 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteractive Scene Authoring with Specialized Generative Primitives
Dec 20, 2024
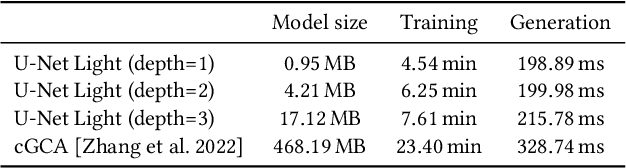
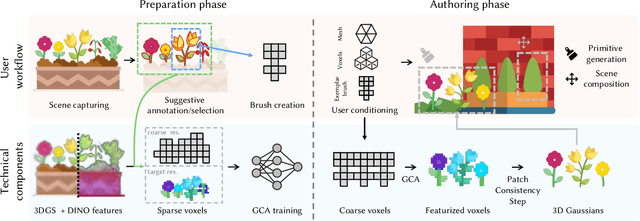
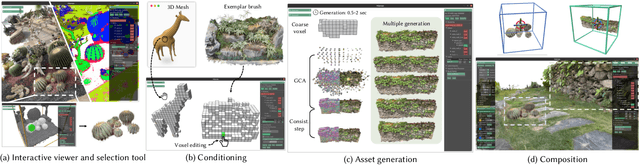
Generating high-quality 3D digital assets often requires expert knowledge of complex design tools. We introduce Specialized Generative Primitives, a generative framework that allows non-expert users to author high-quality 3D scenes in a seamless, lightweight, and controllable manner. Each primitive is an efficient generative model that captures the distribution of a single exemplar from the real world. With our framework, users capture a video of an environment, which we turn into a high-quality and explicit appearance model thanks to 3D Gaussian Splatting. Users then select regions of interest guided by semantically-aware features. To create a generative primitive, we adapt Generative Cellular Automata to single-exemplar training and controllable generation. We decouple the generative task from the appearance model by operating on sparse voxels and we recover a high-quality output with a subsequent sparse patch consistency step. Each primitive can be trained within 10 minutes and used to author new scenes interactively in a fully compositional manner. We showcase interactive sessions where various primitives are extracted from real-world scenes and controlled to create 3D assets and scenes in a few minutes. We also demonstrate additional capabilities of our primitives: handling various 3D representations to control generation, transferring appearances, and editing geometries.
Outdoor Scene Extrapolation with Hierarchical Generative Cellular Automata
Jun 12, 2024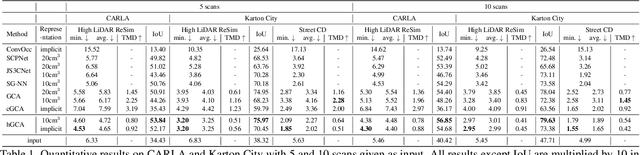
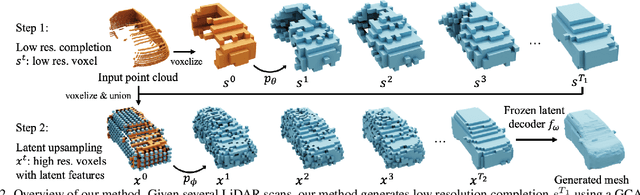
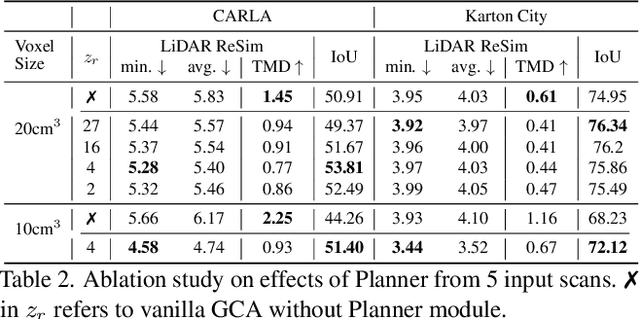
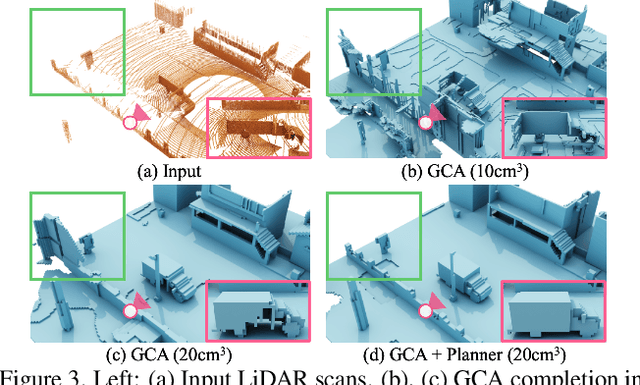
We aim to generate fine-grained 3D geometry from large-scale sparse LiDAR scans, abundantly captured by autonomous vehicles (AV). Contrary to prior work on AV scene completion, we aim to extrapolate fine geometry from unlabeled and beyond spatial limits of LiDAR scans, taking a step towards generating realistic, high-resolution simulation-ready 3D street environments. We propose hierarchical