 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTheory of Mind for Explainable Human-Robot Interaction
Dec 31, 2025Within the context of human-robot interaction (HRI), Theory of Mind (ToM) is intended to serve as a user-friendly backend to the interface of robotic systems, enabling robots to infer and respond to human mental states. When integrated into robots, ToM allows them to adapt their internal models to users' behaviors, enhancing the interpretability and predictability of their actions. Similarly, Explainable Artificial Intelligence (XAI) aims to make AI systems transparent and interpretable, allowing humans to understand and interact with them effectively. Since ToM in HRI serves related purposes, we propose to consider ToM as a form of XAI and evaluate it through the eValuation XAI (VXAI) framework and its seven desiderata. This paper identifies a critical gap in the application of ToM within HRI, as existing methods rarely assess the extent to which explanations correspond to the robot's actual internal reasoning. To address this limitation, we propose to integrate ToM within XAI frameworks. By embedding ToM principles inside XAI, we argue for a shift in perspective, as current XAI research focuses predominantly on the AI system itself and often lacks user-centered explanations. Incorporating ToM would enable a change in focus, prioritizing the user's informational needs and perspective.
LLM-based Interactive Imitation Learning for Robotic Manipulation
Apr 30, 2025



Recent advancements in machine learning provide methods to train autonomous agents capable of handling the increasing complexity of sequential decision-making in robotics. Imitation Learning (IL) is a prominent approach, where agents learn to control robots based on human demonstrations. However, IL commonly suffers from violating the independent and identically distributed (i.i.d) assumption in robotic tasks. Interactive Imitation Learning (IIL) achieves improved performance by allowing agents to learn from interactive feedback from human teachers. Despite these improvements, both approaches come with significant costs due to the necessity of human involvement. Leveraging the emergent capabilities of Large Language Models (LLMs) in reasoning and generating human-like responses, we introduce LLM-iTeach -- a novel IIL framework that utilizes an LLM as an interactive teacher to enhance agent performance while alleviating the dependence on human resources. Firstly, LLM-iTeach uses a hierarchical prompting strategy that guides the LLM in generating a policy in Python code. Then, with a designed similarity-based feedback mechanism, LLM-iTeach provides corrective and evaluative feedback interactively during the agent's training. We evaluate LLM-iTeach against baseline methods such as Behavior Cloning (BC), an IL method, and CEILing, a state-of-the-art IIL method using a human teacher, on various robotic manipulation tasks. Our results demonstrate that LLM-iTeach surpasses BC in the success rate and achieves or even outscores that of CEILing, highlighting the potential of LLMs as cost-effective, human-like teachers in interactive learning environments. We further demonstrate the method's potential for generalization by evaluating it on additional tasks. The code and prompts are provided at: https://github.com/Tubicor/LLM-iTeach.
LLM+MAP: Bimanual Robot Task Planning using Large Language Models and Planning Domain Definition Language
Mar 21, 2025Bimanual robotic manipulation provides significant versatility, but also presents an inherent challenge due to the complexity involved in the spatial and temporal coordination between two hands. Existing works predominantly focus on attaining human-level manipulation skills for robotic hands, yet little attention has been paid to task planning on long-horizon timescales. With their outstanding in-context learning and zero-shot generation abilities, Large Language Models (LLMs) have been applied and grounded in diverse robotic embodiments to facilitate task planning. However, LLMs still suffer from errors in long-horizon reasoning and from hallucinations in complex robotic tasks, lacking a guarantee of logical correctness when generating the plan. Previous works, such as LLM+P, extended LLMs with symbolic planners. However, none have been successfully applied to bimanual robots. New challenges inevitably arise in bimanual manipulation, necessitating not only effective task decomposition but also efficient task allocation. To address these challenges, this paper introduces LLM+MAP, a bimanual planning framework that integrates LLM reasoning and multi-agent planning, automating effective and efficient bimanual task planning. We conduct simulated experiments on various long-horizon manipulation tasks of differing complexity. Our method is built using GPT-4o as the backend, and we compare its performance against plans generated directly by LLMs, including GPT-4o, V3 and also recent strong reasoning models o1 and R1. By analyzing metrics such as planning time, success rate, group debits, and planning-step reduction rate, we demonstrate the superior performance of LLM+MAP, while also providing insights into robotic reasoning. Code is available at https://github.com/Kchu/LLM-MAP.
