 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2025 challenge on Text to Image Generation Model Quality Assessment
May 22, 2025This paper reports on the NTIRE 2025 challenge on Text to Image (T2I) generation model quality assessment, which will be held in conjunction with the New Trends in Image Restoration and Enhancement Workshop (NTIRE) at CVPR 2025. The aim of this challenge is to address the fine-grained quality assessment of text-to-image generation models. This challenge evaluates text-to-image models from two aspects: image-text alignment and image structural distortion detection, and is divided into the alignment track and the structural track. The alignment track uses the EvalMuse-40K, which contains around 40K AI-Generated Images (AIGIs) generated by 20 popular generative models. The alignment track has a total of 371 registered participants. A total of 1,883 submissions are received in the development phase, and 507 submissions are received in the test phase. Finally, 12 participating teams submitted their models and fact sheets. The structure track uses the EvalMuse-Structure, which contains 10,000 AI-Generated Images (AIGIs) with corresponding structural distortion mask. A total of 211 participants have registered in the structure track. A total of 1155 submissions are received in the development phase, and 487 submissions are received in the test phase. Finally, 8 participating teams submitted their models and fact sheets. Almost all methods have achieved better results than baseline methods, and the winning methods in both tracks have demonstrated superior prediction performance on T2I model quality assessment.
Robot Skin with Touch and Bend Sensing using Electrical Impedance Tomography
Mar 17, 2025Flexible electronic skins that simultaneously sense touch and bend are desired in several application areas, such as to cover articulated robot structures. This paper introduces a flexible tactile sensor based on Electrical Impedance Tomography (EIT), capable of simultaneously detecting and measuring contact forces and flexion of the sensor. The sensor integrates a magnetic hydrogel composite and utilizes EIT to reconstruct internal conductivity distributions. Real-time estimation is achieved through the one-step Gauss-Newton method, which dynamically updates reference voltages to accommodate sensor deformation. A convolutional neural network is employed to classify interactions, distinguishing between touch, bending, and idle states using pre-reconstructed images. Experimental results demonstrate an average touch localization error of 5.4 mm (SD 2.2 mm) and average bending angle estimation errors of 1.9$^\circ$ (SD 1.6$^\circ$). The proposed adaptive reference method effectively distinguishes between single- and multi-touch scenarios while compensating for deformation effects. This makes the sensor a promising solution for multimodal sensing in robotics and human-robot collaboration.
Large-area Tomographic Tactile Skin with Air Pressure Sensing for Improved Force Estimation
Mar 17, 2025This paper presents a dual-channel tactile skin that integrates Electrical Impedance Tomography (EIT) with air pressure sensing to achieve accurate multi-contact force detection. The EIT layer provides spatial contact information, while the air pressure sensor delivers precise total force measurement. Our framework combines these complementary modalities through: deep learning-based EIT image reconstruction, contact area segmentation, and force allocation based on relative conductivity intensities from EIT. The experiments demonstrated 15.1% average force estimation error in single-contact scenarios and 20.1% in multi-contact scenarios without extensive calibration data requirements. This approach effectively addresses the challenge of simultaneously localizing and quantifying multiple contact forces without requiring complex external calibration setups, paving the way for practical and scalable soft robotic skin applications.