Generative Cellular Automata (hGCA), a spatially scalable conditional 3D generative model, which grows geometry recursively with local kernels following, in a coarse-to-fine manner, equipped with a light-weight planner to induce global consistency. Experiments on synthetic scenes show that hGCA generates plausible scene geometry with higher fidelity and completeness compared to state-of-the-art baselines. Our model generalizes strongly from sim-to-real, qualitatively outperforming baselines on the Waymo-open dataset. We also show anecdotal evidence of the ability to create novel objects from real-world geometric cues even when trained on limited synthetic content. More results and details can be found on https://research.nvidia.com/labs/toronto-ai/hGCA/.
Probabilistic Implicit Scene Completion
Apr 04, 2022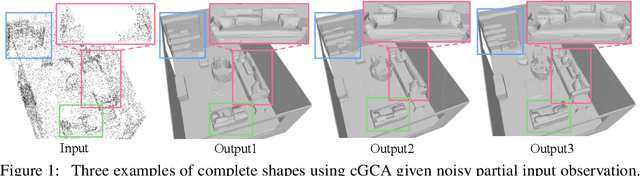
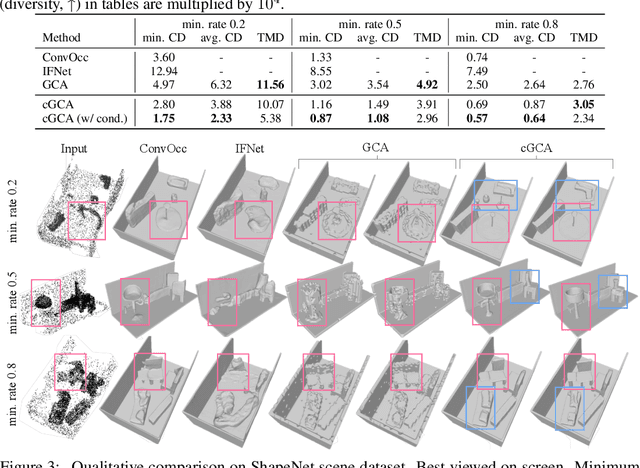
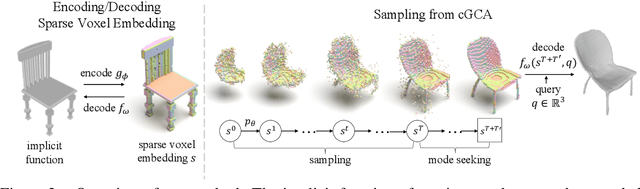

We propose a probabilistic shape completion method extended to the continuous geometry of large-scale 3D scenes. Real-world scans of 3D scenes suffer from a considerable amount of missing data cluttered with unsegmented objects. The problem of shape completion is inherently ill-posed, and high-quality result requires scalable solutions that consider multiple possible outcomes. We employ the Generative Cellular Automata that learns the multi-modal distribution and transform the formulation to process large-scale continuous geometry. The local continuous shape is incrementally generated as a sparse voxel embedding, which contains the latent code for each occupied cell. We formally derive that our training objective for the sparse voxel embedding maximizes the variational lower bound of the complete shape distribution and therefore our progressive generation constitutes a valid generative model. Experiments show that our model successfully generates diverse plausible scenes faithful to the input, especially when the input suffers from a significant amount of missing data. We also demonstrate that our approach outperforms deterministic models even in less ambiguous cases with a small amount of missing data, which infers that probabilistic formulation is crucial for high-quality geometry completion on input scans exhibiting any levels of completeness.