QT-TDM: Planning with Transformer Dynamics Model and Autoregressive Q-Learning
Jul 26, 2024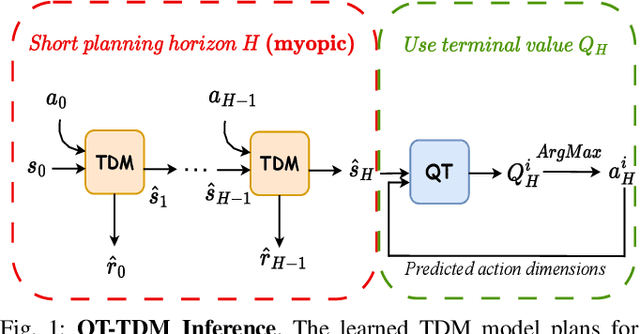
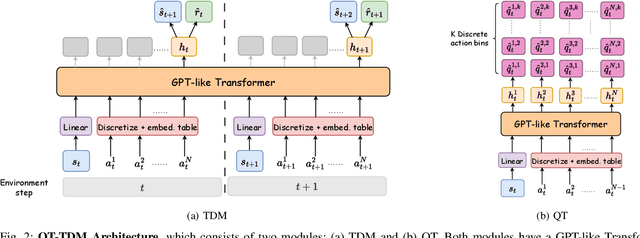

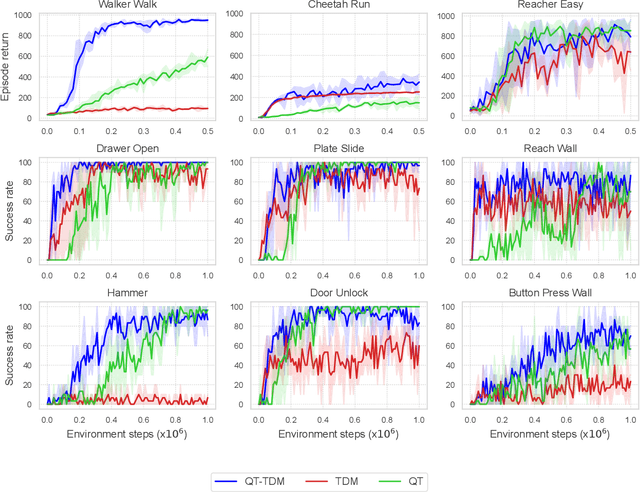
Inspired by the success of the Transformer architecture in natural language processing and computer vision, we investigate the use of Transformers in Reinforcement Learning (RL), specifically in modeling the environment's dynamics using Transformer Dynamics Models (TDMs). We evaluate the capabilities of TDMs for continuous control in real-time planning scenarios with Model Predictive Control (MPC). While Transformers excel in long-horizon prediction, their tokenization mechanism and autoregressive nature lead to costly planning over long horizons, especially as the environment's dimensionality increases. To alleviate this issue, we use a TDM for short-term planning, and learn an autoregressive discrete Q-function using a separate Q-Transformer (QT) model to estimate a long-term return beyond the short-horizon planning. Our proposed method, QT-TDM, integrates the robust predictive capabilities of Transformers as dynamics models with the efficacy of a model-free Q-Transformer to mitigate the computational burden associated with real-time planning. Experiments in diverse state-based continuous control tasks show that QT-TDM is superior in performance and sample efficiency compared to existing Transformer-based RL models while achieving fast and computationally efficient inference.
Agentic Skill Discovery
May 23, 2024Language-conditioned robotic skills make it possible to apply the high-level reasoning of Large Language Models (LLMs) to low-level robotic control. A remaining challenge is to acquire a diverse set of fundamental skills. Existing approaches either manually decompose a complex task into atomic robotic actions in a top-down fashion, or bootstrap as many combinations as possible in a bottom-up fashion to cover a wider range of task possibilities. These decompositions or combinations, however, require an initial skill library. For example, a "grasping" capability can never emerge from a skill library containing only diverse "pushing" skills. Existing skill discovery techniques with reinforcement learning acquire skills by an exhaustive exploration but often yield non-meaningful behaviors. In this study, we introduce a novel framework for skill discovery that is entirely driven by LLMs. The framework begins with an LLM generating task proposals based on the provided scene description and the robot's configurations, aiming to incrementally acquire new skills upon task completion. For each proposed task, a series of reinforcement learning processes are initiated, utilizing reward and success determination functions sampled by the LLM to develop the corresponding policy. The reliability and trustworthiness of learned behaviors are further ensured by an independent vision-language model. We show that starting with zero skill, the ASD skill library emerges and expands to more and more meaningful and reliable skills, enabling the robot to efficiently further propose and complete advanced tasks. The project page can be found at: https://agentic-skill-discovery.github.io.
