 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalogical Trajectory Transfer
May 14, 2026We study analogical trajectory transfer, where the goal is to translate motion trajectories in one 3D environment to a semantically analogous location in another. Such a capacity would enable machines to perform analogical spatial reasoning, with applications in AR/VR co-presence, content creation, and robotics. However, even semantically similar scenes can still differ substantially in object placement, scale, and layout, so naively matching semantics leads to collisions or geometric distortions. Furthermore, finding where each trajectory point should transfer to has a large search space, as the mapping must preserve semantics and functionality without tearing the trajectory apart or causing collisions. Our key insight is to decompose the problem into spatially segregated subproblems and merge their solutions to produce semantically consistent and spatially coherent transfers. Specifically, we partition scenes into object-centric clusters and estimate cross-scene mappings via hierarchical smooth map prediction, using 3D foundation model features that encode contextual information from object and open-space arrangements. We then combinatorially assemble the per-cluster maps into an initial transfer and refine the result to remove collisions and distortions, yielding a spatially coherent trajectory. Our method does not require training, attains a fast runtime around 0.6 seconds, and outperforms baselines based on LLMs, VLMs, and scene graph matching. We further showcase applications in virtual co-presence, multi-trajectory transfer, camera transfer, and human-to-robot motion transfer, which indicates the broad applicability of our work to AR/VR and robotics.
Learning 3D Scene Analogies with Neural Contextual Scene Maps
Mar 20, 2025



Understanding scene contexts is crucial for machines to perform tasks and adapt prior knowledge in unseen or noisy 3D environments. As data-driven learning is intractable to comprehensively encapsulate diverse ranges of layouts and open spaces, we propose teaching machines to identify relational commonalities in 3D spaces. Instead of focusing on point-wise or object-wise representations, we introduce 3D scene analogies, which are smooth maps between 3D scene regions that align spatial relationships. Unlike well-studied single instance-level maps, these scene-level maps smoothly link large scene regions, potentially enabling unique applications in trajectory transfer in AR/VR, long demonstration transfer for imitation learning, and context-aware object rearrangement. To find 3D scene analogies, we propose neural contextual scene maps, which extract descriptor fields summarizing semantic and geometric contexts, and holistically align them in a coarse-to-fine manner for map estimation. This approach reduces reliance on individual feature points, making it robust to input noise or shape variations. Experiments demonstrate the effectiveness of our approach in identifying scene analogies and transferring trajectories or object placements in diverse indoor scenes, indicating its potential for robotics and AR/VR applications.
Calibrating Panoramic Depth Estimation for Practical Localization and Mapping
Aug 27, 2023



The absolute depth values of surrounding environments provide crucial cues for various assistive technologies, such as localization, navigation, and 3D structure estimation. We propose that accurate depth estimated from panoramic images can serve as a powerful and light-weight input for a wide range of downstream tasks requiring 3D information. While panoramic images can easily capture the surrounding context from commodity devices, the estimated depth shares the limitations of conventional image-based depth estimation; the performance deteriorates under large domain shifts and the absolute values are still ambiguous to infer from 2D observations. By taking advantage of the holistic view, we mitigate such effects in a self-supervised way and fine-tune the network with geometric consistency during the test phase. Specifically, we construct a 3D point cloud from the current depth prediction and project the point cloud at various viewpoints or apply stretches on the current input image to generate synthetic panoramas. Then we minimize the discrepancy of the 3D structure estimated from synthetic images without collecting additional data. We empirically evaluate our method in robot navigation and map-free localization where our method shows large performance enhancements. Our calibration method can therefore widen the applicability under various external conditions, serving as a key component for practical panorama-based machine vision systems.
MoDA: Map style transfer for self-supervised Domain Adaptation of embodied agents
Nov 29, 2022We propose a domain adaptation method, MoDA, which adapts a pretrained embodied agent to a new, noisy environment without ground-truth supervision. Map-based memory provides important contextual information for visual navigation, and exhibits unique spatial structure mainly composed of flat walls and rectangular obstacles. Our adaptation approach encourages the inherent regularities on the estimated maps to guide the agent to overcome the prevalent domain discrepancy in a novel environment. Specifically, we propose an efficient learning curriculum to handle the visual and dynamics corruptions in an online manner, self-supervised with pseudo clean maps generated by style transfer networks. Because the map-based representation provides spatial knowledge for the agent's policy, our formulation can deploy the pretrained policy networks from simulators in a new setting. We evaluate MoDA in various practical scenarios and show that our proposed method quickly enhances the agent's performance in downstream tasks including localization, mapping, exploration, and point-goal navigation.