A Two-Stage Imaging Framework Combining CNN and Physics-Informed Neural Networks for Full-Inverse Tomography: A Case Study in Electrical Impedance Tomography (EIT)
Jul 25, 2024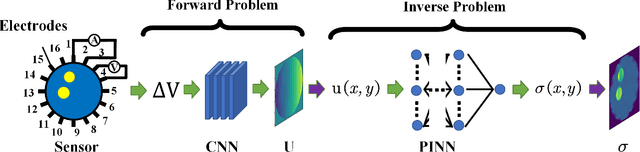
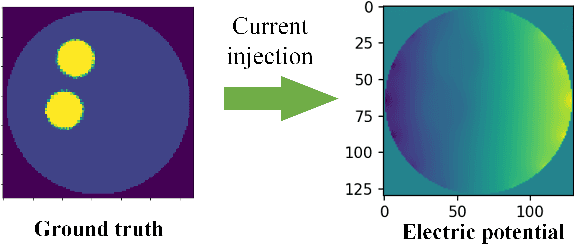
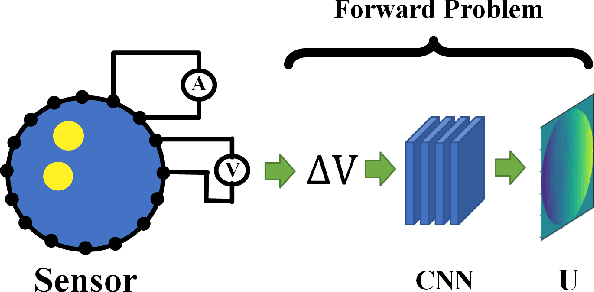
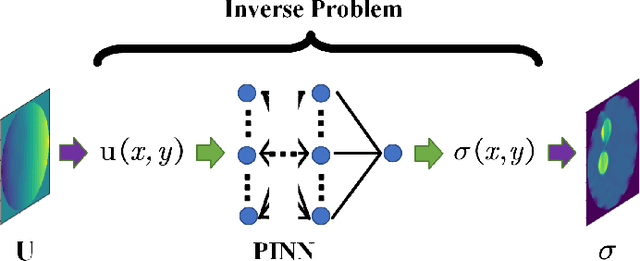
Physics-Informed Neural Networks (PINNs) are a machine learning technique for solving partial differential equations (PDEs) by incorporating PDEs as loss terms in neural networks and minimizing the loss function during training. Tomographic imaging, a method to reconstruct internal properties from external measurement data, is highly complex and ill-posed, making it an inverse problem. Recently, PINNs have shown significant potential in computational fluid dynamics (CFD) and have advantages in solving inverse problems. However, existing research has primarily focused on semi-inverse Electrical Impedance Tomography (EIT), where internal electric potentials are accessible. The practical full inverse EIT problem, where only boundary voltage measurements are available, remains challenging. To address this, we propose a two-stage hybrid learning framework combining Convolutional Neural Networks (CNNs) and PINNs to solve the full inverse EIT problem. This framework integrates data-driven and model-driven approaches, combines supervised and unsupervised learning, and decouples the forward and inverse problems within the PINN framework in EIT. Stage I: a U-Net constructs an end-to-end mapping from boundary voltage measurements to the internal potential distribution using supervised learning. Stage II: a Multilayer Perceptron (MLP)-based PINN takes the predicted internal potentials as input to solve for the conductivity distribution through unsupervised learning.
QDTrack: Quasi-Dense Similarity Learning for Appearance-Only Multiple Object Tracking
Oct 12, 2022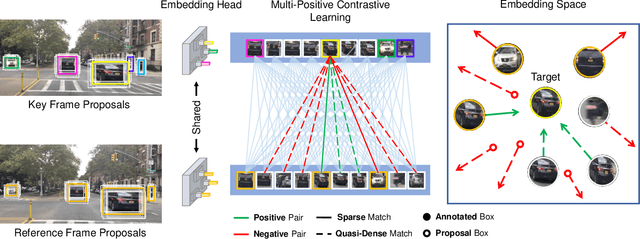
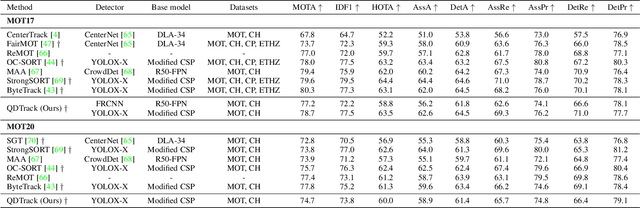
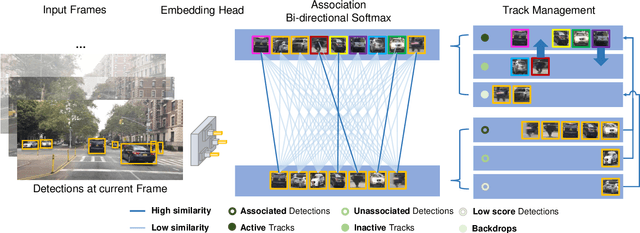
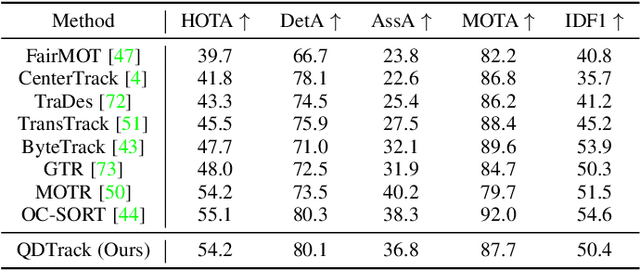
Similarity learning has been recognized as a crucial step for object tracking. However, existing multiple object tracking methods only use sparse ground truth matching as the training objective, while ignoring the majority of the informative regions in images. In this paper, we present Quasi-Dense Similarity Learning, which densely samples hundreds of object regions on a pair of images for contrastive learning. We combine this similarity learning with multiple existing object detectors to build Quasi-Dense Tracking (QDTrack), which does not require displacement regression or motion priors. We find that the resulting distinctive feature space admits a simple nearest neighbor search at inference time for object association. In addition, we show that our similarity learning scheme is not limited to video data, but can learn effective instance similarity even from static input, enabling a competitive tracking performance without training on videos or using tracking supervision. We conduct extensive experiments on a wide variety of popular MOT benchmarks. We find that, despite its simplicity, QDTrack rivals the performance of state-of-the-art tracking methods on all benchmarks and sets a new state-of-the-art on the large-scale BDD100K MOT benchmark, while introducing negligible computational overhead to the detector.
