 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Deep Reinforcement Learning with Task-Agnostic Policy Distillation
Nov 25, 2024Central to the development of universal learning systems is the ability to solve multiple tasks without retraining from scratch when new data arrives. This is crucial because each task requires significant training time. Addressing the problem of continual learning necessitates various methods due to the complexity of the problem space. This problem space includes: (1) addressing catastrophic forgetting to retain previously learned tasks, (2) demonstrating positive forward transfer for faster learning, (3) ensuring scalability across numerous tasks, and (4) facilitating learning without requiring task labels, even in the absence of clear task boundaries. In this paper, the Task-Agnostic Policy Distillation (TAPD) framework is introduced. This framework alleviates problems (1)-(4) by incorporating a task-agnostic phase, where an agent explores its environment without any external goal and maximizes only its intrinsic motivation. The knowledge gained during this phase is later distilled for further exploration. Therefore, the agent acts in a self-supervised manner by systematically seeking novel states. By utilizing task-agnostic distilled knowledge, the agent can solve downstream tasks more efficiently, leading to improved sample efficiency. Our code is available at the repository: https://github.com/wabbajack1/TAPD.
QT-TDM: Planning with Transformer Dynamics Model and Autoregressive Q-Learning
Jul 26, 2024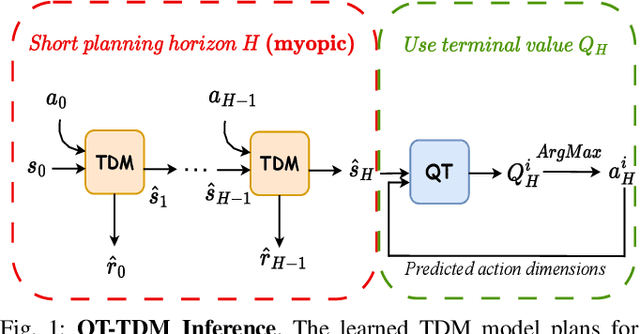
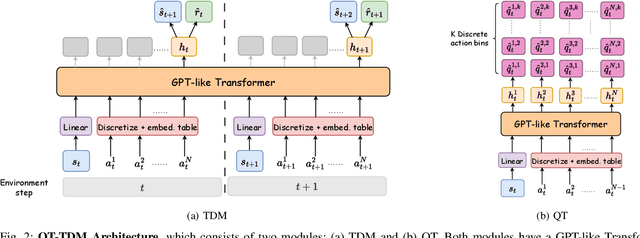

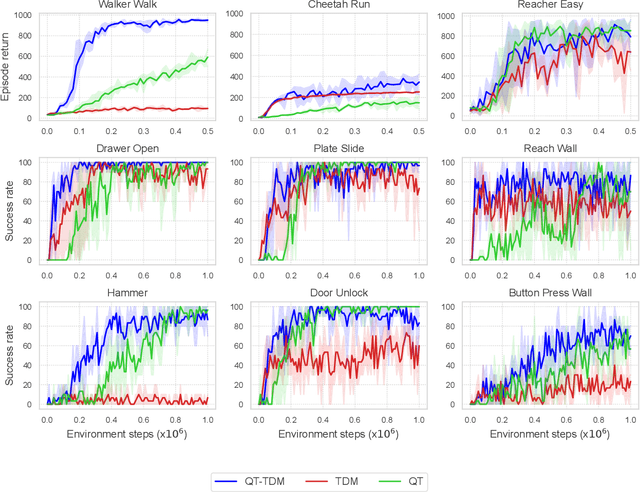
Inspired by the success of the Transformer architecture in natural language processing and computer vision, we investigate the use of Transformers in Reinforcement Learning (RL), specifically in modeling the environment's dynamics using Transformer Dynamics Models (TDMs). We evaluate the capabilities of TDMs for continuous control in real-time planning scenarios with Model Predictive Control (MPC). While Transformers excel in long-horizon prediction, their tokenization mechanism and autoregressive nature lead to costly planning over long horizons, especially as the environment's dimensionality increases. To alleviate this issue, we use a TDM for short-term planning, and learn an autoregressive discrete Q-function using a separate Q-Transformer (QT) model to estimate a long-term return beyond the short-horizon planning. Our proposed method, QT-TDM, integrates the robust predictive capabilities of Transformers as dynamics models with the efficacy of a model-free Q-Transformer to mitigate the computational burden associated with real-time planning. Experiments in diverse state-based continuous control tasks show that QT-TDM is superior in performance and sample efficiency compared to existing Transformer-based RL models while achieving fast and computationally efficient inference.
