 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuralSSD: A Neural Solver for Signed Distance Surface Reconstruction
Nov 18, 2025We proposed a generalized method, NeuralSSD, for reconstructing a 3D implicit surface from the widely-available point cloud data. NeuralSSD is a solver-based on the neural Galerkin method, aimed at reconstructing higher-quality and accurate surfaces from input point clouds. Implicit method is preferred due to its ability to accurately represent shapes and its robustness in handling topological changes. However, existing parameterizations of implicit fields lack explicit mechanisms to ensure a tight fit between the surface and input data. To address this, we propose a novel energy equation that balances the reliability of point cloud information. Additionally, we introduce a new convolutional network that learns three-dimensional information to achieve superior optimization results. This approach ensures that the reconstructed surface closely adheres to the raw input points and infers valuable inductive biases from point clouds, resulting in a highly accurate and stable surface reconstruction. NeuralSSD is evaluated on a variety of challenging datasets, including the ShapeNet and Matterport datasets, and achieves state-of-the-art results in terms of both surface reconstruction accuracy and generalizability.
SCube: Instant Large-Scale Scene Reconstruction using VoxSplats
Oct 26, 2024



We present SCube, a novel method for reconstructing large-scale 3D scenes (geometry, appearance, and semantics) from a sparse set of posed images. Our method encodes reconstructed scenes using a novel representation VoxSplat, which is a set of 3D Gaussians supported on a high-resolution sparse-voxel scaffold. To reconstruct a VoxSplat from images, we employ a hierarchical voxel latent diffusion model conditioned on the input images followed by a feedforward appearance prediction model. The diffusion model generates high-resolution grids progressively in a coarse-to-fine manner, and the appearance network predicts a set of Gaussians within each voxel. From as few as 3 non-overlapping input images, SCube can generate millions of Gaussians with a 1024^3 voxel grid spanning hundreds of meters in 20 seconds. Past works tackling scene reconstruction from images either rely on per-scene optimization and fail to reconstruct the scene away from input views (thus requiring dense view coverage as input) or leverage geometric priors based on low-resolution models, which produce blurry results. In contrast, SCube leverages high-resolution sparse networks and produces sharp outputs from few views. We show the superiority of SCube compared to prior art using the Waymo self-driving dataset on 3D reconstruction and demonstrate its applications, such as LiDAR simulation and text-to-scene generation.
fVDB: A Deep-Learning Framework for Sparse, Large-Scale, and High-Performance Spatial Intelligence
Jul 01, 2024



We present fVDB, a novel GPU-optimized framework for deep learning on large-scale 3D data. fVDB provides a complete set of differentiable primitives to build deep learning architectures for common tasks in 3D learning such as convolution, pooling, attention, ray-tracing, meshing, etc. fVDB simultaneously provides a much larger feature set (primitives and operators) than established frameworks with no loss in efficiency: our operators match or exceed the performance of other frameworks with narrower scope. Furthermore, fVDB can process datasets with much larger footprint and spatial resolution than prior works, while providing a competitive memory footprint on small inputs. To achieve this combination of versatility and performance, fVDB relies on a single novel VDB index grid acceleration structure paired with several key innovations including GPU accelerated sparse grid construction, convolution using tensorcores, fast ray tracing kernels using a Hierarchical Digital Differential Analyzer algorithm (HDDA), and jagged tensors. Our framework is fully integrated with PyTorch enabling interoperability with existing pipelines, and we demonstrate its effectiveness on a number of representative tasks such as large-scale point-cloud segmentation, high resolution 3D generative modeling, unbounded scale Neural Radiance Fields, and large-scale point cloud reconstruction.
