 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecovering Dynamic 3D Sketches from Videos
Mar 27, 2025



Understanding 3D motion from videos presents inherent challenges due to the diverse types of movement, ranging from rigid and deformable objects to articulated structures. To overcome this, we propose Liv3Stroke, a novel approach for abstracting objects in motion with deformable 3D strokes. The detailed movements of an object may be represented by unstructured motion vectors or a set of motion primitives using a pre-defined articulation from a template model. Just as a free-hand sketch can intuitively visualize scenes or intentions with a sparse set of lines, we utilize a set of parametric 3D curves to capture a set of spatially smooth motion elements for general objects with unknown structures. We first extract noisy, 3D point cloud motion guidance from video frames using semantic features, and our approach deforms a set of curves to abstract essential motion features as a set of explicit 3D representations. Such abstraction enables an understanding of prominent components of motions while maintaining robustness to environmental factors. Our approach allows direct analysis of 3D object movements from video, tackling the uncertainty that typically occurs when translating real-world motion into recorded footage. The project page is accessible via: https://jaeah.me/liv3stroke_web
SceneMI: Motion In-betweening for Modeling Human-Scene Interactions
Mar 20, 2025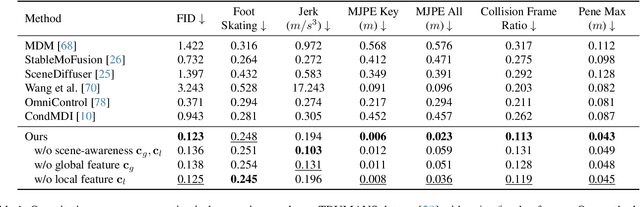
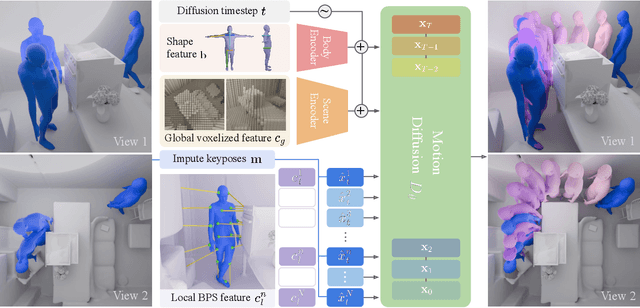

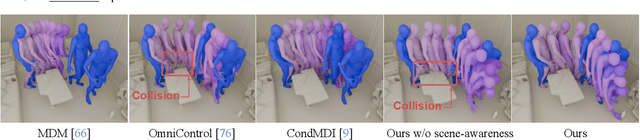
Modeling human-scene interactions (HSI) is essential for understanding and simulating everyday human behaviors. Recent approaches utilizing generative modeling have made progress in this domain; however, they are limited in controllability and flexibility for real-world applications. To address these challenges, we propose reformulating the HSI modeling problem as Scene-aware Motion In-betweening -- a more tractable and practical task. We introduce SceneMI, a framework that supports several practical applications, including keyframe-guided character animation in 3D scenes and enhancing the motion quality of imperfect HSI data. SceneMI employs dual scene descriptors to comprehensively encode global and local scene context. Furthermore, our framework leverages the inherent denoising nature of diffusion models to generalize on noisy keyframes. Experimental results demonstrate SceneMI's effectiveness in scene-aware keyframe in-betweening and generalization to the real-world GIMO dataset, where motions and scenes are acquired by noisy IMU sensors and smartphones. We further showcase SceneMI's applicability in HSI reconstruction from monocular videos.
Learning 3D Scene Analogies with Neural Contextual Scene Maps
Mar 20, 2025



Understanding scene contexts is crucial for machines to perform tasks and adapt prior knowledge in unseen or noisy 3D environments. As data-driven learning is intractable to comprehensively encapsulate diverse ranges of layouts and open spaces, we propose teaching machines to identify relational commonalities in 3D spaces. Instead of focusing on point-wise or object-wise representations, we introduce 3D scene analogies, which are smooth maps between 3D scene regions that align spatial relationships. Unlike well-studied single instance-level maps, these scene-level maps smoothly link large scene regions, potentially enabling unique applications in trajectory transfer in AR/VR, long demonstration transfer for imitation learning, and context-aware object rearrangement. To find 3D scene analogies, we propose neural contextual scene maps, which extract descriptor fields summarizing semantic and geometric contexts, and holistically align them in a coarse-to-fine manner for map estimation. This approach reduces reliance on individual feature points, making it robust to input noise or shape variations. Experiments demonstrate the effectiveness of our approach in identifying scene analogies and transferring trajectories or object placements in diverse indoor scenes, indicating its potential for robotics and AR/VR applications.