Alternating Cross-attention Vision-Language Model for Efficient Learning with Medical Image and Report without Curation
Aug 10, 2022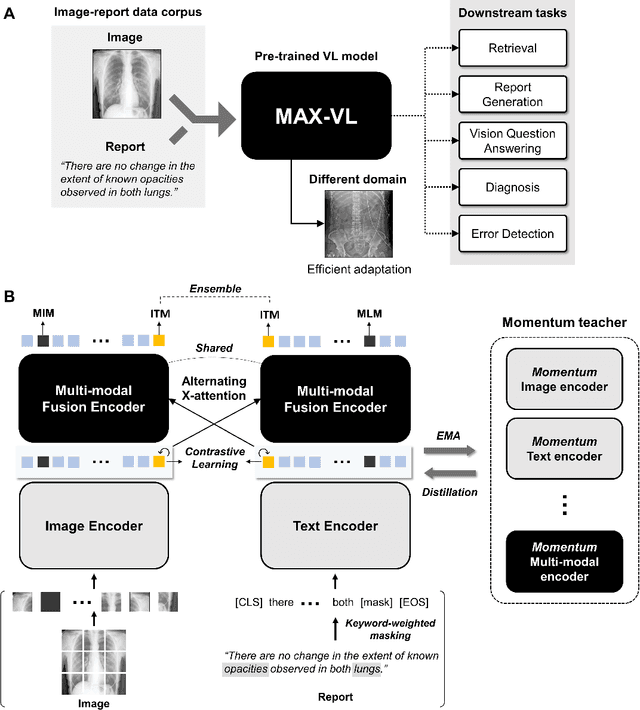
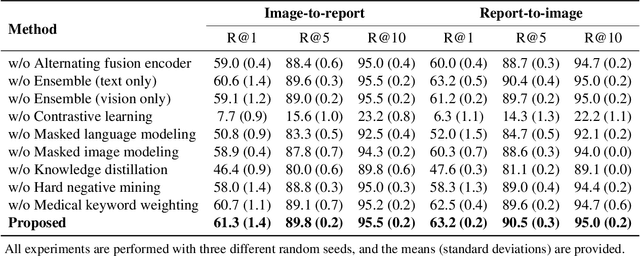
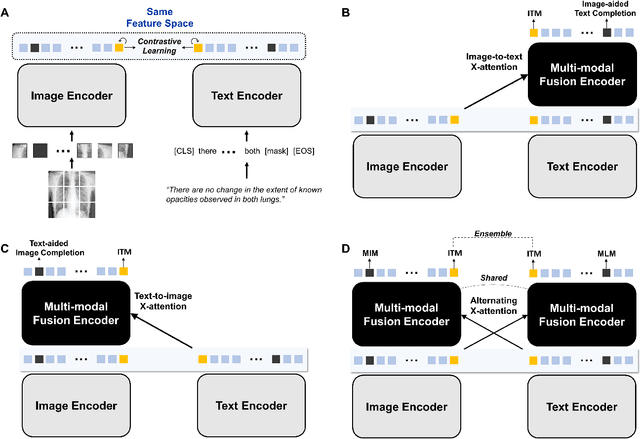
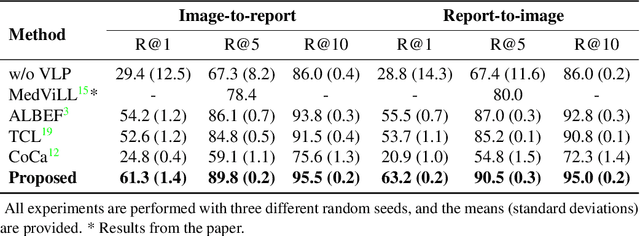
Recent advances in vision-language pre-training have demonstrated astounding performances in diverse vision-language tasks, shedding a light on the long-standing problems of a comprehensive understanding of both visual and textual concepts in artificial intelligence research. However, there has been limited success in the application of vision-language pre-training in the medical domain, as the current vision-language models and learning strategies for photographic images and captions are not optimal to process the medical data which are usually insufficient in the amount and the diversity, which impedes successful learning of joint vision-language concepts. In this study, we introduce MAX-VL, a model tailored for efficient vision-language pre-training in the medical domain. We experimentally demonstrated that the pre-trained MAX-VL model outperforms the current state-of-the-art vision language models in various vision-language tasks. We also suggested the clinical utility for the diagnosis of newly emerging diseases and human error detection as well as showed the widespread applicability of the model in different domain data.
