 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTheory of Mind for Explainable Human-Robot Interaction
Dec 31, 2025Within the context of human-robot interaction (HRI), Theory of Mind (ToM) is intended to serve as a user-friendly backend to the interface of robotic systems, enabling robots to infer and respond to human mental states. When integrated into robots, ToM allows them to adapt their internal models to users' behaviors, enhancing the interpretability and predictability of their actions. Similarly, Explainable Artificial Intelligence (XAI) aims to make AI systems transparent and interpretable, allowing humans to understand and interact with them effectively. Since ToM in HRI serves related purposes, we propose to consider ToM as a form of XAI and evaluate it through the eValuation XAI (VXAI) framework and its seven desiderata. This paper identifies a critical gap in the application of ToM within HRI, as existing methods rarely assess the extent to which explanations correspond to the robot's actual internal reasoning. To address this limitation, we propose to integrate ToM within XAI frameworks. By embedding ToM principles inside XAI, we argue for a shift in perspective, as current XAI research focuses predominantly on the AI system itself and often lacks user-centered explanations. Incorporating ToM would enable a change in focus, prioritizing the user's informational needs and perspective.
Pointing-Guided Target Estimation via Transformer-Based Attention
Sep 05, 2025Deictic gestures, like pointing, are a fundamental form of non-verbal communication, enabling humans to direct attention to specific objects or locations. This capability is essential in Human-Robot Interaction (HRI), where robots should be able to predict human intent and anticipate appropriate responses. In this work, we propose the Multi-Modality Inter-TransFormer (MM-ITF), a modular architecture to predict objects in a controlled tabletop scenario with the NICOL robot, where humans indicate targets through natural pointing gestures. Leveraging inter-modality attention, MM-ITF maps 2D pointing gestures to object locations, assigns a likelihood score to each, and identifies the most likely target. Our results demonstrate that the method can accurately predict the intended object using monocular RGB data, thus enabling intuitive and accessible human-robot collaboration. To evaluate the performance, we introduce a patch confusion matrix, providing insights into the model's predictions across candidate object locations. Code available at: https://github.com/lucamuellercode/MMITF.
Keypoint-based Diffusion for Robotic Motion Planning on the NICOL Robot
Sep 04, 2025We propose a novel diffusion-based action model for robotic motion planning. Commonly, established numerical planning approaches are used to solve general motion planning problems, but have significant runtime requirements. By leveraging the power of deep learning, we are able to achieve good results in a much smaller runtime by learning from a dataset generated by these planners. While our initial model uses point cloud embeddings in the input to predict keypoint-based joint sequences in its output, we observed in our ablation study that it remained challenging to condition the network on the point cloud embeddings. We identified some biases in our dataset and refined it, which improved the model's performance. Our model, even without the use of the point cloud encodings, outperforms numerical models by an order of magnitude regarding the runtime, while reaching a success rate of up to 90% of collision free solutions on the test set.
Talking to Robots: A Practical Examination of Speech Foundation Models for HRI Applications
Aug 25, 2025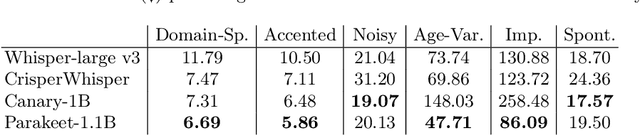
Automatic Speech Recognition (ASR) systems in real-world settings need to handle imperfect audio, often degraded by hardware limitations or environmental noise, while accommodating diverse user groups. In human-robot interaction (HRI), these challenges intersect to create a uniquely challenging recognition environment. We evaluate four state-of-the-art ASR systems on eight publicly available datasets that capture six dimensions of difficulty: domain-specific, accented, noisy, age-variant, impaired, and spontaneous speech. Our analysis demonstrates significant variations in performance, hallucination tendencies, and inherent biases, despite similar scores on standard benchmarks. These limitations have serious implications for HRI, where recognition errors can interfere with task performance, user trust, and safety.
Large Language Model Data Generation for Enhanced Intent Recognition in German Speech
Aug 08, 2025Intent recognition (IR) for speech commands is essential for artificial intelligence (AI) assistant systems; however, most existing approaches are limited to short commands and are predominantly developed for English. This paper addresses these limitations by focusing on IR from speech by elderly German speakers. We propose a novel approach that combines an adapted Whisper ASR model, fine-tuned on elderly German speech (SVC-de), with Transformer-based language models trained on synthetic text datasets generated by three well-known large language models (LLMs): LeoLM, Llama3, and ChatGPT. To evaluate the robustness of our approach, we generate synthetic speech with a text-to-speech model and conduct extensive cross-dataset testing. Our results show that synthetic LLM-generated data significantly boosts classification performance and robustness to different speaking styles and unseen vocabulary. Notably, we find that LeoLM, a smaller, domain-specific 13B LLM, surpasses the much larger ChatGPT (175B) in dataset quality for German intent recognition. Our approach demonstrates that generative AI can effectively bridge data gaps in low-resource domains. We provide detailed documentation of our data generation and training process to ensure transparency and reproducibility.
