 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
Home Action Genome: Cooperative Compositional Action Understanding
May 11, 2021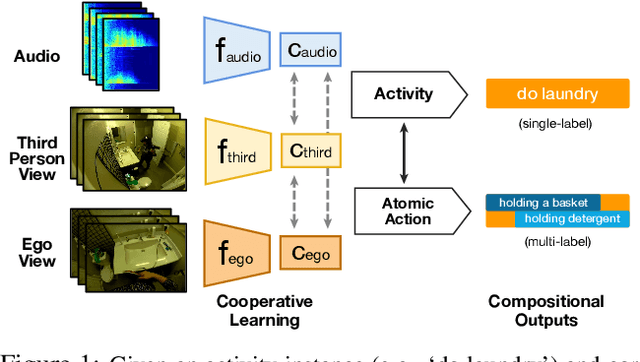
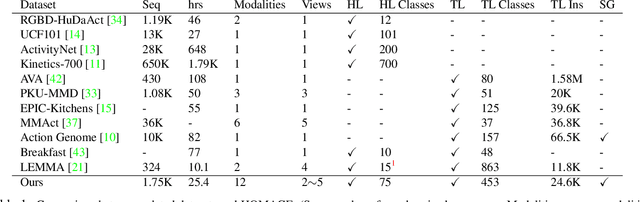


Existing research on action recognition treats activities as monolithic events occurring in videos. Recently, the benefits of formulating actions as a combination of atomic-actions have shown promise in improving action understanding with the emergence of datasets containing such annotations, allowing us to learn representations capturing this information. However, there remains a lack of studies that extend action composition and leverage multiple viewpoints and multiple modalities of data for representation learning. To promote research in this direction, we introduce Home Action Genome (HOMAGE): a multi-view action dataset with multiple modalities and view-points supplemented with hierarchical activity and atomic action labels together with dense scene composition labels. Leveraging rich multi-modal and multi-view settings, we propose Cooperative Compositional Action Understanding (CCAU), a cooperative learning framework for hierarchical action recognition that is aware of compositional action elements. CCAU shows consistent performance improvements across all modalities. Furthermore, we demonstrate the utility of co-learning compositions in few-shot action recognition by achieving 28.6% mAP with just a single sample.
Weak Multi-View Supervision for Surface Mapping Estimation
May 04, 2021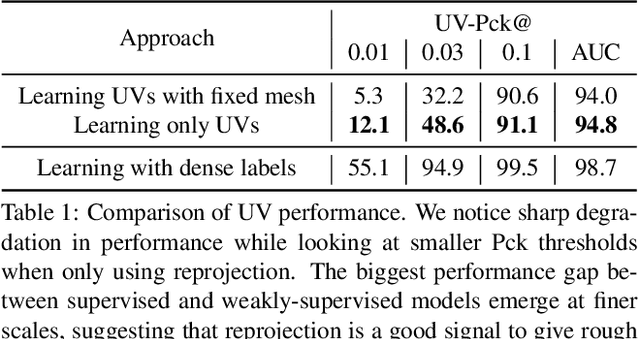
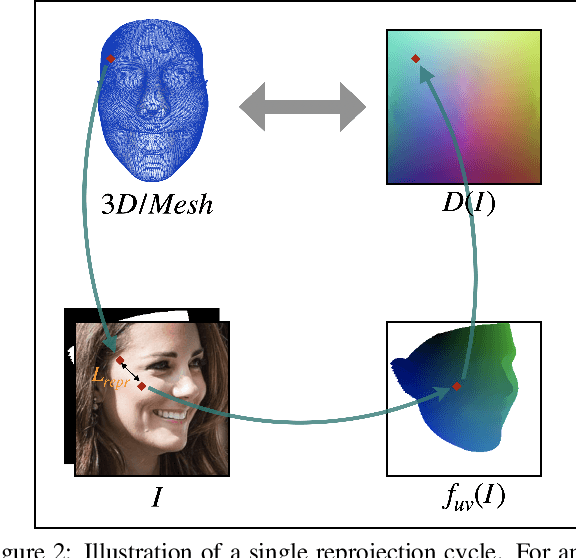
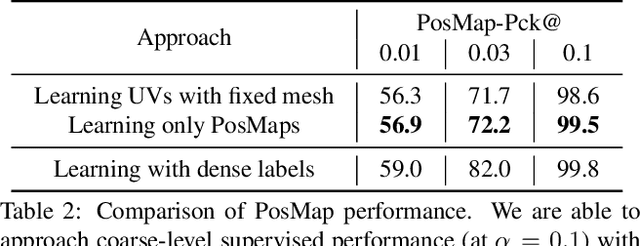

We propose a weakly-supervised multi-view learning approach to learn category-specific surface mapping without dense annotations. We learn the underlying surface geometry of common categories, such as human faces, cars, and airplanes, given instances from those categories. While traditional approaches solve this problem using extensive supervision in the form of pixel-level annotations, we take advantage of the fact that pixel-level UV and mesh predictions can be combined with 3D reprojections to form consistency cycles. As a result of exploiting these cycles, we can establish a dense correspondence mapping between image pixels and the mesh acting as a self-supervisory signal, which in turn helps improve our overall estimates. Our approach leverages information from multiple views of the object to establish additional consistency cycles, thus improving surface mapping understanding without the need for explicit annotations. We also propose the use of deformation fields for predictions of an instance specific mesh. Given the lack of datasets providing multiple images of similar object instances from different viewpoints, we generate and release a multi-view ShapeNet Cars and Airplanes dataset created by rendering ShapeNet meshes using a 360 degree camera trajectory around the mesh. For the human faces category, we process and adapt an existing dataset to a multi-view setup. Through experimental evaluations, we show that, at test time, our method can generate accurate variations away from the mean shape, is multi-view consistent, and performs comparably to fully supervised approaches.
CoCon: Cooperative-Contrastive Learning
Apr 30, 2021