Large Language Models for Orchestrating Bimanual Robots
Apr 02, 2024Although there has been rapid progress in endowing robots with the ability to solve complex manipulation tasks, generating control policies for bimanual robots to solve tasks involving two hands is still challenging because of the difficulties in effective temporal and spatial coordination. With emergent abilities in terms of step-by-step reasoning and in-context learning, Large Language Models (LLMs) have taken control of a variety of robotic tasks. However, the nature of language communication via a single sequence of discrete symbols makes LLM-based coordination in continuous space a particular challenge for bimanual tasks. To tackle this challenge for the first time by an LLM, we present LAnguage-model-based Bimanual ORchestration (LABOR), an agent utilizing an LLM to analyze task configurations and devise coordination control policies for addressing long-horizon bimanual tasks. In the simulated environment, the LABOR agent is evaluated through several everyday tasks on the NICOL humanoid robot. Reported success rates indicate that overall coordination efficiency is close to optimal performance, while the analysis of failure causes, classified into spatial and temporal coordination and skill selection, shows that these vary over tasks. The project website can be found at http://labor-agent.github.io
Accelerating Reinforcement Learning of Robotic Manipulations via Feedback from Large Language Models
Nov 04, 2023



Reinforcement Learning (RL) plays an important role in the robotic manipulation domain since it allows self-learning from trial-and-error interactions with the environment. Still, sample efficiency and reward specification seriously limit its potential. One possible solution involves learning from expert guidance. However, obtaining a human expert is impractical due to the high cost of supervising an RL agent, and developing an automatic supervisor is a challenging endeavor. Large Language Models (LLMs) demonstrate remarkable abilities to provide human-like feedback on user inputs in natural language. Nevertheless, they are not designed to directly control low-level robotic motions, as their pretraining is based on vast internet data rather than specific robotics data. In this paper, we introduce the Lafite-RL (Language agent feedback interactive Reinforcement Learning) framework, which enables RL agents to learn robotic tasks efficiently by taking advantage of LLMs' timely feedback. Our experiments conducted on RLBench tasks illustrate that, with simple prompt design in natural language, the Lafite-RL agent exhibits improved learning capabilities when guided by an LLM. It outperforms the baseline in terms of both learning efficiency and success rate, underscoring the efficacy of the rewards provided by an LLM.
Enhancing Zero-Shot Chain-of-Thought Reasoning in Large Language Models through Logic
Sep 23, 2023Recent advancements in large language models have showcased their remarkable generalizability across various domains. However, their reasoning abilities still have significant room for improvement, especially when confronted with scenarios requiring multi-step reasoning. Although large language models possess extensive knowledge, their behavior, particularly in terms of reasoning, often fails to effectively utilize this knowledge to establish a coherent thinking paradigm. Generative language models sometimes show hallucinations as their reasoning procedures are unconstrained by logical principles. Aiming to improve the zero-shot chain-of-thought reasoning ability of large language models, we propose Logical Chain-of-Thought (LogiCoT), a neurosymbolic framework that leverages principles from symbolic logic to verify and revise the reasoning processes accordingly. Experimental evaluations conducted on language tasks in diverse domains, including arithmetic, commonsense, symbolic, causal inference, and social problems, demonstrate the efficacy of the enhanced reasoning paradigm by logic.
