 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Human-Inspired Thumb-Index Robotic Hand with Strain Gauges Embedded in Soft Joints
Jun 19, 2026Human hand grasp adaptation depends mainly on the synergy between physical structure and biological feedback. Inspired by this biomechanical principle, the Safe Thumb-Index Robotic (STIR) Hand was developed as a minimal, lightweight, and low-cost two-digit prototype featuring an asymmetric thumb-index configuration. By pairing an underactuated, tendon-driven mechanical design with flexible strain gauges embedded into silicone-encapsulated soft joints, the system achieves passive grasp adaptation while establishing both internal proprioception and external perception. Unsupervised analysis was carried out on a dataset of the STIR hand grasping 20 different objects, along with an object classification task and an ablation study to highlight the contribution of the soft joint sensors. The object classification task discriminated object size, shape, and material stiffness with a high classification accuracy. In contrast to traditional industrial grippers and robotic hands, the STIR Hand demonstrates that sensorized compliant joints significantly improve overall sensitivity and ensure safe grasping, while remaining independent of additional fingertip tactile elements or external vision systems. Finally, a comparison to similar devices grasping identical objects validates the utility of the STIR Hand.
Infant Spontaneous Movement Noise Improves Exploration in Deep RL
Jun 16, 2026Exploration in deep reinforcement learning (RL) is commonly implemented as temporally uncorrelated white noise. However, recent works show that temporally correlated colored noise can improve exploration efficiency by producing smooth trajectories with better coverage of the state space. We inquire whether action noise inspired by infant spontaneous movements can also improve exploration in deep RL. We find that the power spectral densities of babies' end-effector velocities follow a colored noise process where the spectral exponent increases with age. Inspired by this developmental pattern, we introduce a mechanism that progressively increases the temporal auto-correlation of exploration noise during RL training, matching the infant statistics. Experiments across several RL environments show that infant-inspired noise produces structured exploratory behavior and can improve learning efficiency compared to conventional exploration strategies. These findings suggest that human motor and cognitive development can provide useful guidance for designing learning mechanisms in artificial agents. Our code is available at https://github.com/trieschlab/baby-noise-rl.
Neuromorphic visual attention for Sign-language recognition on SpiNNaker
May 07, 2026Sign-language recognition has achieved substantial gains in classification accuracy in recent years; however, the latency and power requirements of most existing methods limit their suitability for real-time deployment. Neuromorphic sensing and processing offer an alternative paradigm based on sparse, event-driven computation that supports low-latency and energy-efficient perception. In this work, we introduce an end-to-end neuromorphic architecture for American Sign Language (ASL) fingerspelling recognition that integrates a spiking visual attention mechanism for online region-of-interest extraction with a compact spiking neural network deployed on the SpiNNaker neuromorphic platform. We benchmark the proposed system against two datasets: a synthetically generated event-based version of the Sign Language MNIST dataset and a natively recorded ASL-DVS dataset, whilst providing a comprehensive overview of Sign-language recognition and related work. This work yields competitive performance in simulation (92.27%) and comparable performance on neuromorphic hardware deployment (83.1%), while achieving the most energy-efficient architecture (0.565 mW) and low latency (3 ms) across all benchmarked approaches. Despite its compact design, the system demonstrates the suitability of task-dependent visual attention applications for edge deployment.
ShapeGrasp: Simultaneous Visuo-Haptic Shape Completion and Grasping for Improved Robot Manipulation
May 04, 2026Humans grasp unfamiliar objects by combining an initial visual estimate with tactile and proprioceptive feedback during interaction. We present ShapeGrasp, a robotic implementation of this approach. The proposed method is an iterative grasp-and-complete pipeline that couples implicit surface visuo-haptic shape completion (creation of full 3D shape from partial information) with physics-based grasp planning. From a single RGB-D view, ShapeGrasp infers a complete shape (point cloud or triangular mesh), generates candidate grasps via rigid-body simulation, and executes the best feasible grasp. Each grasp attempt yields additional geometric constraints -- tactile surface contacts and space occupied by the gripper body -- which are fused to update the object shape. Failures trigger pose re-estimation and regrasping using the refined shape. We evaluate ShapeGrasp in the real world using two different robots and grippers. To the best of our knowledge, this is the first approach that updates shape representations following a real-world grasp. We achieved superior results over baselines for both grippers (grasp success rate of 84% with a three-finger gripper and 91% with a two-finger gripper), while improving the 3D shape reconstruction quality in all evaluation metrics used.
