 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePointing-Guided Target Estimation via Transformer-Based Attention
Sep 05, 2025Deictic gestures, like pointing, are a fundamental form of non-verbal communication, enabling humans to direct attention to specific objects or locations. This capability is essential in Human-Robot Interaction (HRI), where robots should be able to predict human intent and anticipate appropriate responses. In this work, we propose the Multi-Modality Inter-TransFormer (MM-ITF), a modular architecture to predict objects in a controlled tabletop scenario with the NICOL robot, where humans indicate targets through natural pointing gestures. Leveraging inter-modality attention, MM-ITF maps 2D pointing gestures to object locations, assigns a likelihood score to each, and identifies the most likely target. Our results demonstrate that the method can accurately predict the intended object using monocular RGB data, thus enabling intuitive and accessible human-robot collaboration. To evaluate the performance, we introduce a patch confusion matrix, providing insights into the model's predictions across candidate object locations. Code available at: https://github.com/lucamuellercode/MMITF.
Demo: TOSense -- What Did You Just Agree to?
Aug 01, 2025Online services often require users to agree to lengthy and obscure Terms of Service (ToS), leading to information asymmetry and legal risks. This paper proposes TOSense-a Chrome extension that allows users to ask questions about ToS in natural language and get concise answers in real time. The system combines (i) a crawler "tos-crawl" that automatically extracts ToS content, and (ii) a lightweight large language model pipeline: MiniLM for semantic retrieval and BART-encoder for answer relevance verification. To avoid expensive manual annotation, we present a novel Question Answering Evaluation Pipeline (QEP) that generates synthetic questions and verifies the correctness of answers using clustered topic matching. Experiments on five major platforms, Apple, Google, X (formerly Twitter), Microsoft, and Netflix, show the effectiveness of TOSense (with up to 44.5% accuracy) across varying number of topic clusters. During the demonstration, we will showcase TOSense in action. Attendees will be able to experience seamless extraction, interactive question answering, and instant indexing of new sites.
Shaken, Not Stirred: A Novel Dataset for Visual Understanding of Glasses in Human-Robot Bartending Tasks
Mar 06, 2025



Datasets for object detection often do not account for enough variety of glasses, due to their transparent and reflective properties. Specifically, open-vocabulary object detectors, widely used in embodied robotic agents, fail to distinguish subclasses of glasses. This scientific gap poses an issue to robotic applications that suffer from accumulating errors between detection, planning, and action execution. The paper introduces a novel method for the acquisition of real-world data from RGB-D sensors that minimizes human effort. We propose an auto-labeling pipeline that generates labels for all the acquired frames based on the depth measurements. We provide a novel real-world glass object dataset that was collected on the Neuro-Inspired COLlaborator (NICOL), a humanoid robot platform. The data set consists of 7850 images recorded from five different cameras. We show that our trained baseline model outperforms state-of-the-art open-vocabulary approaches. In addition, we deploy our baseline model in an embodied agent approach to the NICOL platform, on which it achieves a success rate of 81% in a human-robot bartending scenario.