Chat with the Environment: Interactive Multimodal Perception using Large Language Models
Mar 14, 2023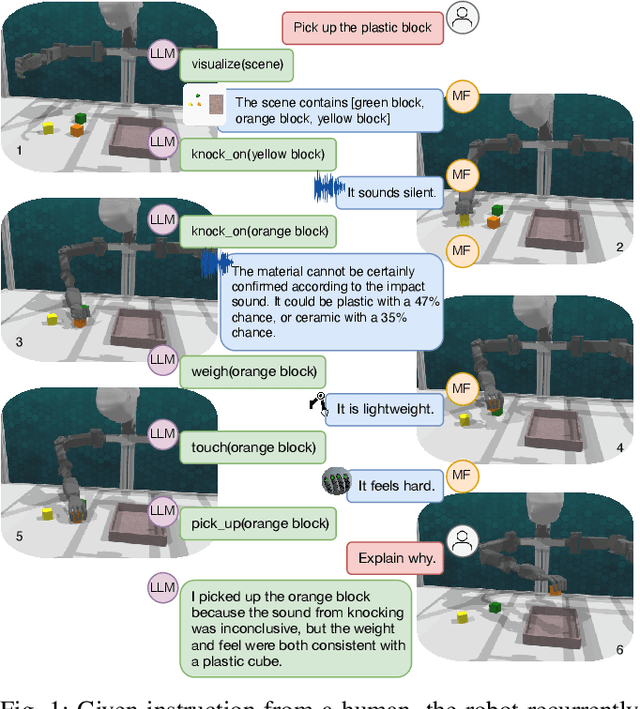
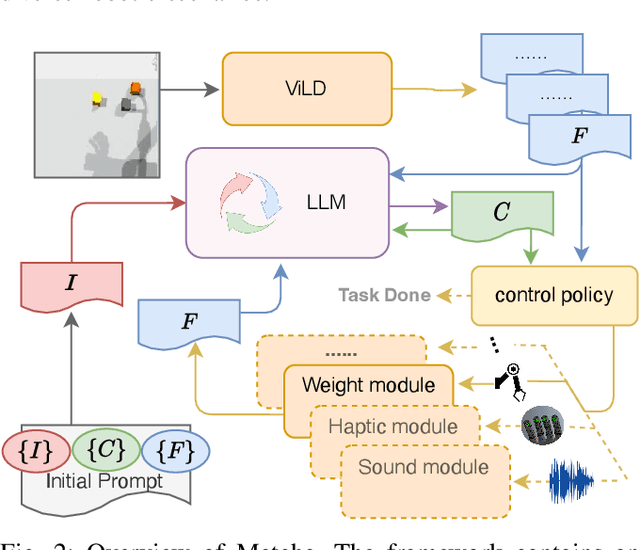


Programming robot behaviour in a complex world faces challenges on multiple levels, from dextrous low-level skills to high-level planning and reasoning. Recent pre-trained Large Language Models (LLMs) have shown remarkable reasoning ability in zero-shot robotic planning. However, it remains challenging to ground LLMs in multimodal sensory input and continuous action output, while enabling a robot to interact with its environment and acquire novel information as its policies unfold. We develop a robot interaction scenario with a partially observable state, which necessitates a robot to decide on a range of epistemic actions in order to sample sensory information among multiple modalities, before being able to execute the task correctly. An interactive perception framework is therefore proposed with an LLM as its backbone, whose ability is exploited to instruct epistemic actions and to reason over the resulting multimodal sensations (vision, sound, haptics, proprioception), as well as to plan an entire task execution based on the interactively acquired information. Our study demonstrates that LLMs can provide high-level planning and reasoning skills and control interactive robot behaviour in a multimodal environment, while multimodal modules with the context of the environmental state help ground the LLMs and extend their processing ability.
Sample-efficient Real-time Planning with Curiosity Cross-Entropy Method and Contrastive Learning
Mar 07, 2023Model-based reinforcement learning (MBRL) with real-time planning has shown great potential in locomotion and manipulation control tasks. However, the existing planning methods, such as the Cross-Entropy Method (CEM), do not scale well to complex high-dimensional environments. One of the key reasons for underperformance is the lack of exploration, as these planning methods only aim to maximize the cumulative extrinsic reward over the planning horizon. Furthermore, planning inside the compact latent space in the absence of observations makes it challenging to use curiosity-based intrinsic motivation. We propose Curiosity CEM (CCEM), an improved version of the CEM algorithm for encouraging exploration via curiosity. Our proposed method maximizes the sum of state-action Q values over the planning horizon, in which these Q values estimate the future extrinsic and intrinsic reward, hence encouraging reaching novel observations. In addition, our model uses contrastive representation learning to efficiently learn latent representations. Experiments on image-based continuous control tasks from the DeepMind Control suite show that CCEM is by a large margin more sample-efficient than previous MBRL algorithms and compares favorably with the best model-free RL methods.