 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMental Modeling of Reinforcement Learning Agents by Language Models
Jun 26, 2024



Can emergent language models faithfully model the intelligence of decision-making agents? Though modern language models exhibit already some reasoning ability, and theoretically can potentially express any probable distribution over tokens, it remains underexplored how the world knowledge these pretrained models have memorized can be utilized to comprehend an agent's behaviour in the physical world. This study empirically examines, for the first time, how well large language models (LLMs) can build a mental model of agents, termed agent mental modelling, by reasoning about an agent's behaviour and its effect on states from agent interaction history. This research may unveil the potential of leveraging LLMs for elucidating RL agent behaviour, addressing a key challenge in eXplainable reinforcement learning (XRL). To this end, we propose specific evaluation metrics and test them on selected RL task datasets of varying complexity, reporting findings on agent mental model establishment. Our results disclose that LLMs are not yet capable of fully mental modelling agents through inference alone without further innovations. This work thus provides new insights into the capabilities and limitations of modern LLMs.
Details Make a Difference: Object State-Sensitive Neurorobotic Task Planning
Jun 14, 2024

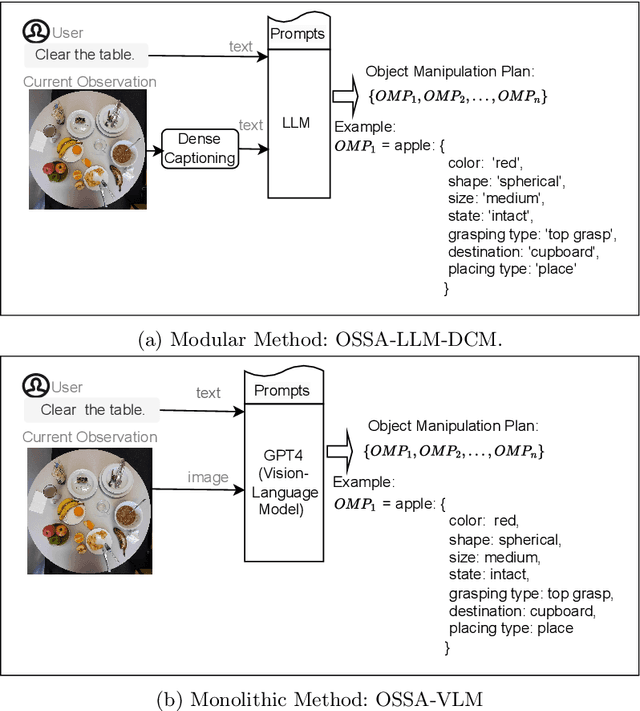
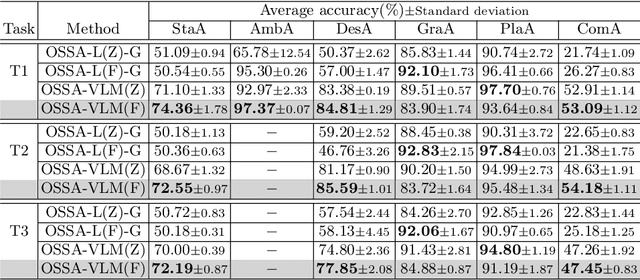
The state of an object reflects its current status or condition and is important for a robot's task planning and manipulation. However, detecting an object's state and generating a state-sensitive plan for robots is challenging. Recently, pre-trained Large Language Models (LLMs) and Vision-Language Models (VLMs) have shown impressive capabilities in generating plans. However, to the best of our knowledge, there is hardly any investigation on whether LLMs or VLMs can also generate object state-sensitive plans. To study this, we introduce an Object State-Sensitive Agent (OSSA), a task-planning agent empowered by pre-trained neural networks. We propose two