On Representation of 3D Rotation in the Context of Deep Learning
Oct 15, 2024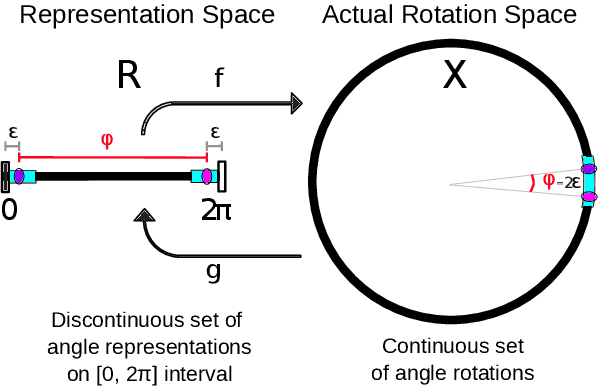

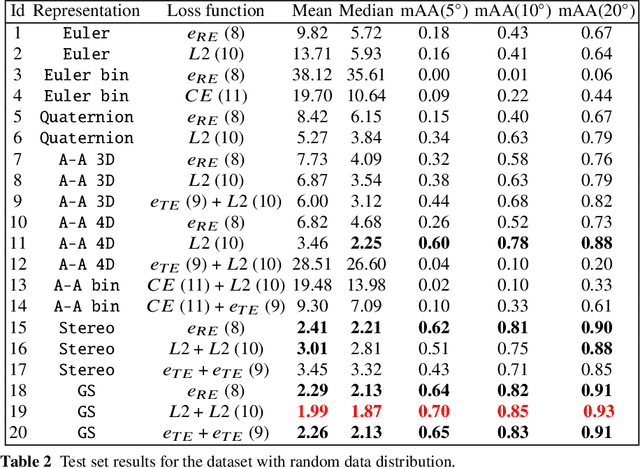
This paper investigates various methods of representing 3D rotations and their impact on the learning process of deep neural networks. We evaluated the performance of ResNet18 networks for 3D rotation estimation using several rotation representations and loss functions on both synthetic and real data. The real datasets contained 3D scans of industrial bins, while the synthetic datasets included views of a simple asymmetric object rendered under different rotations. On synthetic data, we also assessed the effects of different rotation distributions within the training and test sets, as well as the impact of the object's texture. In line with previous research, we found that networks using the continuous 5D and 6D representations performed better than the discontinuous ones.
Adversarially Guided Stateful Defense Against Backdoor Attacks in Federated Deep Learning
Oct 15, 2024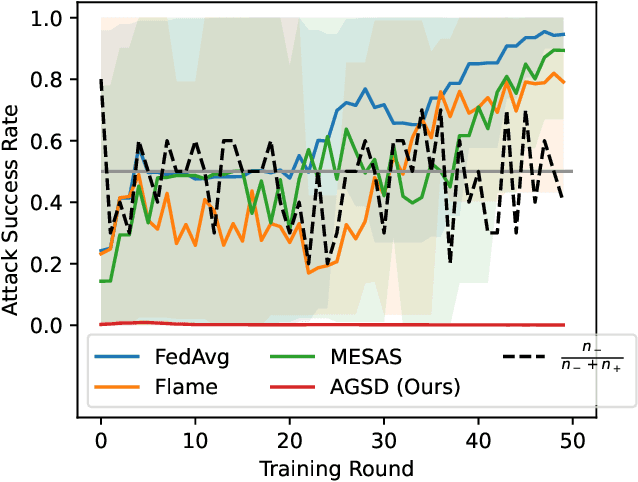
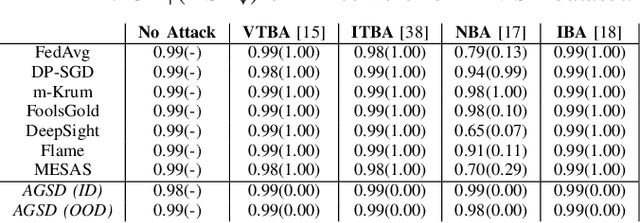
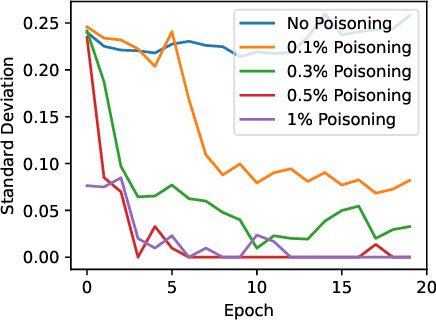
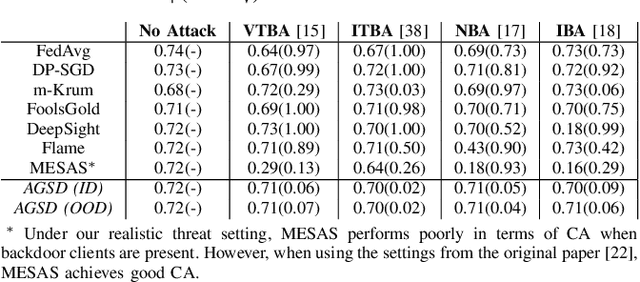
Recent works have shown that Federated Learning (FL) is vulnerable to backdoor attacks. Existing defenses cluster submitted updates from clients and select the best cluster for aggregation. However, they often rely on unrealistic assumptions regarding client submissions and sampled clients population while choosing the best cluster. We show that in realistic FL settings, state-of-the-art (SOTA) defenses struggle to perform well against backdoor attacks in FL. To address this, we highlight that backdoored submissions are adversarially biased and overconfident compared to clean submissions. We, therefore, propose an Adversarially Guided Stateful Defense (AGSD) against backdoor attacks on Deep Neural Networks (DNNs) in FL scenarios. AGSD employs adversarial perturbations to a small held-out dataset to compute a novel metric, called the trust index, that guides the cluster selection without relying on any unrealistic assumptions regarding client submissions. Moreover, AGSD maintains a trust state history of each client that adaptively penalizes backdoored clients and rewards clean clients. In realistic FL settings, where SOTA defenses mostly fail to resist attacks, AGSD mostly outperforms all SOTA defenses with minimal drop in clean accuracy (5% in the worst-case compared to best accuracy) even when (a) given a very small held-out dataset -- typically AGSD assumes 50 samples (<= 0.1% of the training data) and (b) no heldout dataset is available, and out-of-distribution data is used instead. For reproducibility, our code will be openly available at: https://github.com/hassanalikhatim/AGSD.