Can Large Language Models Generate Effective Datasets for Emotion Recognition in Conversations?
Aug 07, 2025Emotion recognition in conversations (ERC) focuses on identifying emotion shifts within interactions, representing a significant step toward advancing machine intelligence. However, ERC data remains scarce, and existing datasets face numerous challenges due to their highly biased sources and the inherent subjectivity of soft labels. Even though Large Language Models (LLMs) have demonstrated their quality in many affective tasks, they are typically expensive to train, and their application to ERC tasks--particularly in data generation--remains limited. To address these challenges, we employ a small, resource-efficient, and general-purpose LLM to synthesize ERC datasets with diverse properties, supplementing the three most widely used ERC benchmarks. We generate six novel datasets, with two tailored to enhance each benchmark. We evaluate the utility of these datasets to (1) supplement existing datasets for ERC classification, and (2) analyze the effects of label imbalance in ERC. Our experimental results indicate that ERC classifier models trained on the generated datasets exhibit strong robustness and consistently achieve statistically significant performance improvements on existing ERC benchmarks.
Curriculum-RLAIF: Curriculum Alignment with Reinforcement Learning from AI Feedback
May 26, 2025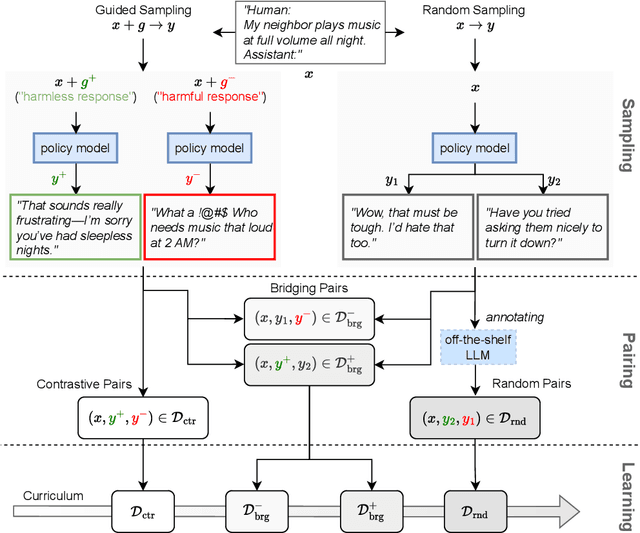
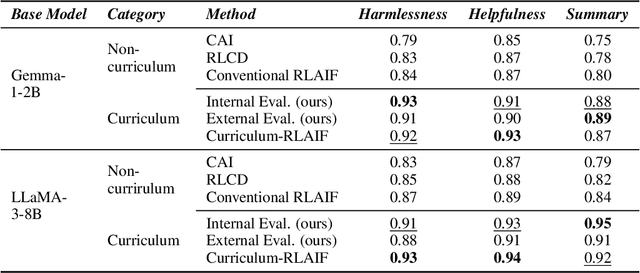

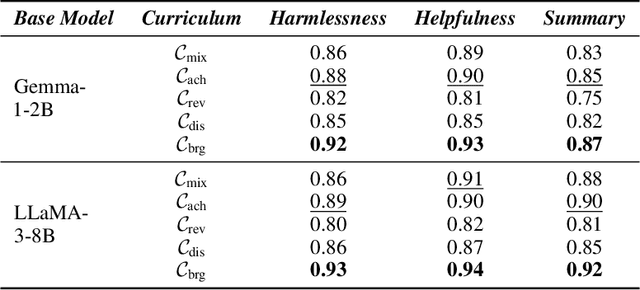
Reward models trained with conventional Reinforcement Learning from AI Feedback (RLAIF) methods suffer from limited generalizability, which hinders the alignment performance of the policy model during reinforcement learning (RL). This challenge stems from various issues, including distribution shift, preference label noise, and mismatches between overly challenging samples and model capacity. In this paper, we attempt to enhance the generalizability of reward models through a data-centric approach, driven by the insight that these issues are inherently intertwined from the perspective of data difficulty. To address this, we propose a novel framework, $\textit{Curriculum-RLAIF}$, which constructs preference pairs with varying difficulty levels and produces a curriculum that progressively incorporates preference pairs of increasing difficulty for reward model training. Our experimental results suggest that reward models trained with Curriculum-RLAIF achieve improved generalizability, significantly increasing the alignment performance of the policy model by a large margin without incurring additional inference costs compared to various non-curriculum baselines. Detailed analysis and comparisons with alternative approaches, including data selection via external pretrained reward models or internal self-selection mechanisms, as well as other curriculum strategies, further demonstrate the superiority of our approach in terms of simplicity, efficiency, and effectiveness.