methods for OSSA: (i) a modular model consisting of a pre-trained vision processing module (dense captioning model, DCM) and a natural language processing model (LLM), and (ii) a monolithic model consisting only of a VLM. To quantitatively evaluate the performances of the two methods, we use tabletop scenarios where the task is to clear the table. We contribute a multimodal benchmark dataset that takes object states into consideration. Our results show that both methods can be used for object state-sensitive tasks, but the monolithic approach outperforms the modular approach. The code for OSSA is available at \url{https://github.com/Xiao-wen-Sun/OSSA}
Causal State Distillation for Explainable Reinforcement Learning
Dec 30, 2023



Reinforcement learning (RL) is a powerful technique for training intelligent agents, but understanding why these agents make specific decisions can be quite challenging. This lack of transparency in RL models has been a long-standing problem, making it difficult for users to grasp the reasons behind an agent's behaviour. Various approaches have been explored to address this problem, with one promising avenue being reward decomposition (RD). RD is appealing as it sidesteps some of the concerns associated with other methods that attempt to rationalize an agent's behaviour in a post-hoc manner. RD works by exposing various facets of the rewards that contribute to the agent's objectives during training. However, RD alone has limitations as it primarily offers insights based on sub-rewards and does not delve into the intricate cause-and-effect relationships that occur within an RL agent's neural model. In this paper, we present an extension of RD that goes beyond sub-rewards to provide more informative explanations. Our approach is centred on a causal learning framework that leverages information-theoretic measures for explanation objectives that encourage three crucial properties of causal factors: \emph{causal sufficiency}, \emph{sparseness}, and \emph{orthogonality}. These properties help us distill the cause-and-effect relationships between the agent's states and actions or rewards, allowing for a deeper understanding of its decision-making processes. Our framework is designed to generate local explanations and can be applied to a wide range of RL tasks with multiple reward channels. Through a series of experiments, we demonstrate that our approach offers more meaningful and insightful explanations for the agent's action selections.