Motion Synthesis with Sparse and Flexible Keyjoint Control
Mar 18, 2025Creating expressive character animations is labor-intensive, requiring intricate manual adjustment of animators across space and time. Previous works on controllable motion generation often rely on a predefined set of dense spatio-temporal specifications (e.g., dense pelvis trajectories with exact per-frame timing), limiting practicality for animators. To process high-level intent and intuitive control in diverse scenarios, we propose a practical controllable motions synthesis framework that respects sparse and flexible keyjoint signals. Our approach employs a decomposed diffusion-based motion synthesis framework that first synthesizes keyjoint movements from sparse input control signals and then synthesizes full-body motion based on the completed keyjoint trajectories. The low-dimensional keyjoint movements can easily adapt to various control signal types, such as end-effector position for diverse goal-driven motion synthesis, or incorporate functional constraints on a subset of keyjoints. Additionally, we introduce a time-agnostic control formulation, eliminating the need for frame-specific timing annotations and enhancing control flexibility. Then, the shared second stage can synthesize a natural whole-body motion that precisely satisfies the task requirement from dense keyjoint movements. We demonstrate the effectiveness of sparse and flexible keyjoint control through comprehensive experiments on diverse datasets and scenarios.
Less is More: Improving Motion Diffusion Models with Sparse Keyframes
Mar 18, 2025Recent advances in motion diffusion models have led to remarkable progress in diverse motion generation tasks, including text-to-motion synthesis. However, existing approaches represent motions as dense frame sequences, requiring the model to process redundant or less informative frames. The processing of dense animation frames imposes significant training complexity, especially when learning intricate distributions of large motion datasets even with modern neural architectures. This severely limits the performance of generative motion models for downstream tasks. Inspired by professional animators who mainly focus on sparse keyframes, we propose a novel diffusion framework explicitly designed around sparse and geometrically meaningful keyframes. Our method reduces computation by masking non-keyframes and efficiently interpolating missing frames. We dynamically refine the keyframe mask during inference to prioritize informative frames in later diffusion steps. Extensive experiments show that our approach consistently outperforms state-of-the-art methods in text alignment and motion realism, while also effectively maintaining high performance at significantly fewer diffusion steps. We further validate the robustness of our framework by using it as a generative prior and adapting it to different downstream tasks. Source code and pre-trained models will be released upon acceptance.
Versatile Physics-based Character Control with Hybrid Latent Representation
Mar 17, 2025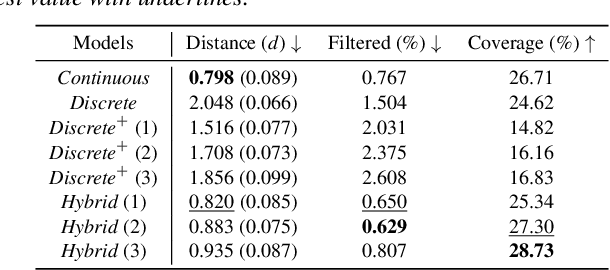
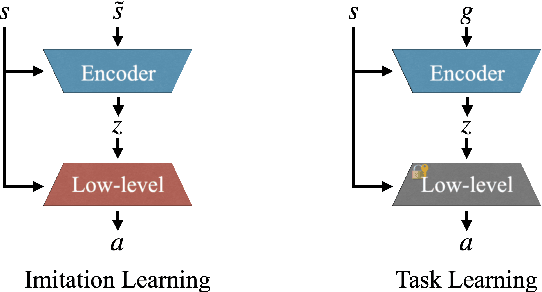

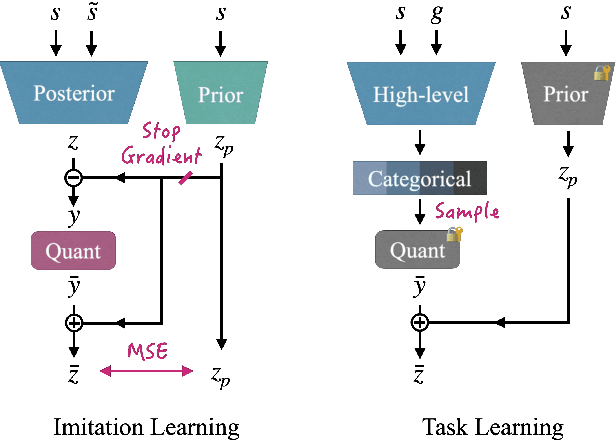
We present a versatile latent representation that enables physically simulated character to efficiently utilize motion priors. To build a powerful motion embedding that is shared across multiple tasks, the physics controller should employ rich latent space that is easily explored and capable of generating high-quality motion. We propose integrating continuous and discrete latent representations to build a versatile motion prior that can be adapted to a wide range of challenging control tasks. Specifically, we build a discrete latent model to capture distinctive posterior distribution without collapse, and simultaneously augment the sampled vector with the continuous residuals to generate high-quality, smooth motion without jittering. We further incorporate Residual Vector Quantization, which not only maximizes the capacity of the discrete motion prior, but also efficiently abstracts the action space during the task learning phase. We demonstrate that our agent can produce diverse yet smooth motions simply by traversing the learned motion prior through unconditional motion generation. Furthermore, our model robustly satisfies sparse goal conditions with highly expressive natural motions, including head-mounted device tracking and motion in-betweening at irregular intervals, which could not be achieved with existing latent representations.
