 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning 3D Scene Analogies with Neural Contextual Scene Maps
Mar 20, 2025



Understanding scene contexts is crucial for machines to perform tasks and adapt prior knowledge in unseen or noisy 3D environments. As data-driven learning is intractable to comprehensively encapsulate diverse ranges of layouts and open spaces, we propose teaching machines to identify relational commonalities in 3D spaces. Instead of focusing on point-wise or object-wise representations, we introduce 3D scene analogies, which are smooth maps between 3D scene regions that align spatial relationships. Unlike well-studied single instance-level maps, these scene-level maps smoothly link large scene regions, potentially enabling unique applications in trajectory transfer in AR/VR, long demonstration transfer for imitation learning, and context-aware object rearrangement. To find 3D scene analogies, we propose neural contextual scene maps, which extract descriptor fields summarizing semantic and geometric contexts, and holistically align them in a coarse-to-fine manner for map estimation. This approach reduces reliance on individual feature points, making it robust to input noise or shape variations. Experiments demonstrate the effectiveness of our approach in identifying scene analogies and transferring trajectories or object placements in diverse indoor scenes, indicating its potential for robotics and AR/VR applications.
I$^2$-SLAM: Inverting Imaging Process for Robust Photorealistic Dense SLAM
Jul 16, 2024



We present an inverse image-formation module that can enhance the robustness of existing visual SLAM pipelines for casually captured scenarios. Casual video captures often suffer from motion blur and varying appearances, which degrade the final quality of coherent 3D visual representation. We propose integrating the physical imaging into the SLAM system, which employs linear HDR radiance maps to collect measurements. Specifically, individual frames aggregate images of multiple poses along the camera trajectory to explain prevalent motion blur in hand-held videos. Additionally, we accommodate per-frame appearance variation by dedicating explicit variables for image formation steps, namely white balance, exposure time, and camera response function. Through joint optimization of additional variables, the SLAM pipeline produces high-quality images with more accurate trajectories. Extensive experiments demonstrate that our approach can be incorporated into recent visual SLAM pipelines using various scene representations, such as neural radiance fields or Gaussian splatting.
SLiDE: Self-supervised LiDAR De-snowing through Reconstruction Difficulty
Aug 08, 2022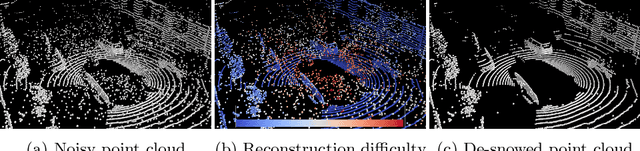
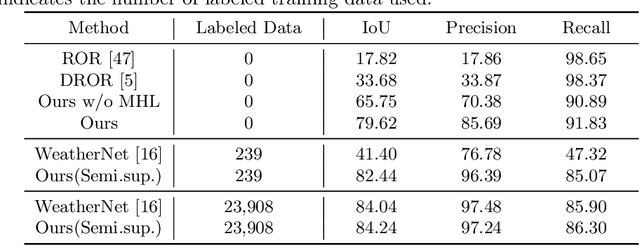
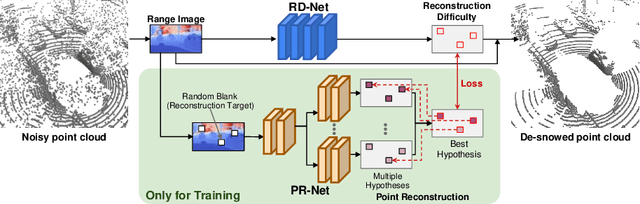
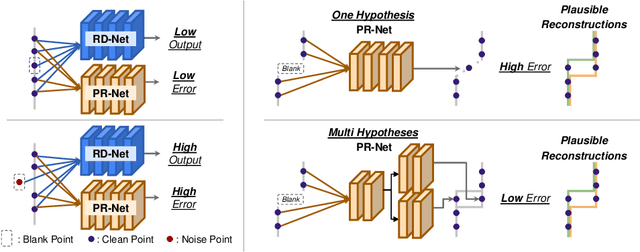
LiDAR is widely used to capture accurate 3D outdoor scene structures. However, LiDAR produces many undesirable noise points in snowy weather, which hamper analyzing meaningful 3D scene structures. Semantic segmentation with snow labels would be a straightforward solution for removing them, but it requires laborious point-wise annotation. To address this problem, we propose a novel self-supervised learning framework for snow points removal in LiDAR point clouds. Our method exploits the structural characteristic of the noise points: low spatial correlation with their neighbors. Our method consists of two deep neural networks: Point Reconstruction Network (PR-Net) reconstructs each point from its neighbors; Reconstruction Difficulty Network (RD-Net) predicts point-wise difficulty of the reconstruction by PR-Net, which we call reconstruction difficulty. With simple post-processing, our method effectively detects snow points without any label. Our method achieves the state-of-the-art performance among label-free approaches and is comparable to the fully-supervised method. Moreover, we demonstrate that our method can be exploited as a pretext task to improve label-efficiency of supervised training of de-snowing.