 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA multi-modal dataset for insect biodiversity with imagery and DNA at the trap and individual level
Jul 09, 2025Insects comprise millions of species, many experiencing severe population declines under environmental and habitat changes. High-throughput approaches are crucial for accelerating our understanding of insect diversity, with DNA barcoding and high-resolution imaging showing strong potential for automatic taxonomic classification. However, most image-based approaches rely on individual specimen data, unlike the unsorted bulk samples collected in large-scale ecological surveys. We present the Mixed Arthropod Sample Segmentation and Identification (MassID45) dataset for training automatic classifiers of bulk insect samples. It uniquely combines molecular and imaging data at both the unsorted sample level and the full set of individual specimens. Human annotators, supported by an AI-assisted tool, performed two tasks on bulk images: creating segmentation masks around each individual arthropod and assigning taxonomic labels to over 17 000 specimens. Combining the taxonomic resolution of DNA barcodes with precise abundance estimates of bulk images holds great potential for rapid, large-scale characterization of insect communities. This dataset pushes the boundaries of tiny object detection and instance segmentation, fostering innovation in both ecological and machine learning research.
Socratic-MCTS: Test-Time Visual Reasoning by Asking the Right Questions
Jun 10, 2025Recent research in vision-language models (VLMs) has centered around the possibility of equipping them with implicit long-form chain-of-thought reasoning -- akin to the success observed in language models -- via distillation and reinforcement learning. But what about the non-reasoning models already trained and deployed across the internet? Should we simply abandon them, or is there hope for a search mechanism that can elicit hidden knowledge and induce long reasoning traces -- without any additional training or supervision? In this paper, we explore this possibility using a Monte Carlo Tree Search (MCTS)-inspired algorithm, which injects subquestion-subanswer pairs into the model's output stream. We show that framing reasoning as a search process -- where subquestions act as latent decisions within a broader inference trajectory -- helps the model "connect the dots" between fragmented knowledge and produce extended reasoning traces in non-reasoning models. We evaluate our method across three benchmarks and observe consistent improvements. Notably, our approach yields a 2% overall improvement on MMMU-PRO, including a significant 9% gain in Liberal Arts.
Outdoor Scene Extrapolation with Hierarchical Generative Cellular Automata
Jun 12, 2024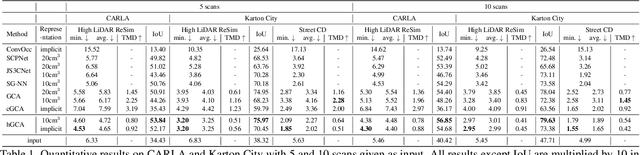