Learning to Generate 3D Shapes with Generative Cellular Automata
Mar 06, 2021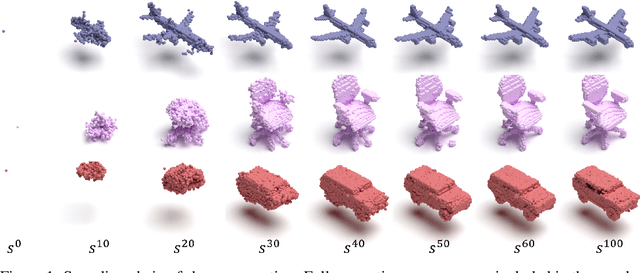
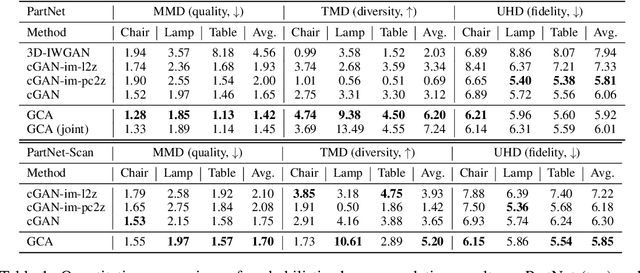
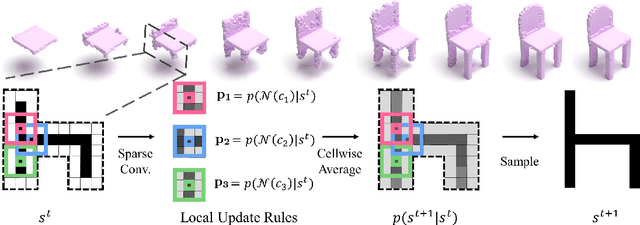
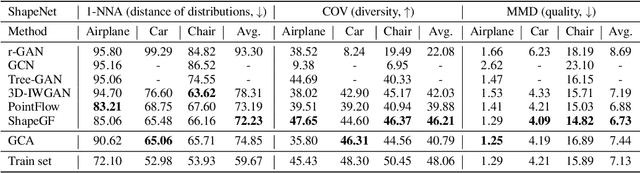
We present a probabilistic 3D generative model, named Generative Cellular Automata, which is able to produce diverse and high quality shapes. We formulate the shape generation process as sampling from the transition kernel of a Markov chain, where the sampling chain eventually evolves to the full shape of the learned distribution. The transition kernel employs the local update rules of cellular automata, effectively reducing the search space in a high-resolution 3D grid space by exploiting the connectivity and sparsity of 3D shapes. Our progressive generation only focuses on the sparse set of occupied voxels and their neighborhood, thus enabling the utilization of an expressive sparse convolutional network. We propose an effective training scheme to obtain the local homogeneous rule of generative cellular automata with sequences that are slightly different from the sampling chain but converge to the full shapes in the training data. Extensive experiments on probabilistic shape completion and shape generation demonstrate that our method achieves competitive performance against recent methods.