Continual Robot Learning using Self-Supervised Task Inference
Sep 10, 2023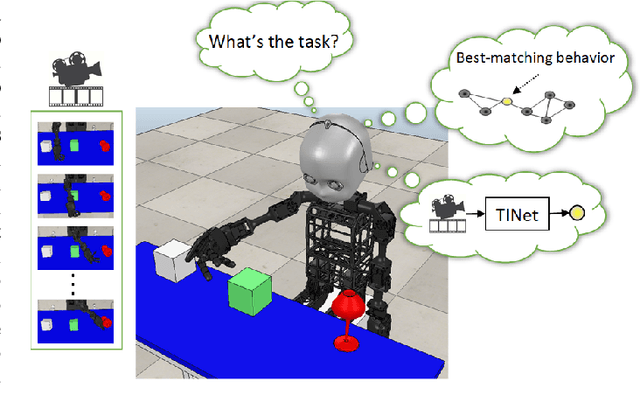
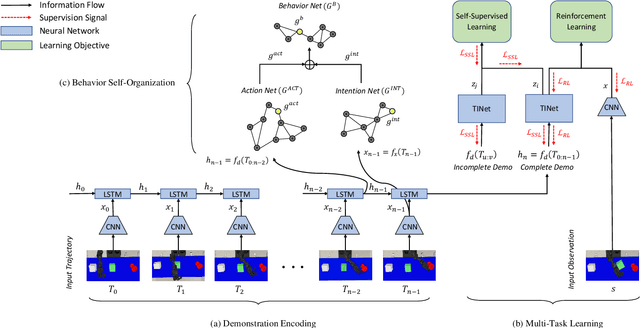


Endowing robots with the human ability to learn a growing set of skills over the course of a lifetime as opposed to mastering single tasks is an open problem in robot learning. While multi-task learning approaches have been proposed to address this problem, they pay little attention to task inference. In order to continually learn new tasks, the robot first needs to infer the task at hand without requiring predefined task representations. In this paper, we propose a self-supervised task inference approach. Our approach learns action and intention embeddings from self-organization of the observed movement and effect parts of unlabeled demonstrations and a higher-level behavior embedding from self-organization of the joint action-intention embeddings. We construct a behavior-matching self-supervised learning objective to train a novel Task Inference Network (TINet) to map an unlabeled demonstration to its nearest behavior embedding, which we use as the task representation. A multi-task policy is built on top of the TINet and trained with reinforcement learning to optimize performance over tasks. We evaluate our approach in the fixed-set and continual multi-task learning settings with a humanoid robot and compare it to different multi-task learning baselines. The results show that our approach outperforms the other baselines, with the difference being more pronounced in the challenging continual learning setting, and can infer tasks from incomplete demonstrations. Our approach is also shown to generalize to unseen tasks based on a single demonstration in one-shot task generalization experiments.