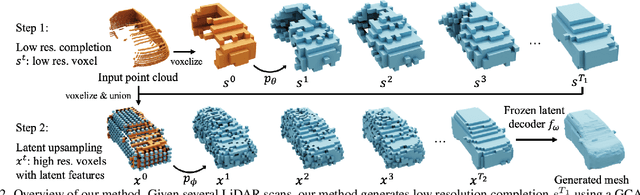
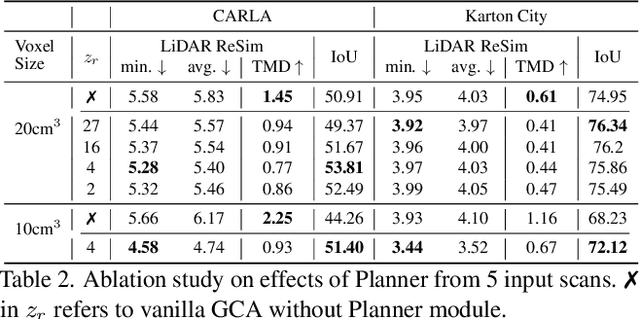
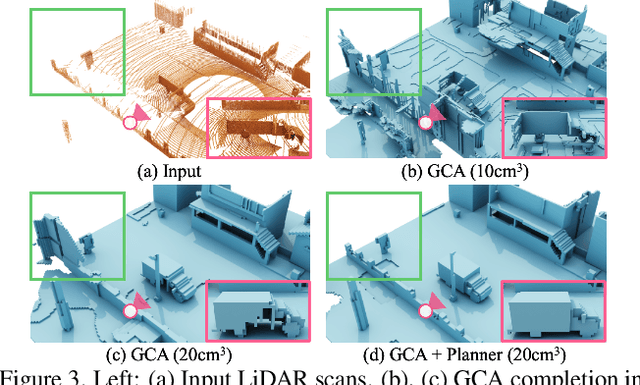
We aim to generate fine-grained 3D geometry from large-scale sparse LiDAR scans, abundantly captured by autonomous vehicles (AV). Contrary to prior work on AV scene completion, we aim to extrapolate fine geometry from unlabeled and beyond spatial limits of LiDAR scans, taking a step towards generating realistic, high-resolution simulation-ready 3D street environments. We propose hierarchical Generative Cellular Automata (hGCA), a spatially scalable conditional 3D generative model, which grows geometry recursively with local kernels following, in a coarse-to-fine manner, equipped with a light-weight planner to induce global consistency. Experiments on synthetic scenes show that hGCA generates plausible scene geometry with higher fidelity and completeness compared to state-of-the-art baselines. Our model generalizes strongly from sim-to-real, qualitatively outperforming baselines on the Waymo-open dataset. We also show anecdotal evidence of the ability to create novel objects from real-world geometric cues even when trained on limited synthetic content. More results and details can be found on https://research.nvidia.com/labs/toronto-ai/hGCA/.
DreamTeacher: Pretraining Image Backbones with Deep Generative Models
Jul 14, 2023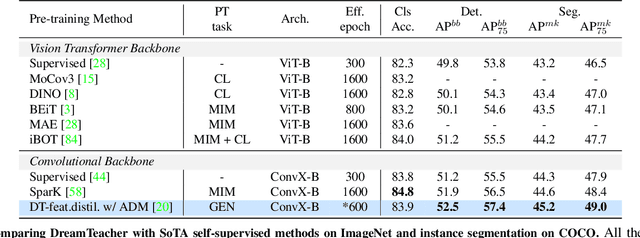
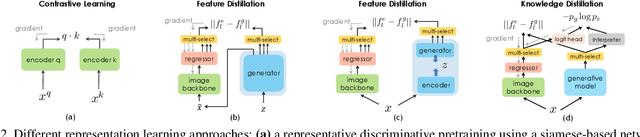
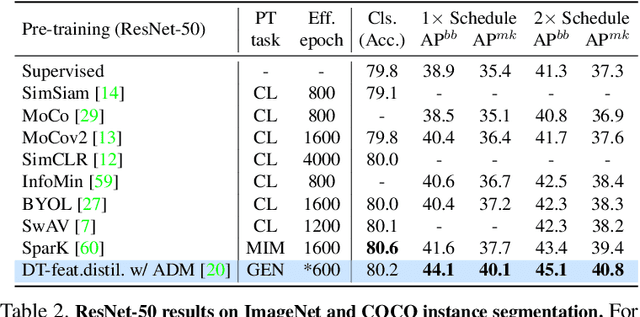
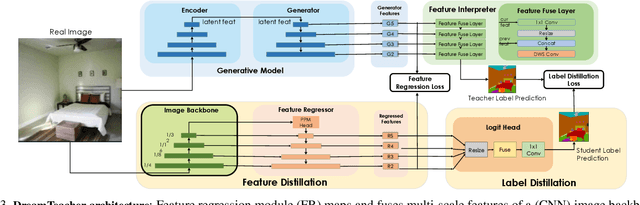
In this work, we introduce a self-supervised feature representation learning framework DreamTeacher that utilizes generative networks for pre-training downstream image backbones. We propose to distill knowledge from a trained generative model into standard image backbones that have been well engineered for specific perception tasks. We investigate two types of knowledge distillation: 1) distilling learned generative features onto target image backbones as an alternative to pretraining these backbones on large labeled datasets such as ImageNet, and 2) distilling labels obtained from generative networks with task heads onto logits of target backbones. We perform extensive analyses on multiple generative models, dense prediction benchmarks, and several pre-training regimes. We empirically find that our DreamTeacher significantly outperforms existing self-supervised representation learning approaches across the board. Unsupervised ImageNet pre-training with DreamTeacher leads to significant improvements over ImageNet classification pre-training on downstream datasets, showcasing generative models, and diffusion generative models specifically, as a promising approach to representation learning on large, diverse datasets without requiring manual annotation.