Robots Can Multitask Too: Integrating a Memory Architecture and LLMs for Enhanced Cross-Task Robot Action Generation
Jul 18, 2024Large Language Models (LLMs) have been recently used in robot applications for grounding LLM common-sense reasoning with the robot's perception and physical abilities. In humanoid robots, memory also plays a critical role in fostering real-world embodiment and facilitating long-term interactive capabilities, especially in multi-task setups where the robot must remember previous task states, environment states, and executed actions. In this paper, we address incorporating memory processes with LLMs for generating cross-task robot actions, while the robot effectively switches between tasks. Our proposed dual-layered architecture features two LLMs, utilizing their complementary skills of reasoning and following instructions, combined with a memory model inspired by human cognition. Our results show a significant improvement in performance over a baseline of five robotic tasks, demonstrating the potential of integrating memory with LLMs for combining the robot's action and perception for adaptive task execution.
When Robots Get Chatty: Grounding Multimodal Human-Robot Conversation and Collaboration
Jun 29, 2024
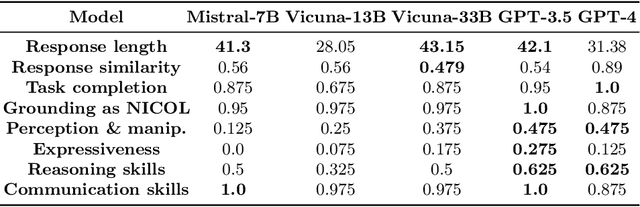
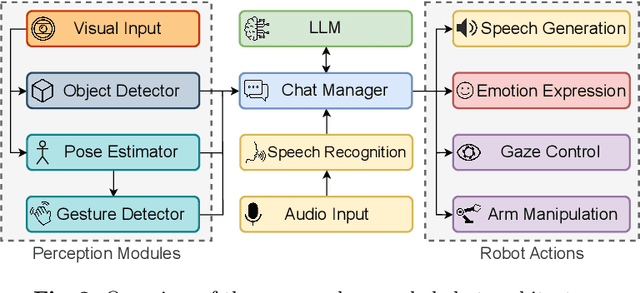
We investigate the use of Large Language Models (LLMs) to equip neural robotic agents with human-like social and cognitive competencies, for the purpose of open-ended human-robot conversation and collaboration. We introduce a modular and extensible methodology for grounding an LLM with the sensory perceptions and capabilities of a physical robot, and integrate multiple deep learning models throughout the architecture in a form of system integration. The integrated models encompass various functions such as speech recognition, speech generation, open-vocabulary object detection, human pose estimation, and gesture detection, with the LLM serving as the central text-based coordinating unit. The qualitative and quantitative results demonstrate the huge potential of LLMs in providing emergent cognition and interactive language-oriented control of robots in a natural and social manner.
