple datasets and RANSAC variants show that this simple approach performs similarly or better than the most accurate minimal distortion solvers at faster run-times while being significantly more accurate than faster non-minimal solvers. We clearly show that complex radial distortion solvers are not necessary in practice. Code and benchmark are available at https://github.com/kocurvik/rd.