EPIC-KITCHENS VISOR Benchmark: VIdeo Segmentations and Object Relations
Sep 26, 2022
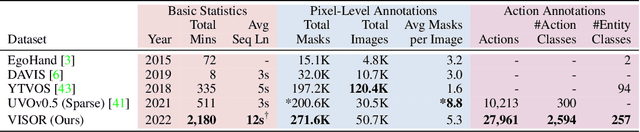
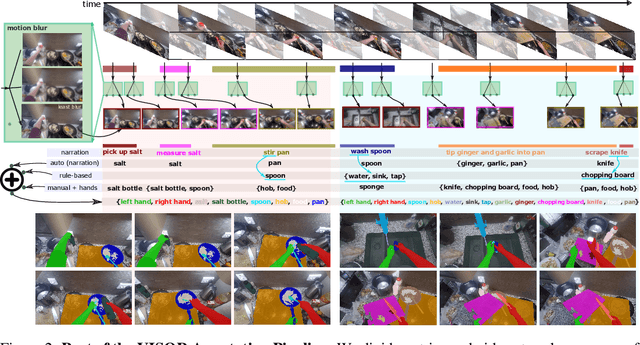
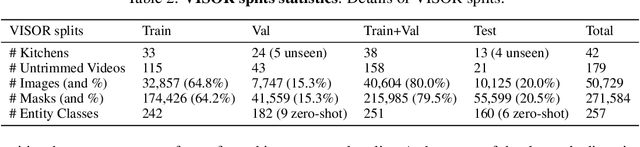
We introduce VISOR, a new dataset of pixel annotations and a benchmark suite for segmenting hands and active objects in egocentric video. VISOR annotates videos from EPIC-KITCHENS, which comes with a new set of challenges not encountered in current video segmentation datasets. Specifically, we need to ensure both short- and long-term consistency of pixel-level annotations as objects undergo transformative interactions, e.g. an onion is peeled, diced and cooked - where we aim to obtain accurate pixel-level annotations of the peel, onion pieces, chopping board, knife, pan, as well as the acting hands. VISOR introduces an annotation pipeline, AI-powered in parts, for scalability and quality. In total, we publicly release 272K manual semantic masks of 257 object classes, 9.9M interpolated dense masks, 67K hand-object relations, covering 36 hours of 179 untrimmed videos. Along with the annotations, we introduce three challenges in video object segmentation, interaction understanding and long-term reasoning. For data, code and leaderboards: http://epic-kitchens.github.io/VISOR
Causal Scene BERT: Improving object detection by searching for challenging groups of data
Feb 08, 2022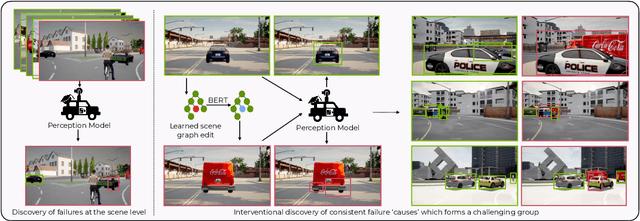
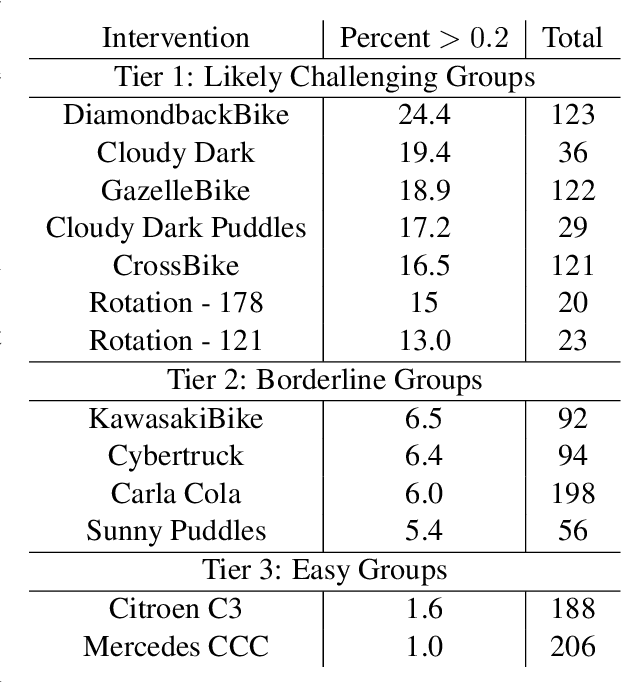
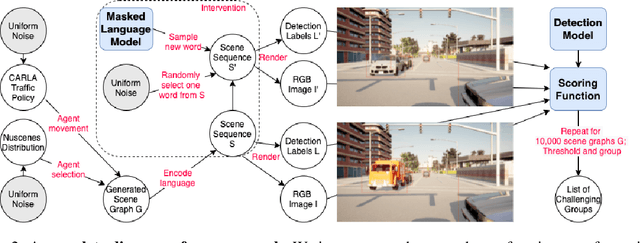
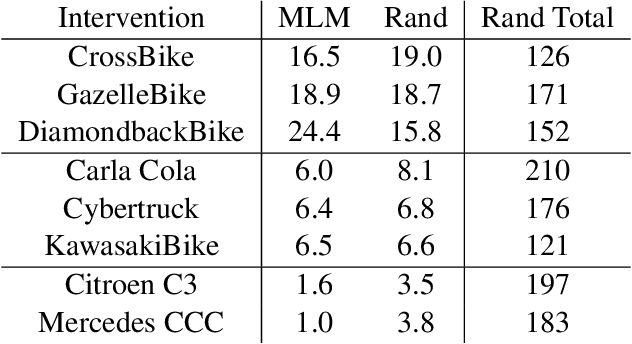
Modern computer vision applications rely on learning-based perception modules parameterized with neural networks for tasks like object detection. These modules frequently have low expected error overall but high error on atypical groups of data due to biases inherent in the training process. In building autonomous vehicles (AV), this problem is an especially important challenge because their perception modules are crucial to the overall system performance. After identifying failures in AV, a human team will comb through the associated data to group perception failures that share common causes. More data from these groups is then collected and annotated before retraining the model to fix the issue. In other words, error