Read Between the Layers: Leveraging Intra-Layer Representations for Rehearsal-Free Continual Learning with Pre-Trained Models
Dec 13, 2023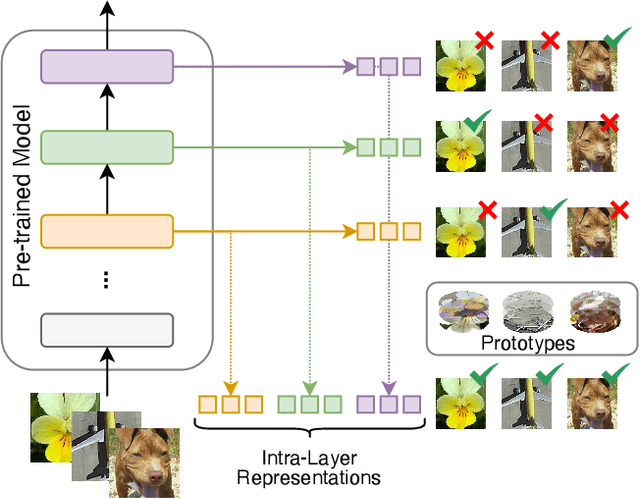
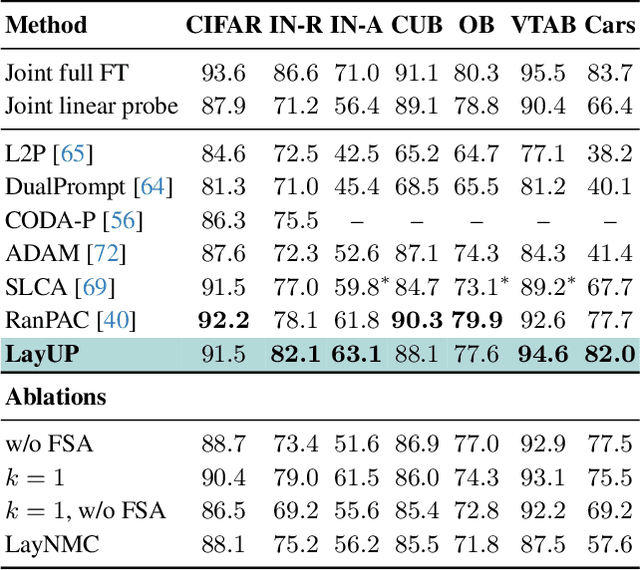
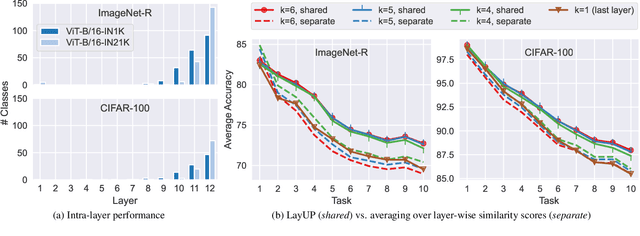
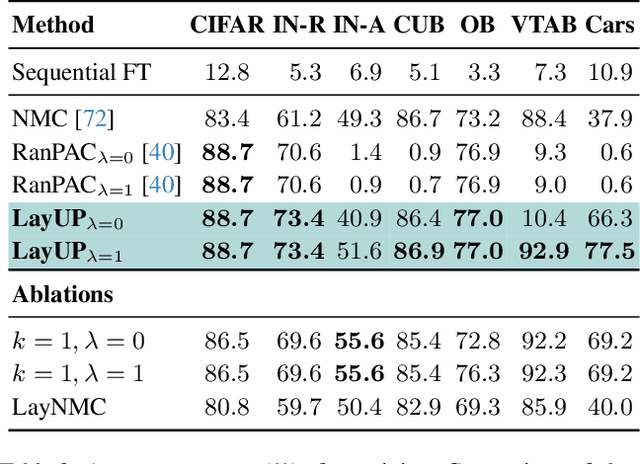
We address the Continual Learning (CL) problem, where a model has to learn a sequence of tasks from non-stationary distributions while preserving prior knowledge as it encounters new experiences. With the advancement of foundation models, CL research has shifted focus from the initial learning-from-scratch paradigm to the use of generic features from large-scale pre-training. However, existing approaches to CL with pre-trained models only focus on separating the class-specific features from the final representation layer and neglect the power of intermediate representations that capture low- and mid-level features naturally more invariant to domain shifts. In this work, we propose LayUP, a new class-prototype-based approach to continual learning that leverages second-order feature statistics from multiple intermediate layers of a pre-trained network. Our method is conceptually simple, does not require any replay buffer, and works out of the box with any foundation model. LayUP improves over the state-of-the-art on four of the seven class-incremental learning settings at a considerably reduced memory and computational footprint compared with the next best baseline. Our results demonstrate that fully exhausting the representational capacities of pre-trained models in CL goes far beyond their final embeddings.
Visually Grounded Continual Language Learning with Selective Specialization
Oct 24, 2023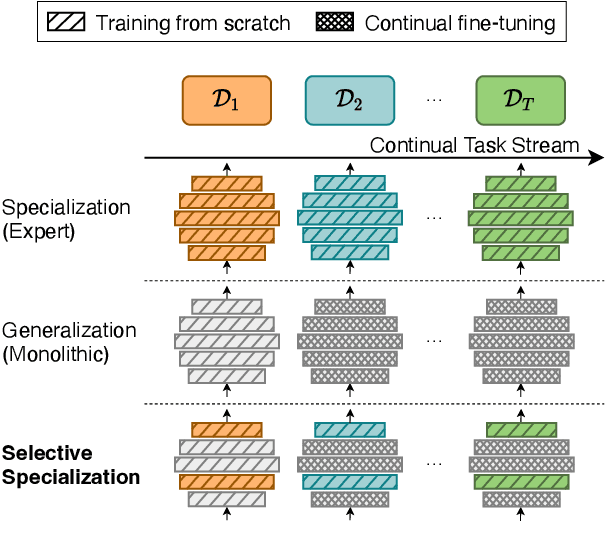
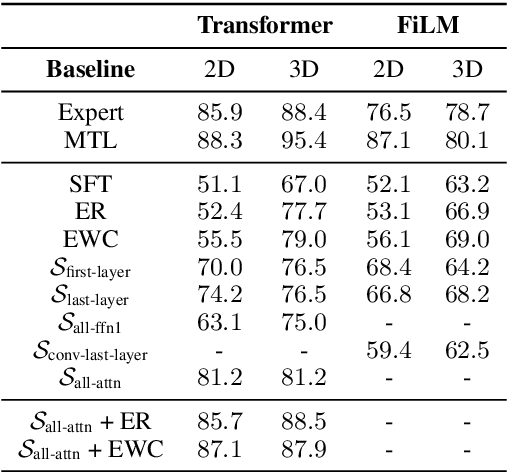
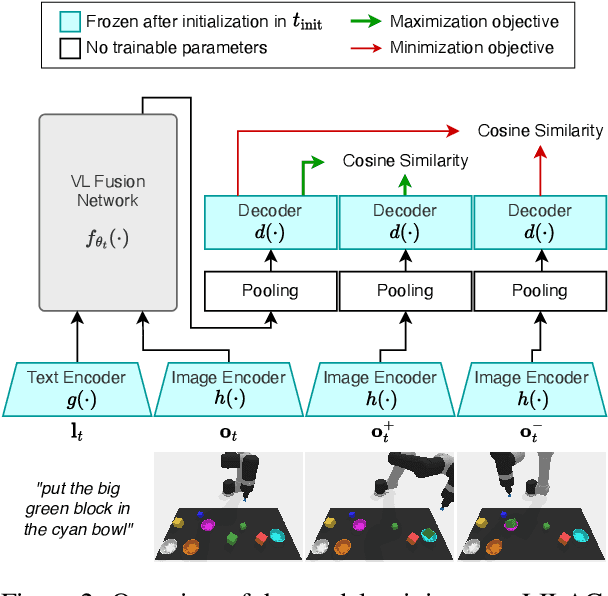
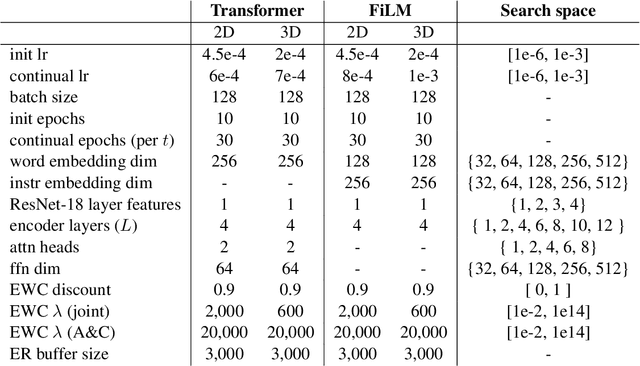