Map-based Experience Replay: A Memory-Efficient Solution to Catastrophic Forgetting in Reinforcement Learning
May 03, 2023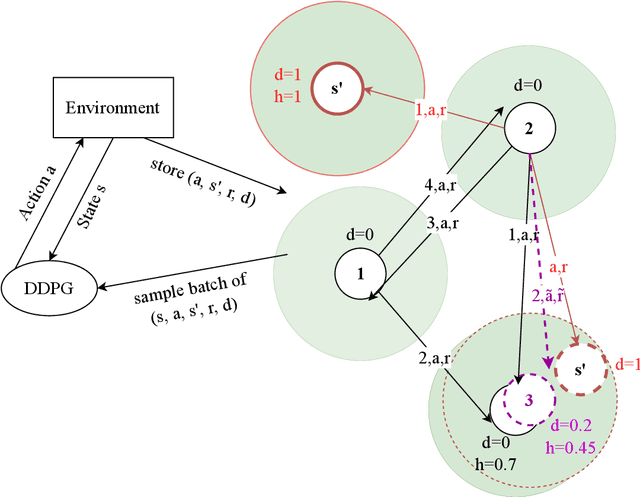

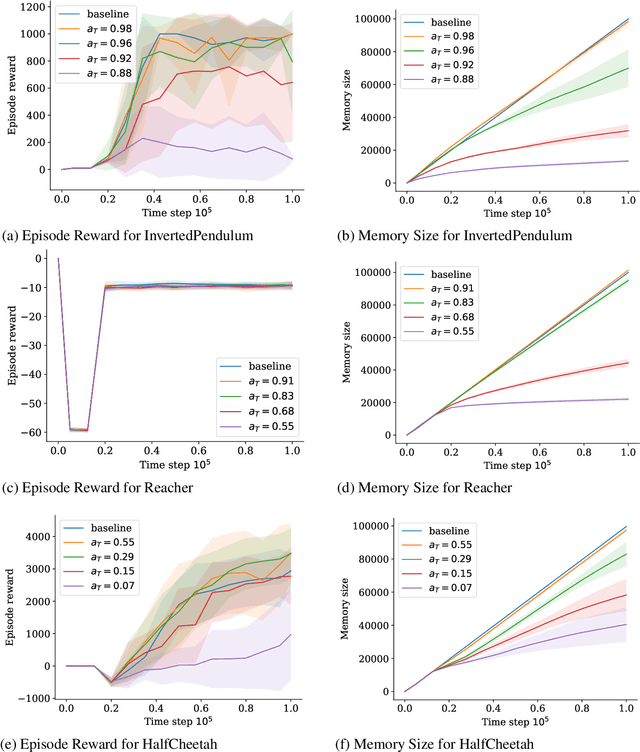
Deep Reinforcement Learning agents often suffer from catastrophic forgetting, forgetting previously found solutions in parts of the input space when training on new data. Replay Memories are a common solution to the problem, decorrelating and shuffling old and new training samples. They naively store state transitions as they come in, without regard for redundancy. We introduce a novel cognitive-inspired replay memory approach based on the Grow-When-Required (GWR) self-organizing network, which resembles a map-based mental model of the world. Our approach organizes stored transitions into a concise environment-model-like network of state-nodes and transition-edges, merging similar samples to reduce the memory size and increase pair-wise distance among samples, which increases the relevancy of each sample. Overall, our paper shows that map-based experience replay allows for significant memory reduction with only small performance decreases.
Model Predictive Control with Self-supervised Representation Learning
Apr 14, 2023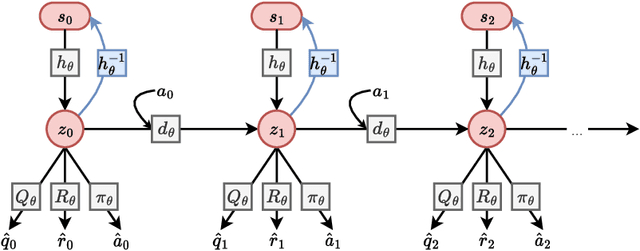
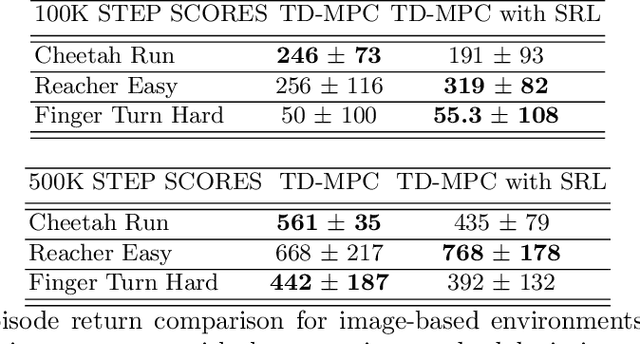
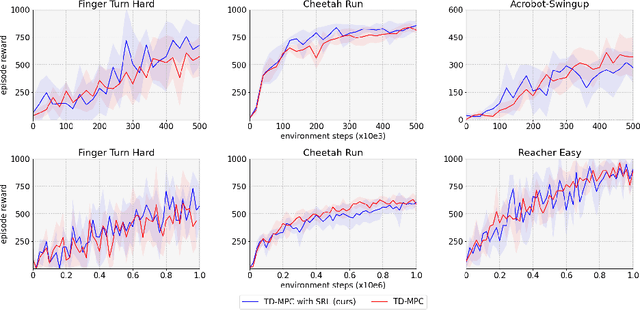
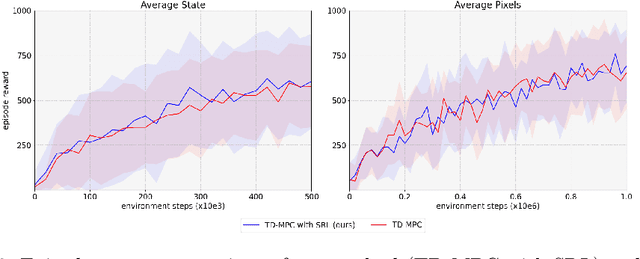
Over the last few years, we have not seen any major developments in model-free or model-based learning methods that would make one obsolete relative to the other. In most cases, the used technique is heavily dependent on the use case scenario or other attributes, e.g. the environment. Both approaches have their own advantages, for example, sample efficiency or computational efficiency. However, when combining the two, the advantages of each can be combined and hence achieve better performance. The TD-MPC framework is an example of this approach. On