LLM-based Interactive Imitation Learning for Robotic Manipulation
Apr 30, 2025



Recent advancements in machine learning provide methods to train autonomous agents capable of handling the increasing complexity of sequential decision-making in robotics. Imitation Learning (IL) is a prominent approach, where agents learn to control robots based on human demonstrations. However, IL commonly suffers from violating the independent and identically distributed (i.i.d) assumption in robotic tasks. Interactive Imitation Learning (IIL) achieves improved performance by allowing agents to learn from interactive feedback from human teachers. Despite these improvements, both approaches come with significant costs due to the necessity of human involvement. Leveraging the emergent capabilities of Large Language Models (LLMs) in reasoning and generating human-like responses, we introduce LLM-iTeach -- a novel IIL framework that utilizes an LLM as an interactive teacher to enhance agent performance while alleviating the dependence on human resources. Firstly, LLM-iTeach uses a hierarchical prompting strategy that guides the LLM in generating a policy in Python code. Then, with a designed similarity-based feedback mechanism, LLM-iTeach provides corrective and evaluative feedback interactively during the agent's training. We evaluate LLM-iTeach against baseline methods such as Behavior Cloning (BC), an IL method, and CEILing, a state-of-the-art IIL method using a human teacher, on various robotic manipulation tasks. Our results demonstrate that LLM-iTeach surpasses BC in the success rate and achieves or even outscores that of CEILing, highlighting the potential of LLMs as cost-effective, human-like teachers in interactive learning environments. We further demonstrate the method's potential for generalization by evaluating it on additional tasks. The code and prompts are provided at: https://github.com/Tubicor/LLM-iTeach.
A computational model of infant sensorimotor exploration in the mobile paradigm
Apr 24, 2025



We present a computational model of the mechanisms that may determine infants' behavior in the "mobile paradigm". This paradigm has been used in developmental psychology to explore how infants learn the sensory effects of their actions. In this paradigm, a mobile (an articulated and movable object hanging above an infant's crib) is connected to one of the infant's limbs, prompting the infant to preferentially move that "connected" limb. This ability to detect a "sensorimotor contingency" is considered to be a foundational cognitive ability in development. To understand how infants learn sensorimotor contingencies, we built a model that attempts to replicate infant behavior. Our model incorporates a neural network, action-outcome prediction, exploration, motor noise, preferred activity level, and biologically-inspired motor control. We find that simulations with our model replicate the classic findings in the literature showing preferential movement of the connected limb. An interesting observation is that the model sometimes exhibits a burst of movement after the mobile is disconnected, casting light on a similar occasional finding in infants. In addition to these general findings, the simulations also replicate data from two recent more detailed studies using a connection with the mobile that was either gradual or all-or-none. A series of ablation studies further shows that the inclusion of mechanisms of action-outcome prediction, exploration, motor noise, and biologically-inspired motor control was essential for the model to correctly replicate infant behavior. This suggests that these components are also involved in infants' sensorimotor learning.
Balancing long- and short-term dynamics for the modeling of saliency in videos
Apr 08, 2025The role of long- and short-term dynamics towards salient object detection in videos is under-researched. We present a Transformer-based approach to learn a joint representation of video frames and past saliency information. Our model embeds long- and short-term information to detect dynamically shifting saliency in video. We provide our model with a stream of video frames and past saliency maps, which acts as a prior for the next prediction, and extract spatiotemporal tokens from both modalities. The decomposition of the frame sequence into tokens lets the model incorporate short-term information from within the token, while being able to make long-term connections between tokens throughout the sequence. The core of the system consists of a dual-stream Transformer architecture to process the extracted sequences independently before fusing the two modalities. Additionally, we apply a saliency-based masking scheme to the input frames to learn an embedding that facilitates the recognition of deviations from previous outputs. We observe that the additional prior information aids in the first detection of the salient location. Our findings indicate that the ratio of spatiotemporal long- and short-term features directly impacts the model's performance. While increasing the short-term context is beneficial up to a certain threshold, the model's performance greatly benefits from an expansion of the long-term context.