 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA computational model of infant sensorimotor exploration in the mobile paradigm
Apr 24, 2025



We present a computational model of the mechanisms that may determine infants' behavior in the "mobile paradigm". This paradigm has been used in developmental psychology to explore how infants learn the sensory effects of their actions. In this paradigm, a mobile (an articulated and movable object hanging above an infant's crib) is connected to one of the infant's limbs, prompting the infant to preferentially move that "connected" limb. This ability to detect a "sensorimotor contingency" is considered to be a foundational cognitive ability in development. To understand how infants learn sensorimotor contingencies, we built a model that attempts to replicate infant behavior. Our model incorporates a neural network, action-outcome prediction, exploration, motor noise, preferred activity level, and biologically-inspired motor control. We find that simulations with our model replicate the classic findings in the literature showing preferential movement of the connected limb. An interesting observation is that the model sometimes exhibits a burst of movement after the mobile is disconnected, casting light on a similar occasional finding in infants. In addition to these general findings, the simulations also replicate data from two recent more detailed studies using a connection with the mobile that was either gradual or all-or-none. A series of ablation studies further shows that the inclusion of mechanisms of action-outcome prediction, exploration, motor noise, and biologically-inspired motor control was essential for the model to correctly replicate infant behavior. This suggests that these components are also involved in infants' sensorimotor learning.
DIRIGENt: End-To-End Robotic Imitation of Human Demonstrations Based on a Diffusion Model
Jan 28, 2025There has been substantial progress in humanoid robots, with new skills continuously being taught, ranging from navigation to manipulation. While these abilities may seem impressive, the teaching methods often remain inefficient. To enhance the process of teaching robots, we propose leveraging a mechanism effectively used by humans: teaching by demonstrating. In this paper, we introduce DIRIGENt (DIrect Robotic Imitation GENeration model), a novel end-to-end diffusion approach that directly generates joint values from observing human demonstrations, enabling a robot to imitate these actions without any existing mapping between it and humans. We create a dataset in which humans imitate a robot and then use this collected data to train a diffusion model that enables a robot to imitate humans. The following three aspects are the core of our contribution. First is our novel dataset with natural pairs between human and robot poses, allowing our approach to imitate humans accurately despite the gap between their anatomies. Second, the diffusion input to our model alleviates the challenge of redundant joint configurations, limiting the search space. And finally, our end-to-end architecture from perception to action leads to an improved learning capability. Through our experimental analysis, we show that combining these three aspects allows DIRIGENt to outperform existing state-of-the-art approaches in the field of generating joint values from RGB images.
Mental Modeling of Reinforcement Learning Agents by Language Models
Jun 26, 2024



Can emergent language models faithfully model the intelligence of decision-making agents? Though modern language models exhibit already some reasoning ability, and theoretically can potentially express any probable distribution over tokens, it remains underexplored how the world knowledge these pretrained models have memorized can be utilized to comprehend an agent's behaviour in the physical world. This study empirically examines, for the first time, how well large language models (LLMs) can build a mental model of agents, termed agent mental modelling, by reasoning about an agent's behaviour and its effect on states from agent interaction history. This research may unveil the potential of leveraging LLMs for elucidating RL agent behaviour, addressing a key challenge in eXplainable reinforcement learning (XRL). To this end, we propose specific evaluation metrics and test them on selected RL task datasets of varying complexity, reporting findings on agent mental model establishment. Our results disclose that LLMs are not yet capable of fully mental modelling agents through inference alone without further innovations. This work thus provides new insights into the capabilities and limitations of modern LLMs.
Diffusing in Someone Else's Shoes: Robotic Perspective Taking with Diffusion
Apr 11, 2024Humanoid robots can benefit from their similarity to the human shape by learning from humans. When humans teach other humans how to perform actions, they often demonstrate the actions and the learning human can try to imitate the demonstration. Being able to mentally transfer from a demonstration seen from a third-person perspective to how it should look from a first-person perspective is fundamental for this ability in humans. As this is a challenging task, it is often simplified for robots by creating a demonstration in the first-person perspective. Creating these demonstrations requires more effort but allows for an easier imitation. We introduce a novel diffusion model aimed at enabling the robot to directly learn from the third-person demonstrations. Our model is capable of learning and generating the first-person perspective from the third-person perspective by translating the size and rotations of objects and the environment between two perspectives. This allows us to utilise the benefits of easy-to-produce third-person demonstrations and easy-to-imitate first-person demonstrations. The model can either represent the first-person perspective in an RGB image or calculate the joint values. Our approach significantly outperforms other image-to-image models in this task.
Robotic Imitation of Human Actions
Jan 16, 2024Imitation can allow us to quickly gain an understanding of a new task. Through a demonstration, we can gain direct knowledge about which actions need to be performed and which goals they have. In this paper, we introduce a new approach to imitation learning that tackles the challenges of a robot imitating a human, such as the change in perspective and body schema. Our approach can use a single human demonstration to abstract information about the demonstrated task, and use that information to generalise and replicate it. We facilitate this ability by a new integration of two state-of-the-art methods: a diffusion action segmentation model to abstract temporal information from the demonstration and an open vocabulary object detector for spatial information. Furthermore, we refine the abstracted information and use symbolic reasoning to create an action plan utilising inverse kinematics, to allow the robot to imitate the demonstrated action.
Clarifying the Half Full or Half Empty Question: Multimodal Container Classification
Jul 17, 2023
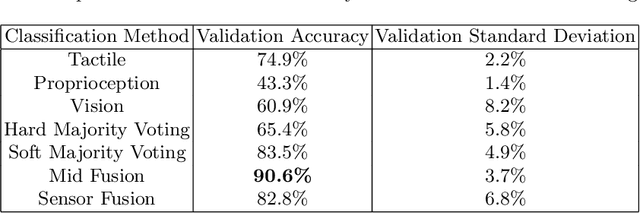
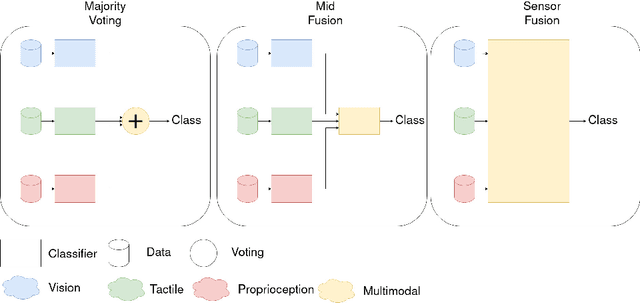

Multimodal integration is a key component of allowing robots to perceive the world. Multimodality comes with multiple challenges that have to be considered, such as how to integrate and fuse the data. In this paper, we compare different possibilities of fusing visual, tactile and proprioceptive data. The data is directly recorded on the NICOL robot in an experimental setup in which the robot has to classify containers and their content. Due to the different nature of the containers, the use of the modalities can wildly differ between the classes. We demonstrate the superiority of multimodal solutions in this use case and evaluate three fusion strategies that integrate the data at different time steps. We find that the accuracy of the best fusion strategy is 15% higher than the best strategy using only one singular sense.