MR Image Denoising and Super-Resolution Using Regularized Reverse Diffusion
Mar 23, 2022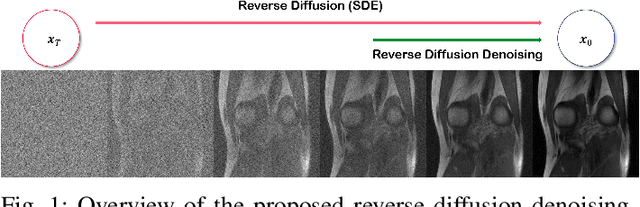
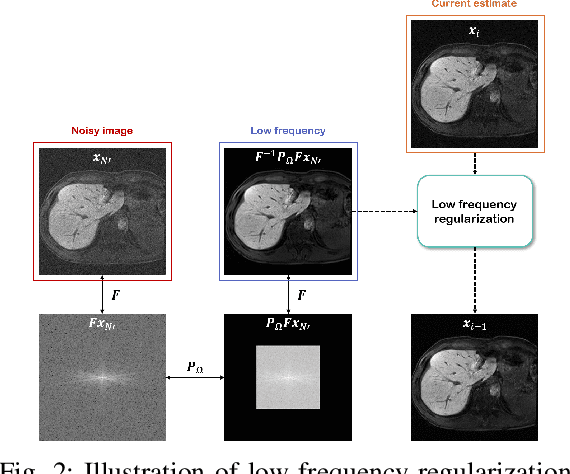
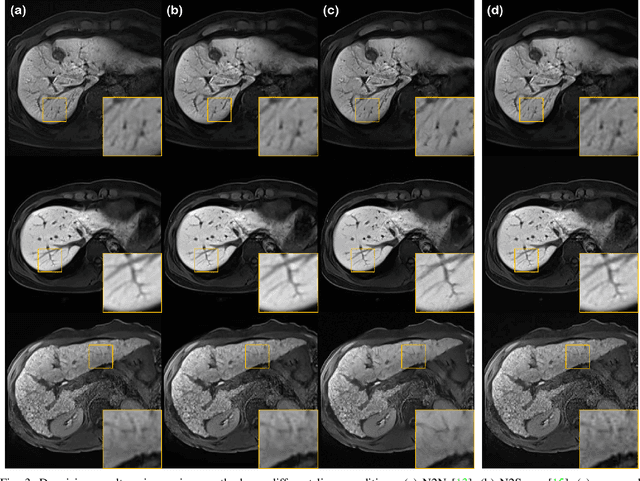
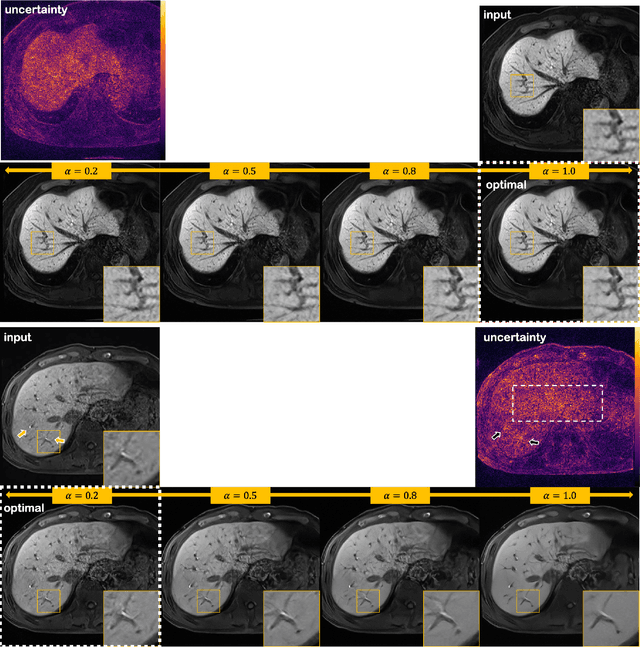
Patient scans from MRI often suffer from noise, which hampers the diagnostic capability of such images. As a method to mitigate such artifact, denoising is largely studied both within the medical imaging community and beyond the community as a general subject. However, recent deep neural network-based approaches mostly rely on the minimum mean squared error (MMSE) estimates, which tend to produce a blurred output. Moreover, such models suffer when deployed in real-world sitautions: out-of-distribution data, and complex noise distributions that deviate from the usual parametric noise models. In this work, we propose a new denoising method based on score-based reverse diffusion sampling, which overcomes all the aforementioned drawbacks. Our network, trained only with coronal knee scans, excels even on out-of-distribution in vivo liver MRI data, contaminated with complex mixture of noise. Even more, we propose a method to enhance the resolution of the denoised image with the same network. With extensive experiments, we show that our method establishes state-of-the-art performance, while having desirable properties which prior MMSE denoisers did not have: flexibly choosing the extent of denoising, and quantifying uncertainty.