the one hand, a world model in combination with model predictive control is used to get a good initial estimate of the value function. On the other hand, a Q function is used to provide a good long-term estimate. Similar to algorithms like MuZero a latent state representation is used, where only task-relevant information is encoded to reduce the complexity. In this paper, we propose the use of a reconstruction function within the TD-MPC framework, so that the agent can reconstruct the original observation given the internal state representation. This allows our agent to have a more stable learning signal during training and also improves sample efficiency. Our proposed addition of another loss term leads to improved performance on both state- and image-based tasks from the DeepMind-Control suite.
Chat with the Environment: Interactive Multimodal Perception using Large Language Models
Mar 14, 2023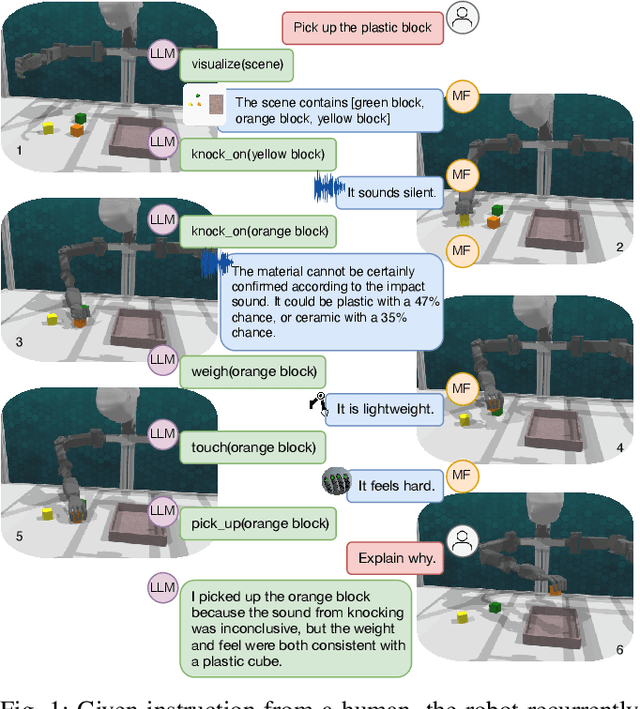
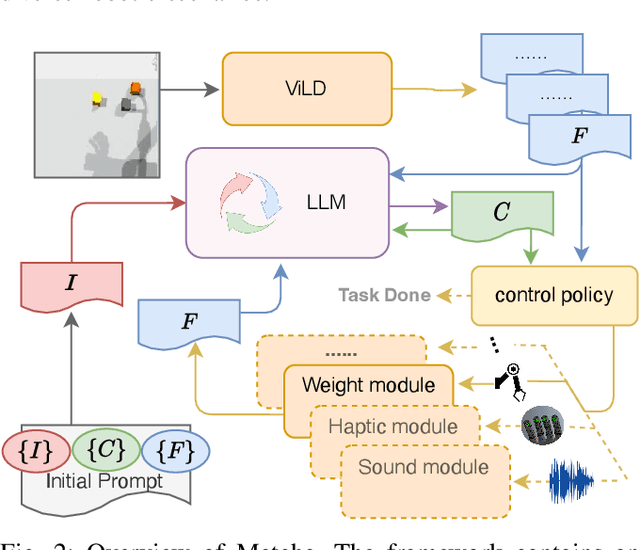


Programming robot behaviour in a complex world faces challenges on multiple levels, from dextrous low-level skills to high-level planning and reasoning. Recent pre-trained Large Language Models (LLMs) have shown remarkable reasoning ability in zero-shot robotic planning. However, it remains challenging to ground LLMs in multimodal sensory input and continuous action output, while enabling a robot to interact with its environment and acquire novel information as its policies unfold. We develop a robot interaction scenario with a partially observable state, which necessitates a robot to decide on a range of epistemic actions in order to sample sensory information among multiple modalities, before being able to execute the task correctly. An interactive perception framework is therefore proposed with an LLM as its backbone, whose ability is exploited to instruct epistemic actions and to reason over the resulting multimodal sensations (vision, sound, haptics, proprioception), as well as to plan an entire task execution based on the interactively acquired information. Our study demonstrates that LLMs can provide high-level planning and reasoning skills and control interactive robot behaviour in a multimodal environment, while multimodal modules with the context of the environmental state help ground the LLMs and extend their processing ability.
Learning Bidirectional Action-Language Translation with Limited Supervision and Incongruent Extra Input
Jan 09, 2023Human infant learning happens during exploration of the environment, by interaction with objects, and by listening to and repeating utterances casually, which is analogous to unsupervised learning. Only occasionally, a learning infant would receive a matching verbal description of an action it is committing, which is similar to supervised learning. Such a learning mechanism can be mimicked with deep learning. We model this weakly supervised learning paradigm using our Paired Gated Autoencoders (PGAE) model, which combines an action and a language autoencoder. After observing a performance drop when reducing the proportion of supervised training, we introduce the Paired Transformed Autoencoders (PTAE) model, using Transformer-based crossmodal attention. PTAE achieves significantly higher accuracy in language-to-action and action-to-language translations, particularly in realistic but difficult cases when only few supervised training samples are available. We also test whether the trained model behaves realistically with conflicting multimodal input. In accordance with the concept of incongruence in psychology, conflict deteriorates the model output. Conflicting action input has a more severe impact than conflicting language input, and more conflicting features lead to larger interference. PTAE can be trained on mostly unlabelled data where labeled data is scarce, and it behaves plausibly when tested with incongruent input.