A desirable trait of an artificial agent acting in the visual world is to continually learn a sequence of language-informed tasks while striking a balance between sufficiently specializing in each task and building a generalized knowledge for transfer. Selective specialization, i.e., a careful selection of model components to specialize in each task, is a strategy to provide control over this trade-off. However, the design of selection strategies requires insights on the role of each model component in learning rather specialized or generalizable representations, which poses a gap in current research. Thus, our aim with this work is to provide an extensive analysis of selection strategies for visually grounded continual language learning. Due to the lack of suitable benchmarks for this purpose, we introduce two novel diagnostic datasets that provide enough control and flexibility for a thorough model analysis. We assess various heuristics for module specialization strategies as well as quantifiable measures for two different types of model architectures. Finally, we design conceptually simple approaches based on our analysis that outperform common continual learning baselines. Our results demonstrate the need for further efforts towards better aligning continual learning algorithms with the learning behaviors of individual model parts.
From Neural Activations to Concepts: A Survey on Explaining Concepts in Neural Networks
Oct 18, 2023In this paper, we review recent approaches for explaining concepts in neural networks. Concepts can act as a natural link between learning and reasoning: once the concepts are identified that a neural learning system uses, one can integrate those concepts with a reasoning system for inference or use a reasoning system to act upon them to improve or enhance the learning system. On the other hand, knowledge can not only be extracted from neural networks but concept knowledge can also be inserted into neural network architectures. Since integrating learning and reasoning is at the core of neuro-symbolic AI, the insights gained from this survey can serve as an important step towards realizing neuro-symbolic AI based on explainable concepts.