groups are found and addressed in hindsight. Our main contribution is a pseudo-automatic method to discover such groups in foresight by performing causal interventions on simulated scenes. To keep our interventions on the data manifold, we utilize masked language models. We verify that the prioritized groups found via intervention are challenging for the object detector and show that retraining with data collected from these groups helps inordinately compared to adding more IID data. We also plan to release software to run interventions in simulated scenes, which we hope will benefit the causality community.
ATISS: Autoregressive Transformers for Indoor Scene Synthesis
Oct 07, 2021

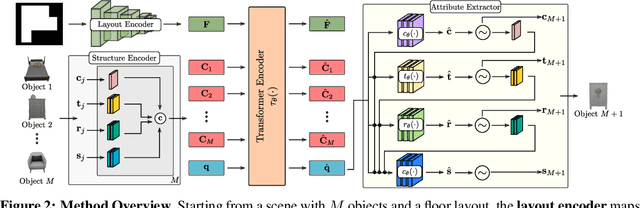
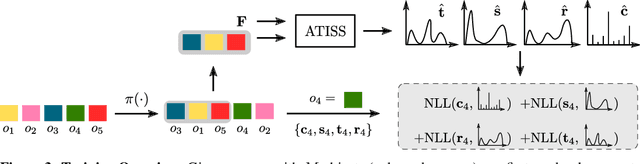
The ability to synthesize realistic and diverse indoor furniture layouts automatically or based on partial input, unlocks many applications, from better interactive 3D tools to data synthesis for training and simulation. In this paper, we present ATISS, a novel autoregressive transformer architecture for creating diverse and plausible synthetic indoor environments, given only the room type and its floor plan. In contrast to prior work, which poses scene synthesis as sequence generation, our model generates rooms as unordered sets of objects. We argue that this formulation is more natural, as it makes ATISS generally useful beyond fully automatic room layout synthesis. For example, the same trained model can be used in interactive applications for general scene completion, partial room re-arrangement with any objects specified by the user, as well as object suggestions for any partial room. To enable this, our model leverages the permutation equivariance of the transformer when conditioning on the partial scene, and is trained to be permutation-invariant across object orderings. Our model is trained end-to-end as an autoregressive generative model using only labeled 3D bounding boxes as supervision. Evaluations on four room types in the 3D-FRONT dataset demonstrate that our model consistently generates plausible room layouts that are more realistic than existing methods. In addition, it has fewer parameters, is simpler to implement and train and runs up to 8 times faster than existing methods.