Outdoor Scene Extrapolation with Hierarchical Generative Cellular Automata
Jun 12, 2024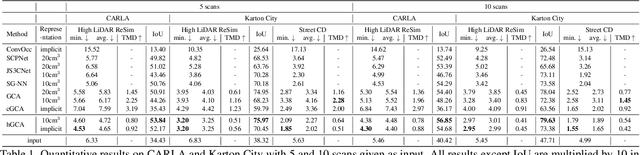
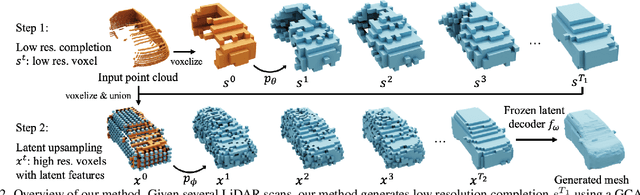
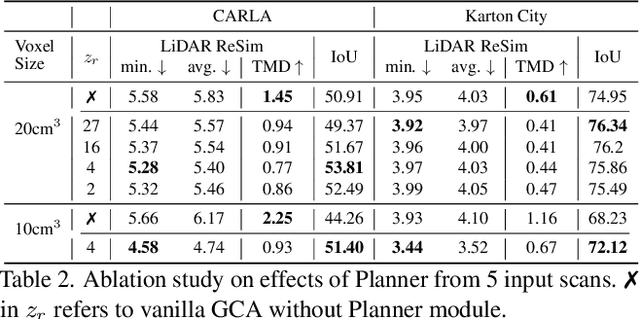
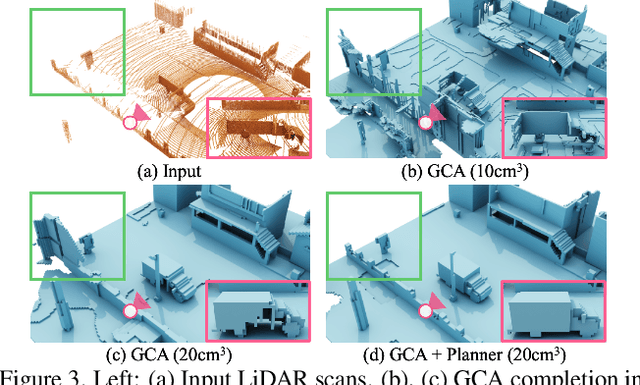
We aim to generate fine-grained 3D geometry from large-scale sparse LiDAR scans, abundantly captured by autonomous vehicles (AV). Contrary to prior work on AV scene completion, we aim to extrapolate fine geometry from unlabeled and beyond spatial limits of LiDAR scans, taking a step towards generating realistic, high-resolution simulation-ready 3D street environments. We propose hierarchical Generative Cellular Automata (hGCA), a spatially scalable conditional 3D generative model, which grows geometry recursively with local kernels following, in a coarse-to-fine manner, equipped with a light-weight planner to induce global consistency. Experiments on synthetic scenes show that hGCA generates plausible scene geometry with higher fidelity and completeness compared to state-of-the-art baselines. Our model generalizes strongly from sim-to-real, qualitatively outperforming baselines on the Waymo-open dataset. We also show anecdotal evidence of the ability to create novel objects from real-world geometric cues even when trained on limited synthetic content. More results and details can be found on https://research.nvidia.com/labs/toronto-ai/hGCA/.
NeRF-XL: Scaling NeRFs with Multiple GPUs
Apr 24, 2024


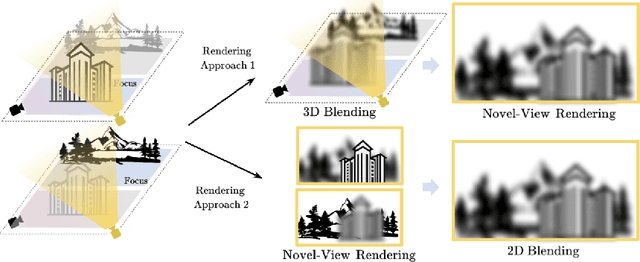
We present NeRF-XL, a principled method for distributing Neural Radiance Fields (NeRFs) across multiple GPUs, thus enabling the training and rendering of NeRFs with an arbitrarily large capacity. We begin by revisiting existing multi-GPU approaches, which decompose large scenes into multiple independently trained NeRFs, and identify several fundamental issues with these methods that hinder improvements in reconstruction quality as additional computational resources (GPUs) are used in training. NeRF-XL remedies these issues and enables the training and rendering of NeRFs with an arbitrary number of parameters by simply using more hardware. At the core of our method lies a novel distributed training and rendering formulation, which is mathematically equivalent to the classic single-GPU case and minimizes communication between GPUs. By unlocking NeRFs with arbitrarily large parameter counts, our approach is the first to reveal multi-GPU scaling laws for NeRFs, showing improvements in reconstruction quality with larger parameter counts and speed improvements with more GPUs. We demonstrate the effectiveness of NeRF-XL on a wide variety of datasets, including the largest open-source dataset to date, MatrixCity, containing 258K images covering a 25km^2 city area.