Enhancing Zero-Shot Chain-of-Thought Reasoning in Large Language Models through Logic
Sep 23, 2023Recent advancements in large language models have showcased their remarkable generalizability across various domains. However, their reasoning abilities still have significant room for improvement, especially when confronted with scenarios requiring multi-step reasoning. Although large language models possess extensive knowledge, their behavior, particularly in terms of reasoning, often fails to effectively utilize this knowledge to establish a coherent thinking paradigm. Generative language models sometimes show hallucinations as their reasoning procedures are unconstrained by logical principles. Aiming to improve the zero-shot chain-of-thought reasoning ability of large language models, we propose Logical Chain-of-Thought (LogiCoT), a neurosymbolic framework that leverages principles from symbolic logic to verify and revise the reasoning processes accordingly. Experimental evaluations conducted on language tasks in diverse domains, including arithmetic, commonsense, symbolic, causal inference, and social problems, demonstrate the efficacy of the enhanced reasoning paradigm by logic.
Internally Rewarded Reinforcement Learning
Feb 01, 2023



We study a class of reinforcement learning problems where the reward signals for policy learning are generated by a discriminator that is dependent on and jointly optimized with the policy. This interdependence between the policy and the discriminator leads to an unstable learning process because reward signals from an immature discriminator are noisy and impede policy learning, and conversely, an untrained policy impedes discriminator learning. We call this learning setting $\textit{Internally Rewarded Reinforcement Learning}$ (IRRL) as the reward is not provided directly by the environment but $\textit{internally}$ by the discriminator. In this paper, we formally formulate IRRL and present a class of problems that belong to IRRL. We theoretically derive and empirically analyze the effect of the reward function in IRRL and based on these analyses propose the clipped linear reward function. Experimental results show that the proposed reward function can consistently stabilize the training process by reducing the impact of reward noise, which leads to faster convergence and higher performance compared with baselines in diverse tasks.
Learning Bidirectional Action-Language Translation with Limited Supervision and Incongruent Extra Input
Jan 09, 2023Human infant learning happens during exploration of the environment, by interaction with objects, and by listening to and repeating utterances casually, which is analogous to unsupervised learning. Only occasionally, a learning infant would receive a matching verbal description of an action it is committing, which is similar to supervised learning. Such a learning mechanism can be mimicked with deep learning. We model this weakly supervised learning paradigm using our Paired Gated Autoencoders (PGAE) model, which combines an action and a language autoencoder. After observing a performance drop when reducing the proportion of supervised training, we introduce the Paired Transformed Autoencoders (PTAE) model, using Transformer-based crossmodal attention. PTAE achieves significantly higher accuracy in language-to-action and action-to-language translations, particularly in realistic but difficult cases when only few supervised training samples are available. We also test whether the trained model behaves realistically with conflicting multimodal input. In accordance with the concept of incongruence in psychology, conflict deteriorates the model output. Conflicting action input has a more severe impact than conflicting language input, and more conflicting features lead to larger interference. PTAE can be trained on mostly unlabelled data where labeled data is scarce, and it behaves plausibly when tested with incongruent input.
Harnessing the Power of Multi-Task Pretraining for Ground-Truth Level Natural Language Explanations
Dec 08, 2022Natural language explanations promise to offer intuitively understandable explanations of a neural network's decision process in complex vision-language tasks, as pursued in recent VL-NLE models. While current models offer impressive performance on task accuracy and explanation plausibility, they suffer from a range of issues: Some models feature a modular design where the explanation generation module is poorly integrated with a separate module for task-answer prediction, employ backbone models trained on limited sets of tasks, or incorporate ad hoc solutions to increase performance on single datasets. We propose to evade these limitations by applying recent advances in large-scale multi-task pretraining of generative Transformer models to the problem of VL-NLE tasks. Our approach outperforms recent models by a large margin, with human annotators preferring the generated explanations over the ground truth in two out of three evaluated datasets. As a novel challenge in VL-NLE research, we propose the problem of multi-task VL-NLE and show that jointly training on multiple tasks can increase the explanation quality. We discuss the ethical implications of high-quality NLE generation and other issues in recent VL-NLE research.