Spatial Semantic Embedding Network: Fast 3D Instance Segmentation with Deep Metric Learning
Jul 07, 2020
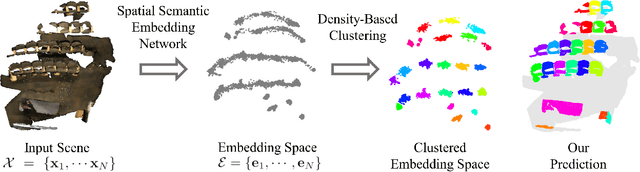


We propose spatial semantic embedding network (SSEN), a simple, yet efficient algorithm for 3D instance segmentation using deep metric learning. The raw 3D reconstruction of an indoor environment suffers from occlusions, noise, and is produced without any meaningful distinction between individual entities. For high-level intelligent tasks from a large scale scene, 3D instance segmentation recognizes individual instances of objects. We approach the instance segmentation by simply learning the correct embedding space that maps individual instances of objects into distinct clusters that reflect both spatial and semantic information. Unlike previous approaches that require complex pre-processing or post-processing, our implementation is compact and fast with competitive performance, maintaining scalability on large scenes with high resolution voxels. We demonstrate the state-of-the-art performance of our algorithm in the ScanNet 3D instance segmentation benchmark on AP score.
A Neural Dirichlet Process Mixture Model for Task-Free Continual Learning
Jan 14, 2020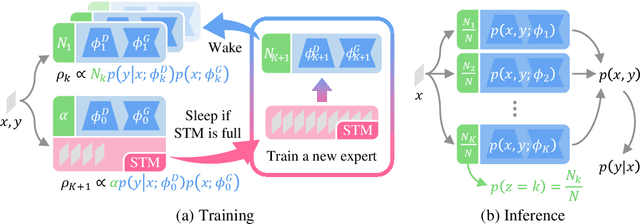
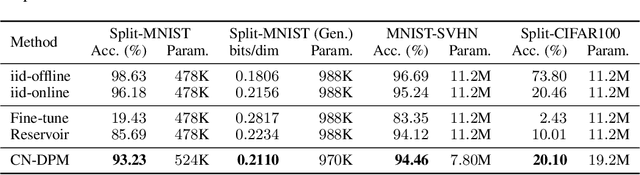
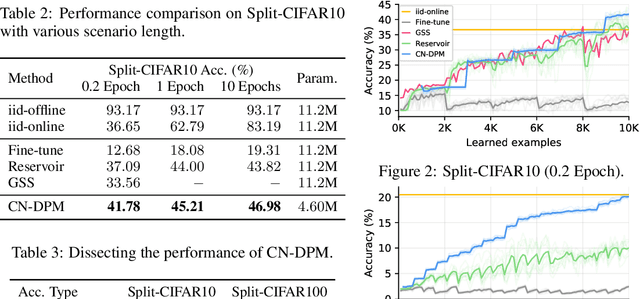
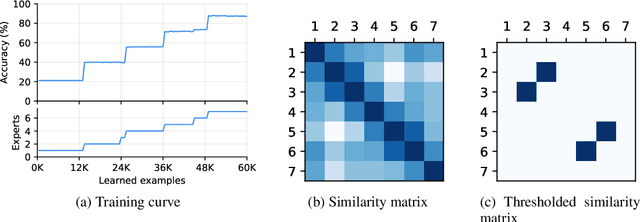
Despite the growing interest in continual learning, most of its contemporary works have been studied in a rather restricted setting where tasks are clearly distinguishable, and task boundaries are known during training. However, if our goal is to develop an algorithm that learns as humans do, this setting is far from realistic, and it is essential to develop a methodology that works in a task-free manner. Meanwhile, among several branches of continual learning, expansion-based methods have the advantage of eliminating catastrophic forgetting by allocating new resources to learn new data. In this work, we propose an expansion-based approach for task-free continual learning. Our model, named Continual Neural Dirichlet Process Mixture (CN-DPM), consists of a set of neural network experts that are in charge of a subset of the data. CN-DPM expands the number of experts in a principled way under the Bayesian nonparametric framework. With extensive experiments, we show that our model successfully performs task-free continual learning for both discriminative and generative tasks such as image classification and image generation.