The body is not there to compute: Comment on "Informational embodiment: Computational role of information structure in codes and robots" by Pitti et al
Dec 28, 2025Applying the lens of computation and information has been instrumental in driving the technological progress of our civilization as well as in empowering our understanding of the world around us. The digital computer was and for many still is the leading metaphor for how our mind operates. Information theory (IT) has also been important in our understanding of how nervous systems encode and process information. The target article deploys information and computation to bodies: to understand why they have evolved in particular ways (animal bodies) and to design optimal bodies (robots). In this commentary, I argue that the main role of bodies is not to compute.
* Comment on Pitti, A., Austin, M., Nakajima, K., & Kuniyoshi, Y. (2025). Informational Embodiment: Computational role of information structure in codes and robots. Physics of Life Reviews 53, 262-276. https://doi.org/10.1016/j.plrev.2025.03.018. Also available as arXiv:2408.12950
BLANKET: Anonymizing Faces in Infant Video Recordings
Dec 17, 2025



Ensuring the ethical use of video data involving human subjects, particularly infants, requires robust anonymization methods. We propose BLANKET (Baby-face Landmark-preserving ANonymization with Keypoint dEtection consisTency), a novel approach designed to anonymize infant faces in video recordings while preserving essential facial attributes. Our method comprises two stages. First, a new random face, compatible with the original identity, is generated via inpainting using a diffusion model. Second, the new identity is seamlessly incorporated into each video frame through temporally consistent face swapping with authentic expression transfer. The method is evaluated on a dataset of short video recordings of babies and is compared to the popular anonymization method, DeepPrivacy2. Key metrics assessed include the level of de-identification, preservation of facial attributes, impact on human pose estimation (as an example of a downstream task), and presence of artifacts. Both methods alter the identity, and our method outperforms DeepPrivacy2 in all other respects. The code is available as an easy-to-use anonymization demo at https://github.com/ctu-vras/blanket-infant-face-anonym.
* Project website: https://github.com/ctu-vras/blanket-infant-face-anonym
No Need to Look! Locating and Grasping Objects by a Robot Arm Covered with Sensitive Skin
Aug 25, 2025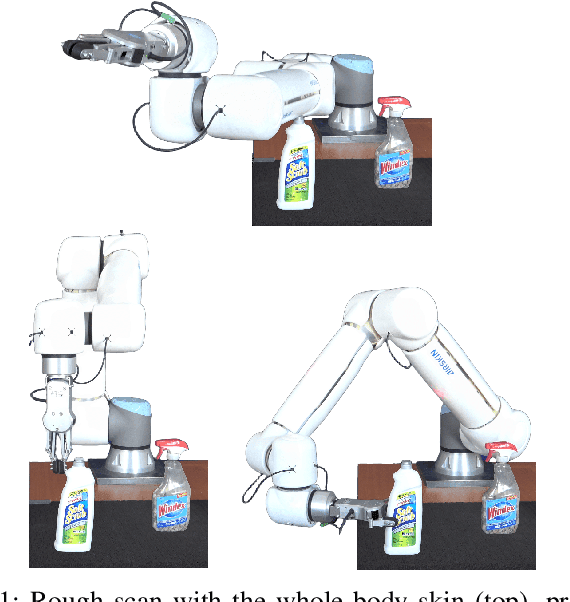

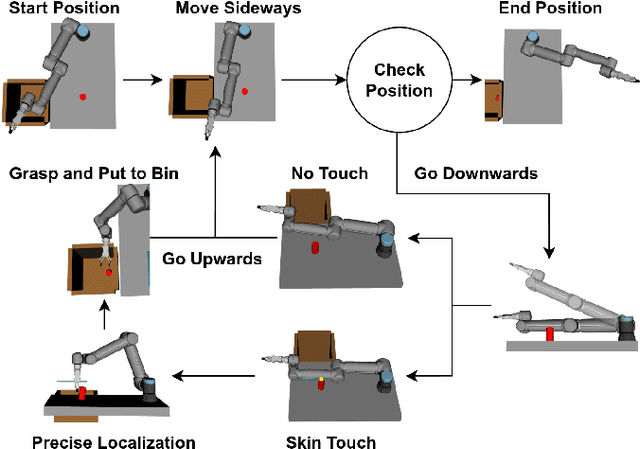
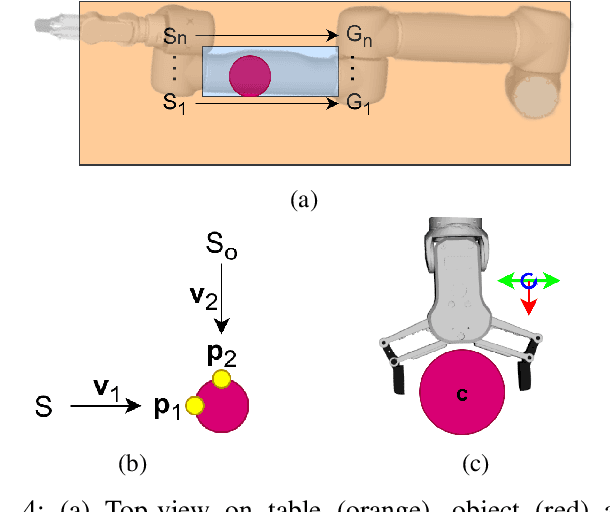
Locating and grasping of objects by robots is typically performed using visual sensors. Haptic feedback from contacts with the environment is only secondary if present at all. In this work, we explored an extreme case of searching for and grasping objects in complete absence of visual input, relying on haptic feedback only. The main novelty lies in the use of contacts over the complete surface of a robot manipulator covered with sensitive skin. The search is divided into two phases: (1) coarse workspace exploration with the complete robot surface, followed by (2) precise localization using the end-effector equipped with a force/torque sensor. We systematically evaluated this method in simulation and on the real robot, demonstrating that diverse objects can be located, grasped, and put in a basket. The overall success rate on the real robot for one object was 85.7\% with failures mainly while grasping specific objects. The method using whole-body contacts is six times faster compared to a baseline that uses haptic feedback only on the end-effector. We also show locating and grasping multiple objects on the table. This method is not restricted to our specific setup and can be deployed on any platform with the ability of sensing contacts over the entire body surface. This work holds promise for diverse applications in areas with challenging visual perception (due to lighting, dust, smoke, occlusion) such as in agriculture when fruits or vegetables need to be located inside foliage and picked.