Towards Good Practices for Efficiently Annotating Large-Scale Image Classification Datasets
Apr 26, 2021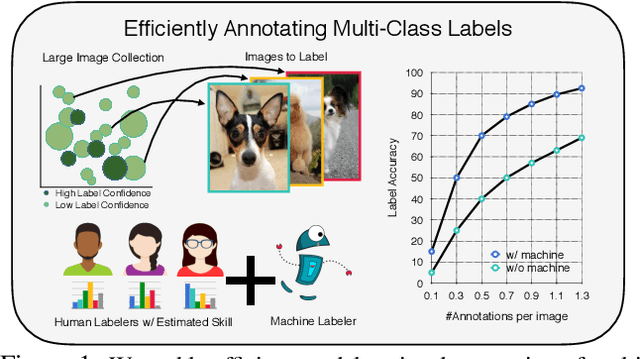

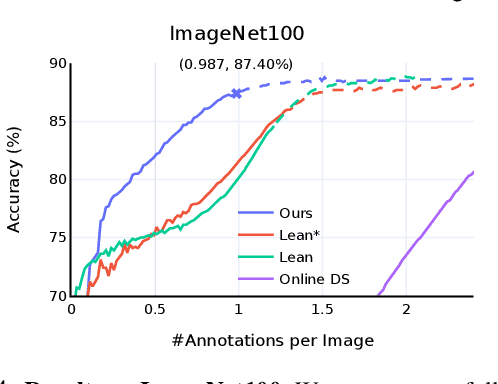
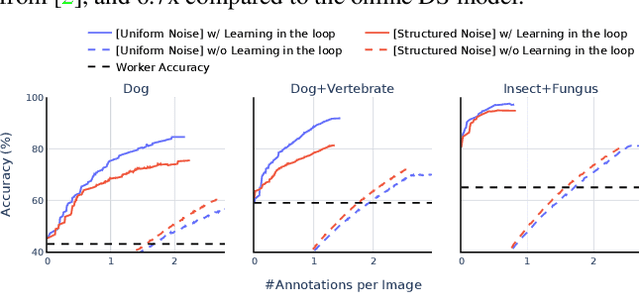
Data is the engine of modern computer vision, which necessitates collecting large-scale datasets. This is expensive, and guaranteeing the quality of the labels is a major challenge. In this paper, we investigate efficient annotation strategies for collecting multi-class classification labels for a large collection of images. While methods that exploit learnt models for labeling exist, a surprisingly prevalent approach is to query humans for a fixed number of labels per datum and aggregate them, which is expensive. Building on prior work on online joint probabilistic modeling of human annotations and machine-generated beliefs, we propose modifications and best practices aimed at minimizing human labeling effort. Specifically, we make use of advances in self-supervised learning, view annotation as a semi-supervised learning problem, identify and mitigate pitfalls and ablate several key design choices to propose effective guidelines for labeling. Our analysis is done in a more realistic simulation that involves querying human labelers, which uncovers issues with evaluation using existing worker simulation methods. Simulated experiments on a 125k image subset of the ImageNet100 show that it can be annotated to 80% top-1 accuracy with 0.35 annotations per image on average, a 2.7x and 6.7x improvement over prior work and manual annotation, respectively. Project page: https://fidler-lab.github.io/efficient-annotation-cookbook
Fed-Sim: Federated Simulation for Medical Imaging
Sep 01, 2020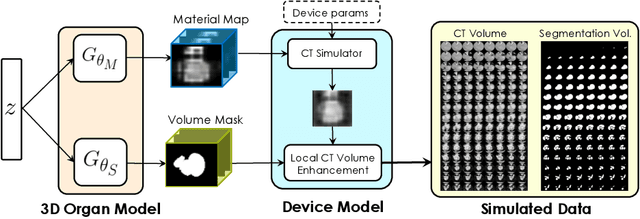
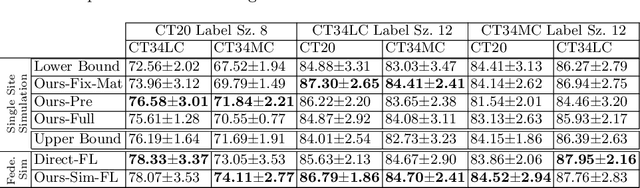

Labelling data is expensive and time consuming especially for domains such as medical imaging that contain volumetric imaging data and require expert knowledge. Exploiting a larger pool of labeled data available across multiple centers, such as in federated learning, has also seen limited success since current deep learning approaches do not generalize well to images acquired with scanners from different manufacturers. We aim to address these problems in a common, learning-based image simulation framework which we refer to as Federated Simulation. We introduce a physics-driven generative approach that consists of two learnable neural modules: 1) a module that synthesizes 3D cardiac shapes along with their materials, and 2) a CT simulator that renders these into realistic 3D CT Volumes, with annotations. Since the model of geometry and material is disentangled from the imaging sensor, it can effectively be trained across multiple medical centers. We show that our data synthesis framework improves the downstream segmentation performance on several datasets. Project Page: https://nv-tlabs.github.io/fed-sim/ .