Home Action Genome: Cooperative Compositional Action Understanding
May 11, 2021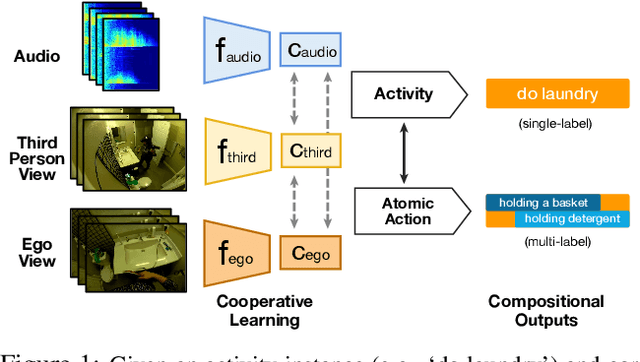


Existing research on action recognition treats activities as monolithic events occurring in videos. Recently, the benefits of formulating actions as a combination of atomic-actions have shown promise in improving action understanding with the emergence of datasets containing such annotations, allowing us to learn representations capturing this information. However, there remains a lack of studies that extend action composition and leverage multiple viewpoints and multiple modalities of data for representation learning. To promote research in this direction, we introduce Home Action Genome (HOMAGE): a multi-view action dataset with multiple modalities and view-points supplemented with hierarchical activity and atomic action labels together with dense scene composition labels. Leveraging rich multi-modal and multi-view settings, we propose Cooperative Compositional Action Understanding (CCAU), a cooperative learning framework for hierarchical action recognition that is aware of compositional action elements. CCAU shows consistent performance improvements across all modalities. Furthermore, we demonstrate the utility of co-learning compositions in few-shot action recognition by achieving 28.6% mAP with just a single sample.
Quasi-Dense Instance Similarity Learning
Jun 11, 2020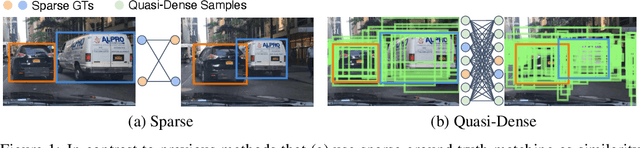



Similarity metrics for instances have drawn much attention, due to their importance for computer vision problems such as object tracking. However, existing methods regard object similarity learning as a post-hoc stage after object detection and only use sparse ground truth matching as the training objective. This process ignores the majority of the regions on the images. In this paper, we present a simple yet effective quasi-dense matching method to learn instance similarity from hundreds of region proposals in a pair of images. In the resulting feature space, a simple nearest neighbor search can distinguish different instances without bells and whistles. When applied to joint object detection and tracking, our method can outperform existing methods without using location or motion heuristics, yielding almost 10 points higher MOTA on BDD100K and Waymo tracking datasets. Our method is also competitive on one-shot object detection, which further shows the effectiveness of quasi-dense matching for category-level metric learning. The code will be available at https://github.com/sysmm/quasi-dense.