Impact Makes a Sound and Sound Makes an Impact: Sound Guides Representations and Explorations
Aug 04, 2022
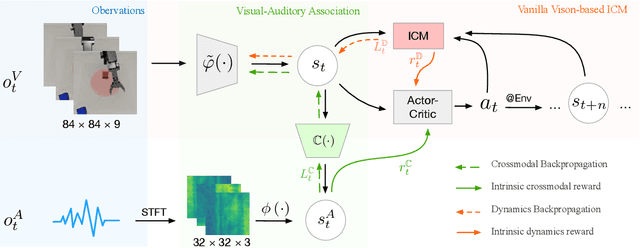
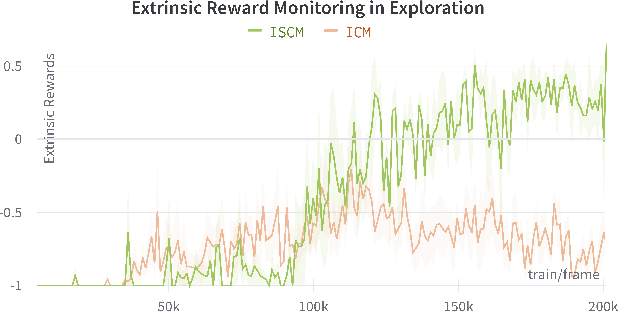
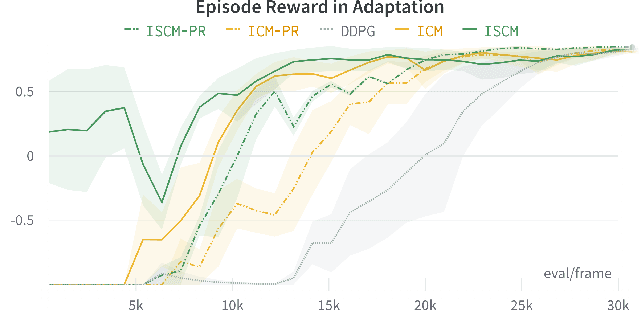
Sound is one of the most informative and abundant modalities in the real world while being robust to sense without contacts by small and cheap sensors that can be placed on mobile devices. Although deep learning is capable of extracting information from multiple sensory inputs, there has been little use of sound for the control and learning of robotic actions. For unsupervised reinforcement learning, an agent is expected to actively collect experiences and jointly learn representations and policies in a self-supervised way. We build realistic robotic manipulation scenarios with physics-based sound simulation and propose the Intrinsic Sound Curiosity Module (ISCM). The ISCM provides feedback to a reinforcement learner to learn robust representations and to reward a more efficient exploration behavior. We perform experiments with sound enabled during pre-training and disabled during adaptation, and show that representations learned by ISCM outperform the ones by vision-only baselines and pre-trained policies can accelerate the learning process when applied to downstream tasks.
Behavior Self-Organization Supports Task Inference for Continual Robot Learning
Jul 09, 2021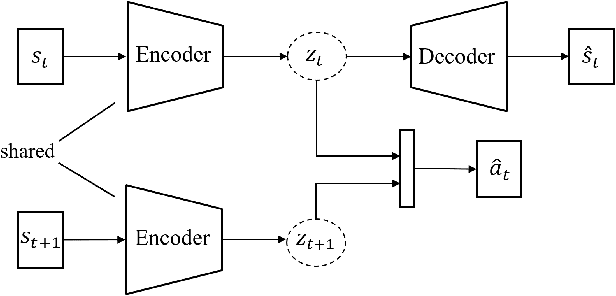
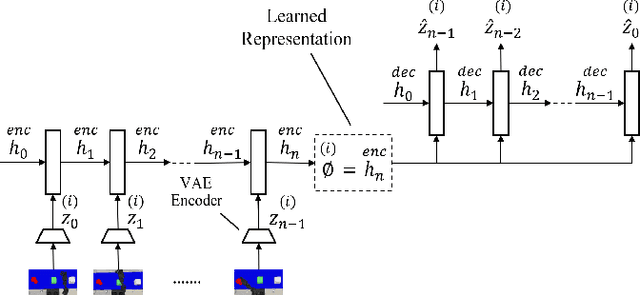
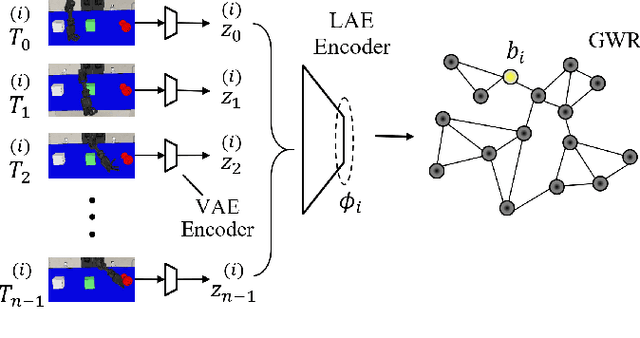

Recent advances in robot learning have enabled robots to become increasingly better at mastering a predefined set of tasks. On the other hand, as humans, we have the ability to learn a growing set of tasks over our lifetime. Continual robot learning is an emerging research direction with the goal of endowing robots with this ability. In order to learn new tasks over time, the robot first needs to infer the task at hand. Task inference, however, has received little attention in the multi-task learning literature. In this paper, we propose a novel approach to continual learning of robotic control tasks. Our approach performs unsupervised learning of behavior embeddings by incrementally self-organizing demonstrated behaviors. Task inference is made by finding the nearest behavior embedding to a demonstrated behavior, which is used together with the environment state as input to a multi-task policy trained with reinforcement learning to optimize performance over tasks. Unlike previous approaches, our approach makes no assumptions about task distribution and requires no task exploration to infer tasks. We evaluate our approach in experiments with concurrently and sequentially presented tasks and show that it outperforms other multi-task learning approaches in terms of generalization performance and convergence speed, particularly in the continual learning setting.