Approximately Piecewise E(3) Equivariant Point Networks
Feb 13, 2024
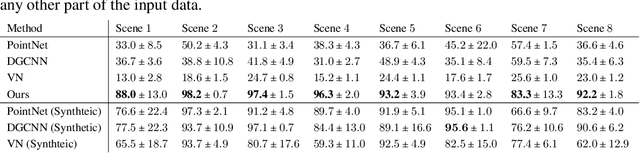
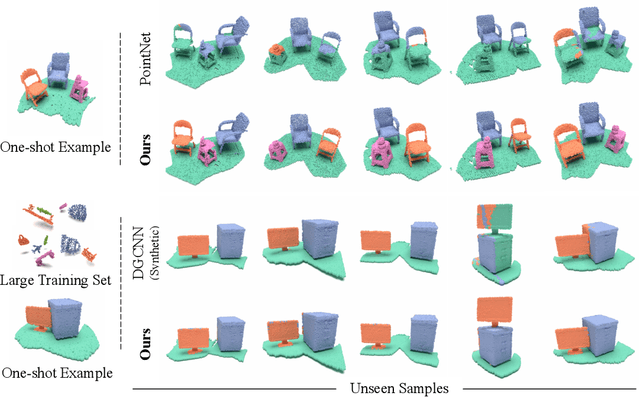
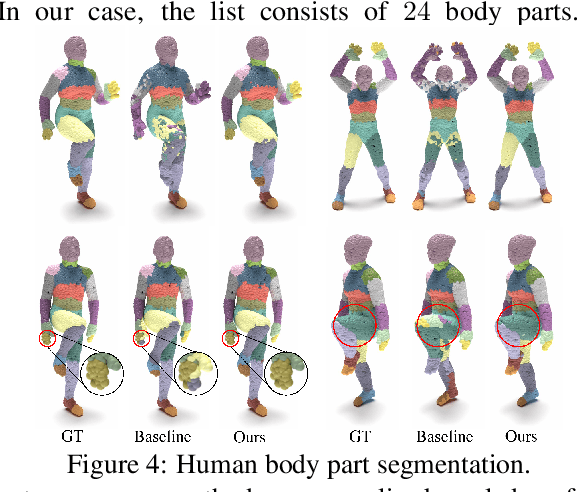
Integrating a notion of symmetry into point cloud neural networks is a provably effective way to improve their generalization capability. Of particular interest are $E(3)$ equivariant point cloud networks where Euclidean transformations applied to the inputs are preserved in the outputs. Recent efforts aim to extend networks that are $E(3)$ equivariant, to accommodate inputs made of multiple parts, each of which exhibits local $E(3)$ symmetry. In practical settings, however, the partitioning into individually transforming regions is unknown a priori. Errors in the partition prediction would unavoidably map to errors in respecting the true input symmetry. Past works have proposed different ways to predict the partition, which may exhibit uncontrolled errors in their ability to maintain equivariance to the actual partition. To this end, we introduce APEN: a general framework for constructing approximate piecewise-$E(3)$ equivariant point networks. Our primary insight is that functions that are equivariant with respect to a finer partition will also maintain equivariance in relation to the true partition. Leveraging this observation, we propose a design where the equivariance approximation error at each layers can be bounded solely in terms of (i) uncertainty quantification of the partition prediction, and (ii) bounds on the probability of failing to suggest a proper subpartition of the ground truth one. We demonstrate the effectiveness of APEN using two data types exemplifying part-based symmetry: (i) real-world scans of room scenes containing multiple furniture-type objects; and, (ii) human motions, characterized by articulated parts exhibiting rigid movement. Our empirical results demonstrate the advantage of integrating piecewise $E(3)$ symmetry into network design, showing a distinct improvement in generalization compared to prior works for both classification and segmentation tasks.
XCube ($\mathcal{X}^3$): Large-Scale 3D Generative Modeling using Sparse Voxel Hierarchies
Dec 06, 2023We present $\mathcal{X}^3$ (pronounced XCube), a novel generative model for high-resolution sparse 3D voxel grids with arbitrary attributes. Our model can generate millions of voxels with a finest effective resolution of up to $1024^3$ in a feed-forward fashion without time-consuming test-time optimization. To achieve this, we employ a hierarchical voxel latent diffusion model which generates progressively higher resolution grids in a coarse-to-fine manner using a custom framework built on the highly efficient VDB data structure. Apart from generating high-resolution objects, we demonstrate the effectiveness of XCube on large outdoor scenes at scales of 100m$\times$100m with a voxel size as small as 10cm. We observe clear qualitative and quantitative improvements over past approaches. In addition to unconditional generation, we show that our model can be used to solve a variety of tasks such as user-guided editing, scene completion from a single scan, and text-to-3D. More results and details can be found at https://research.nvidia.com/labs/toronto-ai/xcube/.