Comparing Apples to Oranges: LLM-powered Multimodal Intention Prediction in an Object Categorization Task
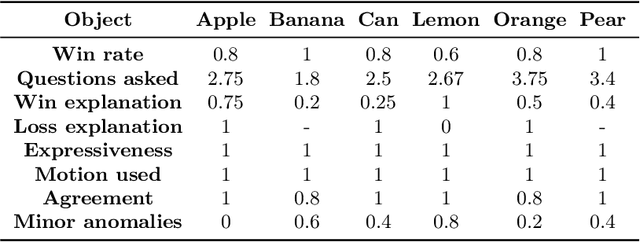
Apr 12, 2024Intention-based Human-Robot Interaction (HRI) systems allow robots to perceive and interpret user actions to proactively interact with humans and adapt to their behavior. Therefore, intention prediction is pivotal in creating a natural interactive collaboration between humans and robots. In this paper, we examine the use of Large Language Models (LLMs) for inferring human intention during a collaborative object categorization task with a physical robot. We introduce a hierarchical approach for interpreting user non-verbal cues, like hand gestures, body poses, and facial expressions and combining them with environment states and user verbal cues captured using an existing Automatic Speech Recognition (ASR) system. Our evaluation demonstrates the potential of LLMs to interpret non-verbal cues and to combine them with their context-understanding capabilities and real-world knowledge to support intention prediction during human-robot interaction.
Adversarial Machine Learning for Social Good: Reframing the Adversary as an Ally
Oct 05, 2023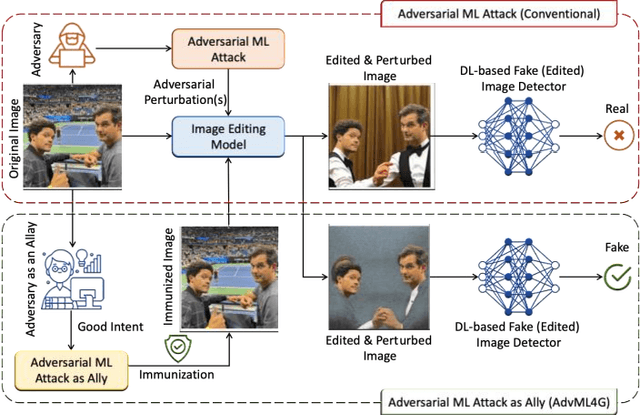
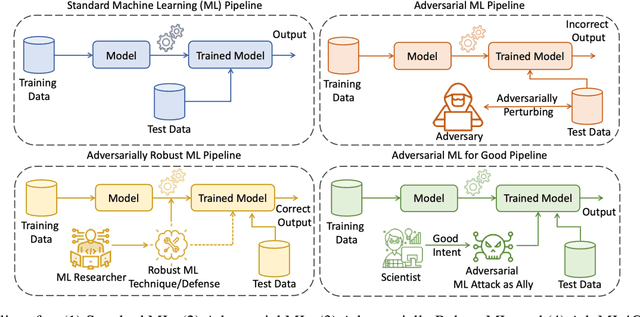
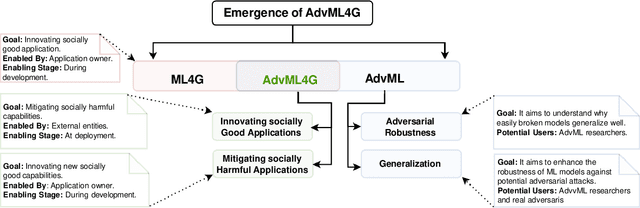
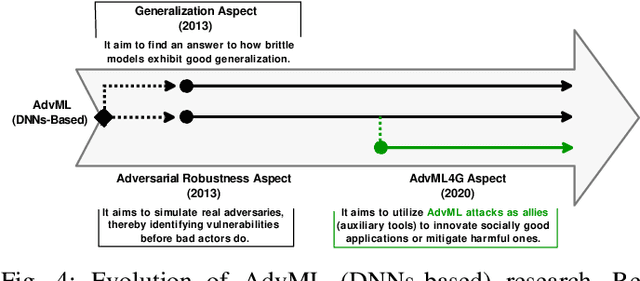
Deep Neural Networks (DNNs) have been the driving force behind many of the recent advances in machine learning. However, research has shown that DNNs are vulnerable to adversarial examples -- input samples that have been perturbed to force DNN-based models to make errors. As a result, Adversarial Machine Learning (AdvML) has gained a lot of attention, and researchers have investigated these vulnerabilities in various settings and modalities. In addition, DNNs have also been found to incorporate embedded bias and often produce unexplainable predictions, which can result in anti-social AI applications. The emergence of new AI technologies that leverage Large Language Models (LLMs), such as ChatGPT and GPT-4, increases the risk of producing anti-social applications at scale. AdvML for Social Good (AdvML4G) is an emerging field that repurposes the AdvML bug to invent pro-social applications. Regulators, practitioners, and researchers should collaborate to encourage the development of pro-social applications and hinder the development of anti-social ones. In this work, we provide the first comprehensive review of the emerging field of AdvML4G. This paper encompasses a taxonomy that highlights the emergence of AdvML4G, a discussion of the differences and similarities between AdvML4G and AdvML, a taxonomy covering social good-related concepts and aspects, an exploration of the motivations behind the emergence of AdvML4G at the intersection of ML4G and AdvML, and an extensive summary of the works that utilize AdvML4G as an auxiliary tool for innovating pro-social applications. Finally, we elaborate upon various challenges and open research issues that require significant attention from the research community.