Embodied AI in Machine Learning -- is it Really Embodied?
May 15, 2025


Embodied Artificial Intelligence (Embodied AI) is gaining momentum in the machine learning communities with the goal of leveraging current progress in AI (deep learning, transformers, large language and visual-language models) to empower robots. In this chapter we put this work in the context of "Good Old-Fashioned Artificial Intelligence" (GOFAI) (Haugeland, 1989) and the behavior-based or embodied alternatives (R. A. Brooks 1991; Pfeifer and Scheier 2001). We claim that the AI-powered robots are only weakly embodied and inherit some of the problems of GOFAI. Moreover, we review and critically discuss the possibility of cross-embodiment learning (Padalkar et al. 2024). We identify fundamental roadblocks and propose directions on how to make progress.
A computational model of infant sensorimotor exploration in the mobile paradigm
Apr 24, 2025



We present a computational model of the mechanisms that may determine infants' behavior in the "mobile paradigm". This paradigm has been used in developmental psychology to explore how infants learn the sensory effects of their actions. In this paradigm, a mobile (an articulated and movable object hanging above an infant's crib) is connected to one of the infant's limbs, prompting the infant to preferentially move that "connected" limb. This ability to detect a "sensorimotor contingency" is considered to be a foundational cognitive ability in development. To understand how infants learn sensorimotor contingencies, we built a model that attempts to replicate infant behavior. Our model incorporates a neural network, action-outcome prediction, exploration, motor noise, preferred activity level, and biologically-inspired motor control. We find that simulations with our model replicate the classic findings in the literature showing preferential movement of the connected limb. An interesting observation is that the model sometimes exhibits a burst of movement after the mobile is disconnected, casting light on a similar occasional finding in infants. In addition to these general findings, the simulations also replicate data from two recent more detailed studies using a connection with the mobile that was either gradual or all-or-none. A series of ablation studies further shows that the inclusion of mechanisms of action-outcome prediction, exploration, motor noise, and biologically-inspired motor control was essential for the model to correctly replicate infant behavior. This suggests that these components are also involved in infants' sensorimotor learning.
Robot Skin with Touch and Bend Sensing using Electrical Impedance Tomography
Mar 17, 2025Flexible electronic skins that simultaneously sense touch and bend are desired in several application areas, such as to cover articulated robot structures. This paper introduces a flexible tactile sensor based on Electrical Impedance Tomography (EIT), capable of simultaneously detecting and measuring contact forces and flexion of the sensor. The sensor integrates a magnetic hydrogel composite and utilizes EIT to reconstruct internal conductivity distributions. Real-time estimation is achieved through the one-step Gauss-Newton method, which dynamically updates reference voltages to accommodate sensor deformation. A convolutional neural network is employed to classify interactions, distinguishing between touch, bending, and idle states using pre-reconstructed images. Experimental results demonstrate an average touch localization error of 5.4 mm (SD 2.2 mm) and average bending angle estimation errors of 1.9$^\circ$ (SD 1.6$^\circ$). The proposed adaptive reference method effectively distinguishes between single- and multi-touch scenarios while compensating for deformation effects. This makes the sensor a promising solution for multimodal sensing in robotics and human-robot collaboration.