Neural Kernel Surface Reconstruction
Jun 09, 2023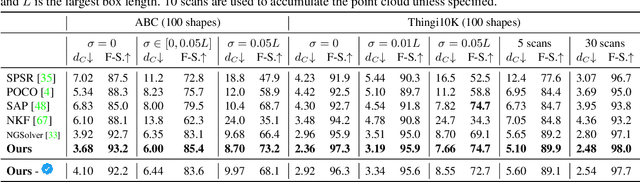
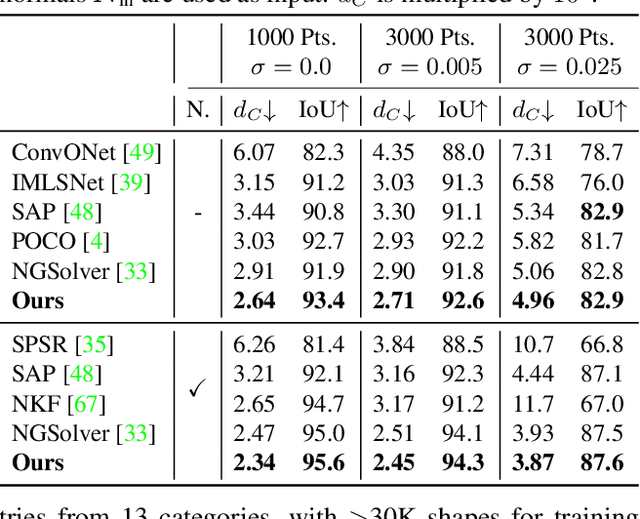
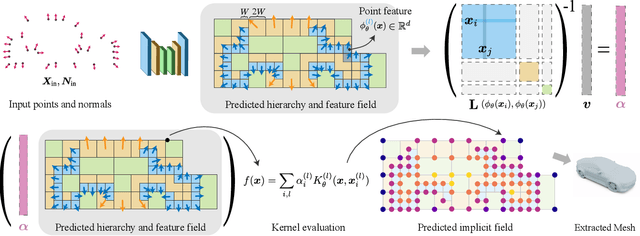
We present a novel method for reconstructing a 3D implicit surface from a large-scale, sparse, and noisy point cloud. Our approach builds upon the recently introduced Neural Kernel Fields (NKF) representation. It enjoys similar generalization capabilities to NKF, while simultaneously addressing its main limitations: (a) We can scale to large scenes through compactly supported kernel functions, which enable the use of memory-efficient sparse linear solvers. (b) We are robust to noise, through a gradient fitting solve. (c) We minimize training requirements, enabling us to learn from any dataset of dense oriented points, and even mix training data consisting of objects and scenes at different scales. Our method is capable of reconstructing millions of points in a few seconds, and handling very large scenes in an out-of-core fashion. We achieve state-of-the-art results on reconstruction benchmarks consisting of single objects, indoor scenes, and outdoor scenes.
Neural LiDAR Fields for Novel View Synthesis
May 02, 2023



We present Neural Fields for LiDAR (NFL), a method to optimise a neural field scene representation from LiDAR measurements, with the goal of synthesizing realistic LiDAR scans from novel viewpoints. NFL combines the rendering power of neural fields with a detailed, physically motivated model of the LiDAR sensing process, thus enabling it to accurately reproduce key sensor behaviors like beam divergence, secondary returns, and ray dropping. We evaluate NFL on synthetic and real LiDAR scans and show that it outperforms explicit reconstruct-then-simulate methods as well as other NeRF-style methods on LiDAR novel view synthesis task. Moreover, we show that the improved realism of the synthesized views narrows the domain gap to real scans and translates to better registration and semantic segmentation performance.
LION: Latent Point Diffusion Models for 3D Shape Generation
Oct 12, 2022



Denoising diffusion models (DDMs) have shown promising results in 3D point cloud synthesis. To advance 3D DDMs and make them useful for digital artists, we require (i) high generation quality, (ii) flexibility for manipulation and applications such as conditional synthesis and shape interpolation, and (iii) the ability to output smooth surfaces or meshes. To this end, we introduce the hierarchical Latent Point Diffusion Model (LION) for 3D shape generation. LION is set up as a variational autoencoder (VAE) with a hierarchical latent space that combines a global shape latent representation with a point-structured latent space. For generation, we train two hierarchical DDMs in these latent spaces. The hierarchical VAE approach boosts performance compared to DDMs that operate on point clouds directly, while the point-structured latents are still ideally suited for DDM-based modeling. Experimentally, LION achieves state-of-the-art generation performance on multiple ShapeNet benchmarks. Furthermore, our VAE framework allows us to easily use LION for different relevant tasks: LION excels at multimodal shape denoising and voxel-conditioned synthesis, and it can be adapted for text- and image-driven 3D generation. We also demonstrate shape autoencoding and latent shape interpolation, and we augment LION with modern surface reconstruction techniques to generate smooth 3D meshes. We hope that LION provides a powerful tool for artists working with 3D shapes due to its high-quality generation, flexibility, and surface reconstruction. Project page and code: https://nv-tlabs.github.io/LION.