R2S100K: Road-Region Segmentation Dataset For Semi-Supervised Autonomous Driving in the Wild
Aug 11, 2023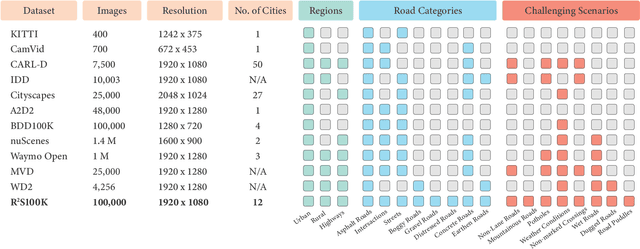
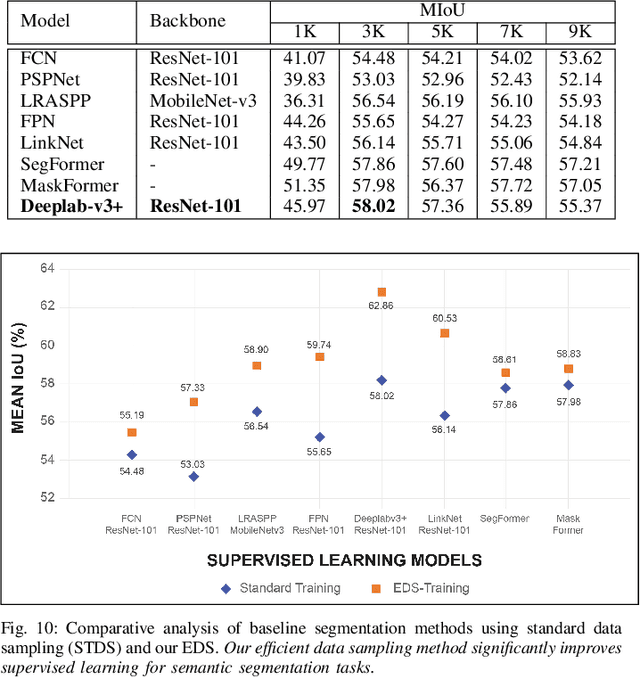


Semantic understanding of roadways is a key enabling factor for safe autonomous driving. However, existing autonomous driving datasets provide well-structured urban roads while ignoring unstructured roadways containing distress, potholes, water puddles, and various kinds of road patches i.e., earthen, gravel etc. To this end, we introduce Road Region Segmentation dataset (R2S100K) -- a large-scale dataset and benchmark for training and evaluation of road segmentation in aforementioned challenging unstructured roadways. R2S100K comprises 100K images extracted from a large and diverse set of video sequences covering more than 1000 KM of roadways. Out of these 100K privacy respecting images, 14,000 images have fine pixel-labeling of road regions, with 86,000 unlabeled images that can be leveraged through semi-supervised learning methods. Alongside, we present an Efficient Data Sampling (EDS) based self-training framework to improve learning by leveraging unlabeled data. Our experimental results demonstrate that the proposed method significantly improves learning methods in generalizability and reduces the labeling cost for semantic segmentation tasks. Our benchmark will be publicly available to facilitate future research at https://r2s100k.github.io/.