Interactive Annotation of 3D Object Geometry using 2D Scribbles
Aug 24, 2020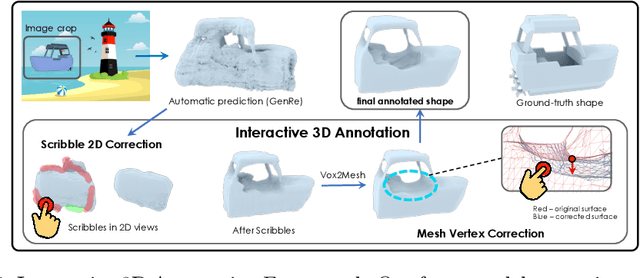
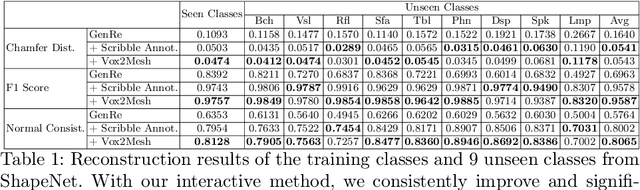
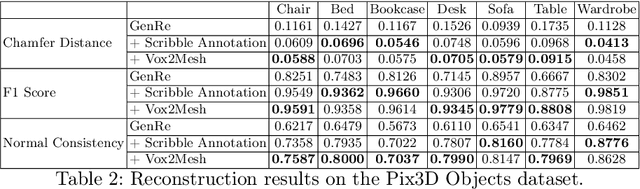
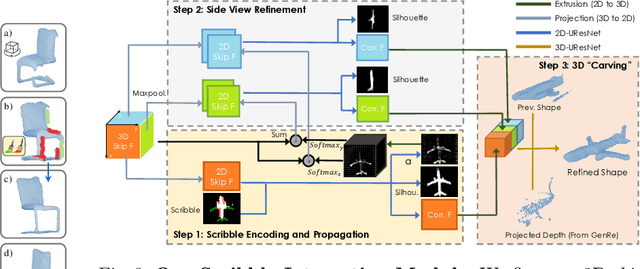
Inferring detailed 3D geometry of the scene is crucial for robotics applications, simulation, and 3D content creation. However, such information is hard to obtain, and thus very few datasets support it. In this paper, we propose an interactive framework for annotating 3D object geometry from both point cloud data and RGB imagery. The key idea behind our approach is to exploit strong priors that humans have about the 3D world in order to interactively annotate complete 3D shapes. Our framework targets naive users without artistic or graphics expertise. We introduce two simple-to-use interaction modules. First, we make an automatic guess of the 3D shape and allow the user to provide feedback about large errors by drawing scribbles in desired 2D views. Next, we aim to correct minor errors, in which users drag and drop mesh vertices, assisted by a neural interactive module implemented as a Graph Convolutional Network. Experimentally, we show that only a few user interactions are needed to produce good quality 3D shapes on popular benchmarks such as ShapeNet, Pix3D and ScanNet. We implement our framework as a web service and conduct a user study, where we show that user annotated data using our method effectively facilitates real-world learning tasks. Web service: http://www.cs.toronto.edu/~shenti11/scribble3d.