Structure-from-Sherds++: Robust Incremental 3D Reassembly of Axially Symmetric Pots from Unordered and Mixed Fragment Collections
Feb 19, 2025Reassembling multiple axially symmetric pots from fragmentary sherds is crucial for cultural heritage preservation, yet it poses significant challenges due to thin and sharp fracture surfaces that generate numerous false positive matches and hinder large-scale puzzle solving. Existing global approaches, which optimize all potential fragment pairs simultaneously or data-driven models, are prone to local minima and face scalability issues when multiple pots are intermixed. Motivated by Structure-from-Motion (SfM) for 3D reconstruction from multiple images, we propose an efficient reassembly method for axially symmetric pots based on iterative registration of one sherd at a time, called Structure-from-Sherds++ (SfS++). Our method extends beyond simple replication of incremental SfM and leverages multi-graph beam search to explore multiple registration paths. This allows us to effectively filter out indistinguishable false matches and simultaneously reconstruct multiple pots without requiring prior information such as base or the number of mixed objects. Our approach achieves 87% reassembly accuracy on a dataset of 142 real fragments from 10 different pots, outperforming other methods in handling complex fracture patterns with mixed datasets and achieving state-of-the-art performance. Code and results can be found in our project page https://sj-yoo.info/sfs/.
Humans as a Calibration Pattern: Dynamic 3D Scene Reconstruction from Unsynchronized and Uncalibrated Videos
Dec 26, 2024



Recent works on dynamic neural field reconstruction assume input from synchronized multi-view videos with known poses. These input constraints are often unmet in real-world setups, making the approach impractical. We demonstrate that unsynchronized videos with unknown poses can generate dynamic neural fields if the videos capture human motion. Humans are one of the most common dynamic subjects whose poses can be estimated using state-of-the-art methods. While noisy, the estimated human shape and pose parameters provide a decent initialization for the highly non-convex and under-constrained problem of training a consistent dynamic neural representation. Given the sequences of pose and shape of humans, we estimate the time offsets between videos, followed by camera pose estimations by analyzing 3D joint locations. Then, we train dynamic NeRF employing multiresolution rids while simultaneously refining both time offsets and camera poses. The setup still involves optimizing many parameters, therefore, we introduce a robust progressive learning strategy to stabilize the process. Experiments show that our approach achieves accurate spatiotemporal calibration and high-quality scene reconstruction in challenging conditions.
Interactive Scene Authoring with Specialized Generative Primitives
Dec 20, 2024
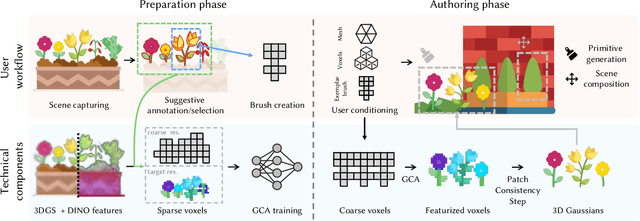
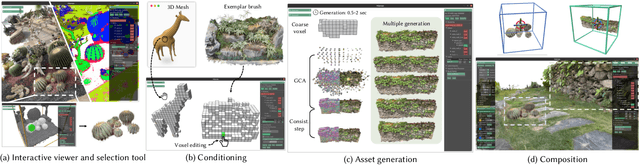
Generating high-quality 3D digital assets often requires expert knowledge of complex design tools. We introduce Specialized Generative Primitives, a generative framework that allows non-expert users to author high-quality 3D scenes in a seamless, lightweight, and controllable manner. Each primitive is an efficient generative model that captures the distribution of a single exemplar from the real world. With our framework, users capture a video of an environment, which we turn into a high-quality and explicit appearance model thanks to 3D Gaussian Splatting. Users then select regions of interest guided by semantically-aware features. To create a generative primitive, we adapt Generative Cellular Automata to single-exemplar training and controllable generation. We decouple the generative task from the appearance model by operating on sparse voxels and we recover a high-quality output with a subsequent sparse patch consistency step. Each primitive can be trained within 10 minutes and used to author new scenes interactively in a fully compositional manner. We showcase interactive sessions where various primitives are extracted from real-world scenes and controlled to create 3D assets and scenes in a few minutes. We also demonstrate additional capabilities of our primitives: handling various 3D representations to control generation, transferring appearances, and editing geometries.