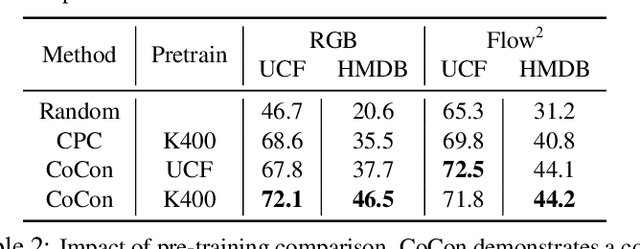
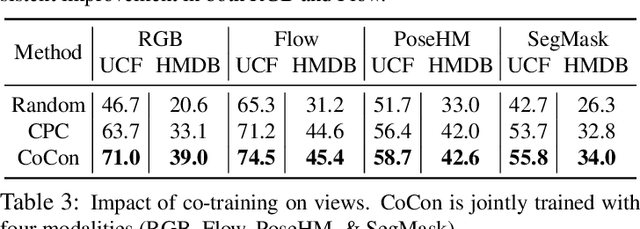
Labeling videos at scale is impractical. Consequently, self-supervised visual representation learning is key for efficient video analysis. Recent success in learning image representations suggests contrastive learning is a promising framework to tackle this challenge. However, when applied to real-world videos, contrastive learning may unknowingly lead to the separation of instances that contain semantically similar events. In our work, we introduce a cooperative variant of contrastive learning to utilize complementary information across views and address this issue. We use data-driven sampling to leverage implicit relationships between multiple input video views, whether observed (e.g. RGB) or inferred (e.g. flow, segmentation masks, poses). We are one of the firsts to explore exploiting inter-instance relationships to drive learning. We experimentally evaluate our representations on the downstream task of action recognition. Our method achieves competitive performance on standard benchmarks (UCF101, HMDB51, Kinetics400). Furthermore, qualitative experiments illustrate that our models can capture higher-order class relationships.
AdaScan: Adaptive Scan Pooling in Deep Convolutional Neural Networks for Human Action Recognition in Videos
Jun 25, 2017

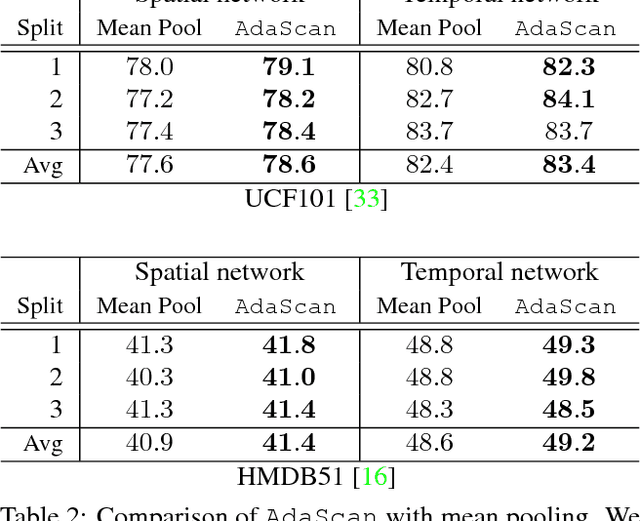
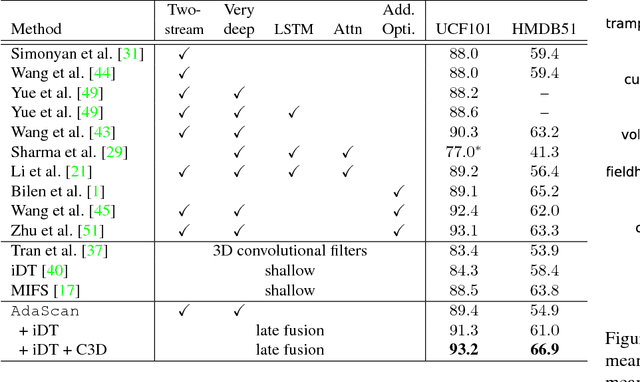
We propose a novel method for temporally pooling frames in a video for the task of human action recognition. The method is motivated by the observation that there are only a small number of frames which, together, contain sufficient information to discriminate an action class present in a video, from the rest. The proposed method learns to pool such discriminative and informative frames, while discarding a majority of the non-informative frames in a single temporal scan of the video. Our algorithm does so by continuously predicting the discriminative importance of each video frame and subsequently pooling them in a deep learning framework. We show the effectiveness of our proposed pooling method on standard benchmarks where it consistently improves on baseline pooling methods, with both RGB and optical flow based Convolutional networks. Further, in combination with complementary video representations, we show results that are competitive with respect to the state-of-the-art results on two challenging and publicly available benchmark datasets.