Improving Model-Based Reinforcement Learning with Internal State Representations through Self-Supervision
Feb 10, 2021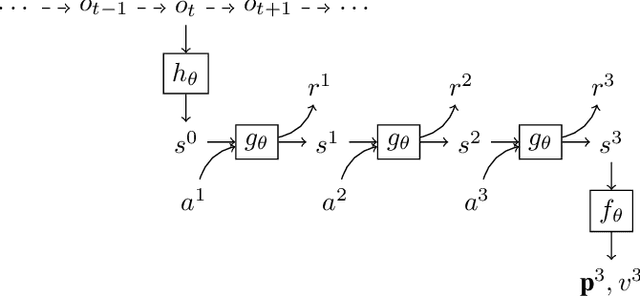
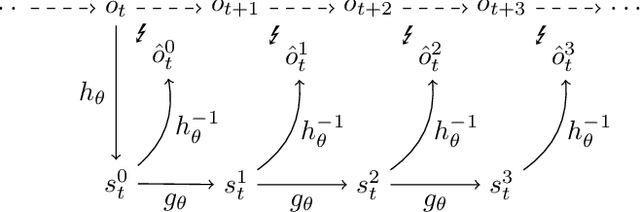
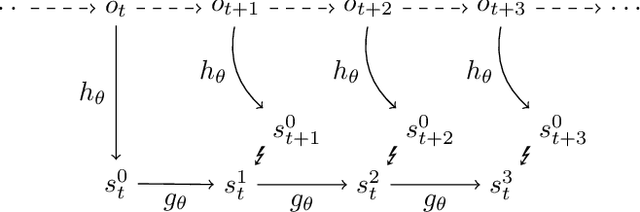
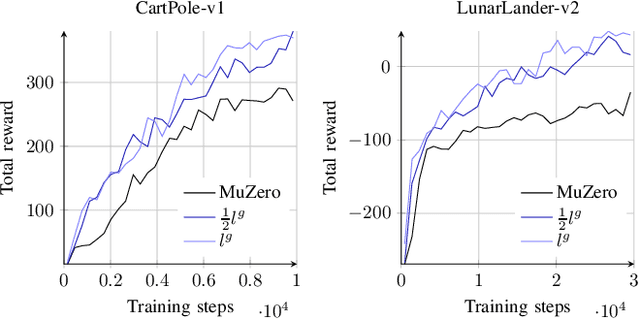
Using a model of the environment, reinforcement learning agents can plan their future moves and achieve superhuman performance in board games like Chess, Shogi, and Go, while remaining relatively sample-efficient. As demonstrated by the MuZero Algorithm, the environment model can even be learned dynamically, generalizing the agent to many more tasks while at the same time achieving state-of-the-art performance. Notably, MuZero uses internal state representations derived from real environment states for its predictions. In this paper, we bind the model's predicted internal state representation to the environment state via two additional terms: a reconstruction model loss and a simpler consistency loss, both of which work independently and unsupervised, acting as constraints to stabilize the learning process. Our experiments show that this new integration of reconstruction model loss and simpler consistency loss provide a significant performance increase in OpenAI Gym environments. Our modifications also enable self-supervised pretraining for MuZero, so the algorithm can learn about environment dynamics before a goal is made available.