A Model that Predicts the Material Recognition Performance of Thermal Tactile Sensing
Nov 04, 2017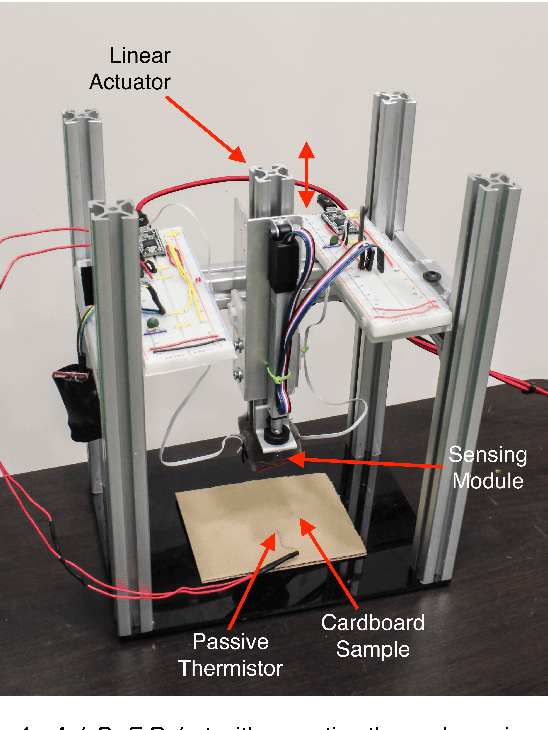
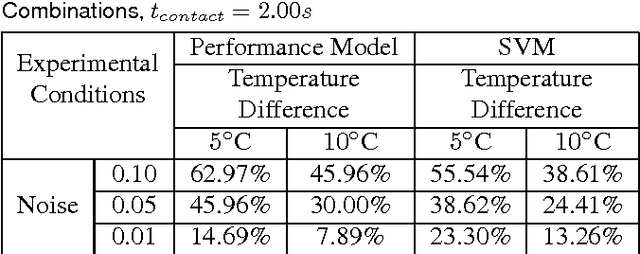
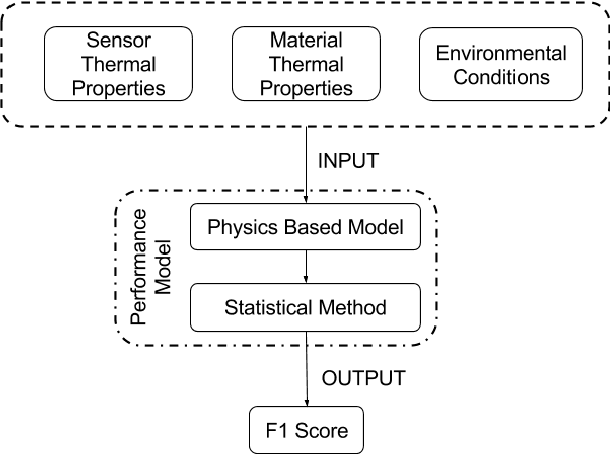
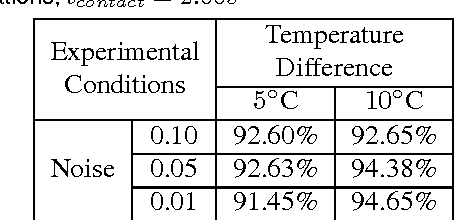
Tactile sensing can enable a robot to infer properties of its surroundings, such as the material of an object. Heat transfer based sensing can be used for material recognition due to differences in the thermal properties of materials. While data-driven methods have shown promise for this recognition problem, many factors can influence performance, including sensor noise, the initial temperatures of the sensor and the object, the thermal effusivities of the materials, and the duration of contact. We present a physics-based mathematical model that predicts material recognition performance given these factors. Our model uses semi-infinite solids and a statistical method to calculate an F1 score for the binary material recognition. We evaluated our method using simulated contact with 69 materials and data collected by a real robot with 12 materials. Our model predicted the material recognition performance of support vector machine (SVM) with 96% accuracy for the simulated data, with 92% accuracy for real-world data with constant initial sensor temperatures, and with 91% accuracy for real-world data with varied initial sensor temperatures. Using our model, we also provide insight into the roles of various factors on recognition performance, such as the temperature difference between the sensor and the object. Overall, our results suggest that our model could be used to help design better thermal sensors for robots and enable robots to use them more effectively.