 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Detection of Defects on Metal Surfaces using Vision Transformers
Oct 06, 2024



Metal manufacturing often results in the production of defective products, leading to operational challenges. Since traditional manual inspection is time-consuming and resource-intensive, automatic solutions are needed. The study utilizes deep learning techniques to develop a model for detecting metal surface defects using Vision Transformers (ViTs). The proposed model focuses on the classification and localization of defects using a ViT for feature extraction. The architecture branches into two paths: classification and localization. The model must approach high classification accuracy while keeping the Mean Square Error (MSE) and Mean Absolute Error (MAE) as low as possible in the localization process. Experimental results show that it can be utilized in the process of automated defects detection, improve operational efficiency, and reduce errors in metal manufacturing.
QT-TDM: Planning with Transformer Dynamics Model and Autoregressive Q-Learning
Jul 26, 2024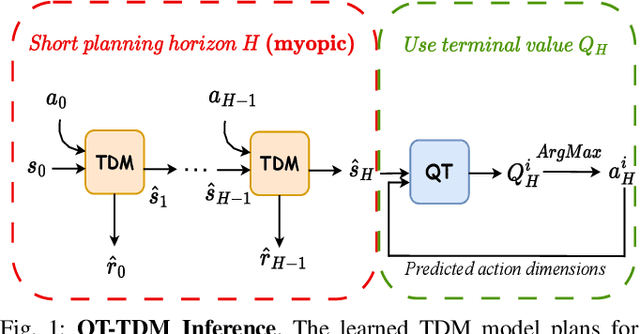
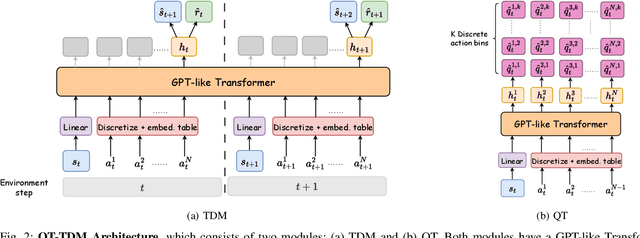

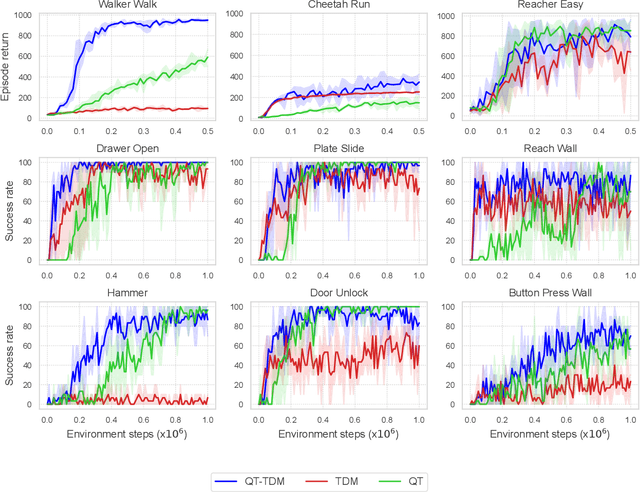
Inspired by the success of the Transformer architecture in natural language processing and computer vision, we investigate the use of Transformers in Reinforcement Learning (RL), specifically in modeling the environment's dynamics using Transformer Dynamics Models (TDMs). We evaluate the capabilities of TDMs for continuous control in real-time planning scenarios with Model Predictive Control (MPC). While Transformers excel in long-horizon prediction, their tokenization mechanism and autoregressive nature lead to costly planning over long horizons, especially as the environment's dimensionality increases. To alleviate this issue, we use a TDM for short-term planning, and learn an autoregressive discrete Q-function using a separate Q-Transformer (QT) model to estimate a long-term return beyond the short-horizon planning. Our proposed method, QT-TDM, integrates the robust predictive capabilities of Transformers as dynamics models with the efficacy of a model-free Q-Transformer to mitigate the computational burden associated with real-time planning. Experiments in diverse state-based continuous control tasks show that QT-TDM is superior in performance and sample efficiency compared to existing Transformer-based RL models while achieving fast and computationally efficient inference.