ReMP: Reusable Motion Prior for Multi-domain 3D Human Pose Estimation and Motion Inbetweening
Nov 13, 2024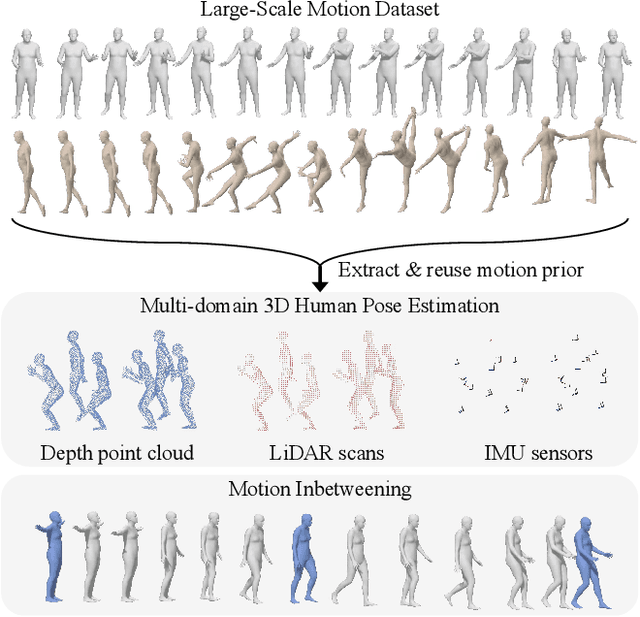
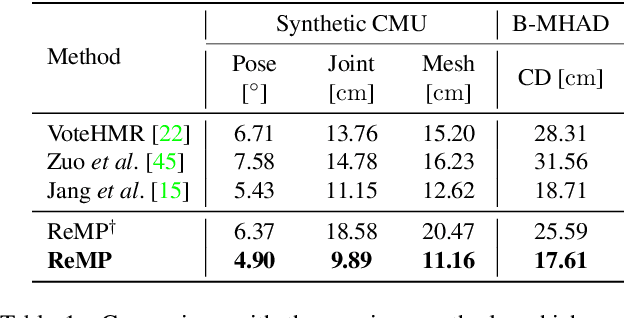
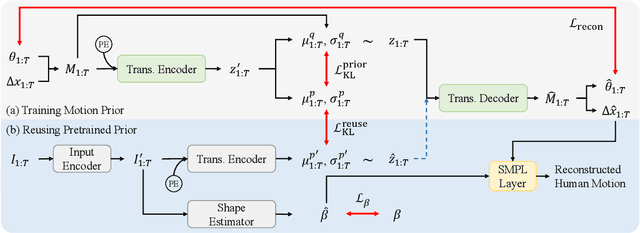
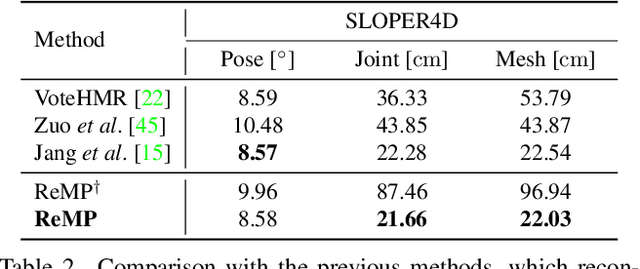
We present Reusable Motion prior (ReMP), an effective motion prior that can accurately track the temporal evolution of motion in various downstream tasks. Inspired by the success of foundation models, we argue that a robust spatio-temporal motion prior can encapsulate underlying 3D dynamics applicable to various sensor modalities. We learn the rich motion prior from a sequence of complete parametric models of posed human body shape. Our prior can easily estimate poses in missing frames or noisy measurements despite significant occlusion by employing a temporal attention mechanism. More interestingly, our prior can guide the system with incomplete and challenging input measurements to quickly extract critical information to estimate the sequence of poses, significantly improving the training efficiency for mesh sequence recovery. ReMP consistently outperforms the baseline method on diverse and practical 3D motion data, including depth point clouds, LiDAR scans, and IMU sensor data. Project page is available in https://hojunjang17.github.io/ReMP.