Model Predictive Control with Self-supervised Representation Learning
Apr 14, 2023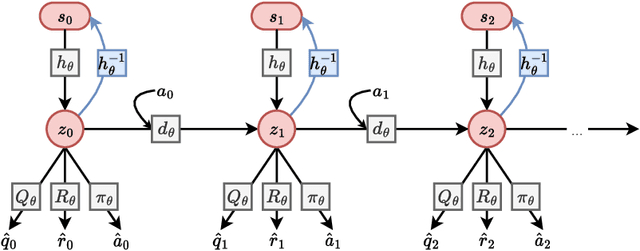
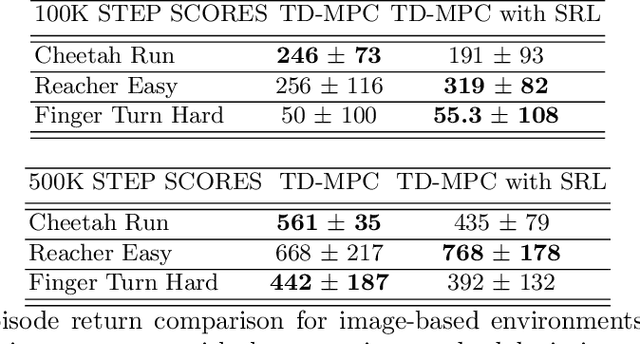
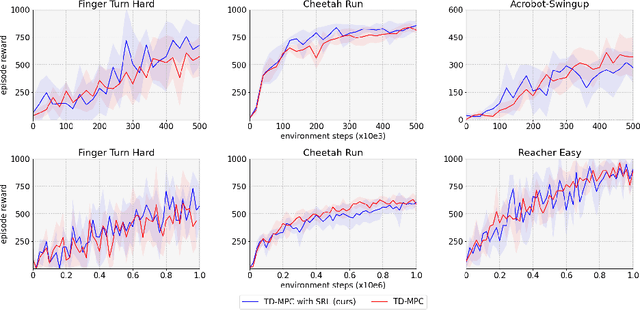
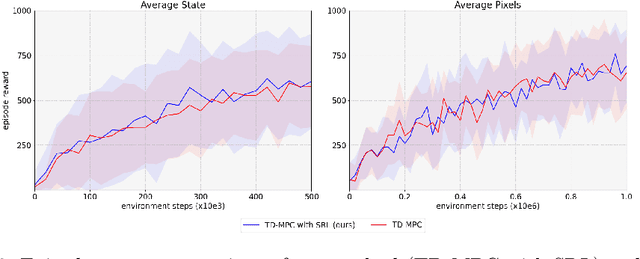
Over the last few years, we have not seen any major developments in model-free or model-based learning methods that would make one obsolete relative to the other. In most cases, the used technique is heavily dependent on the use case scenario or other attributes, e.g. the environment. Both approaches have their own advantages, for example, sample efficiency or computational efficiency. However, when combining the two, the advantages of each can be combined and hence achieve better performance. The TD-MPC framework is an example of this approach. On the one hand, a world model in combination with model predictive control is used to get a good initial estimate of the value function. On the other hand, a Q function is used to provide a good long-term estimate. Similar to algorithms like MuZero a latent state representation is used, where only task-relevant information is encoded to reduce the complexity. In this paper, we propose the use of a reconstruction function within the TD-MPC framework, so that the agent can reconstruct the original observation given the internal state representation. This allows our agent to have a more stable learning signal during training and also improves sample efficiency. Our proposed addition of another loss term leads to improved performance on both state- and image-based tasks from the DeepMind-Control suite.
Sample-efficient Real-time Planning with Curiosity Cross-Entropy Method and Contrastive Learning
Mar 07, 2023Model-based reinforcement learning (MBRL) with real-time planning has shown great potential in locomotion and manipulation control tasks. However, the existing planning methods, such as the Cross-Entropy Method (CEM), do not scale well to complex high-dimensional environments. One of the key reasons for underperformance is the lack of exploration, as these planning methods only aim to maximize the cumulative extrinsic reward over the planning horizon. Furthermore, planning inside the compact latent space in the absence of observations makes it challenging to use curiosity-based intrinsic motivation. We propose Curiosity CEM (CCEM), an improved version of the CEM algorithm for encouraging exploration via curiosity. Our proposed method maximizes the sum of state-action Q values over the planning horizon, in which these Q values estimate the future extrinsic and intrinsic reward, hence encouraging reaching novel observations. In addition, our model uses contrastive representation learning to efficiently learn latent representations. Experiments on image-based continuous control tasks from the DeepMind Control suite show that CCEM is by a large margin more sample-efficient than previous MBRL algorithms and compares favorably with the best model-free RL methods.