Tunable Image Quality Control of 3-D Ultrasound using Switchable CycleGAN
Dec 06, 2021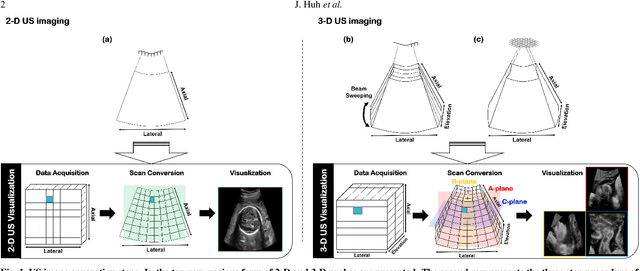
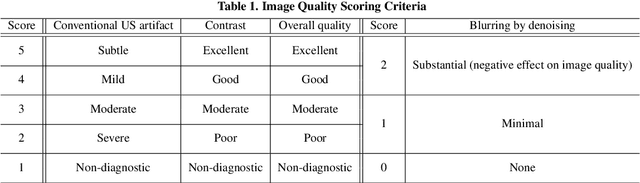
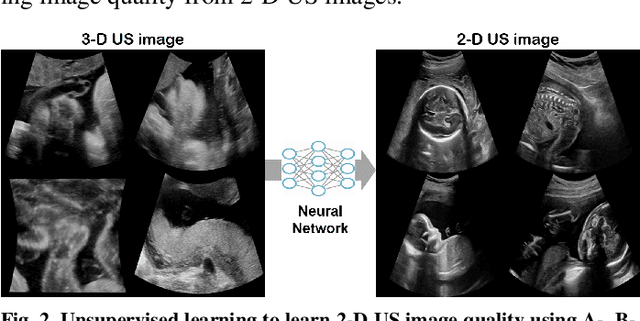
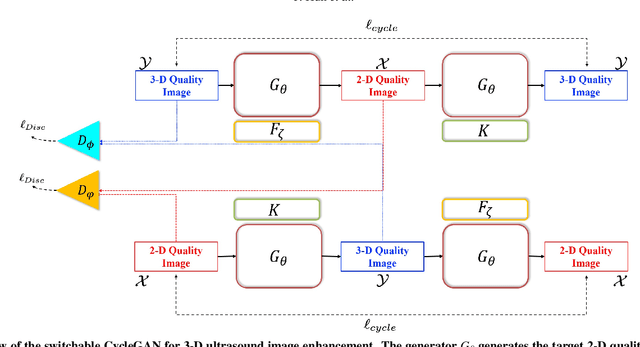
In contrast to 2-D ultrasound (US) for uniaxial plane imaging, a 3-D US imaging system can visualize a volume along three axial planes. This allows for a full view of the anatomy, which is useful for gynecological (GYN) and obstetrical (OB) applications. Unfortunately, the 3-D US has an inherent limitation in resolution compared to the 2-D US. In the case of 3-D US with a 3-D mechanical probe, for example, the image quality is comparable along the beam direction, but significant deterioration in image quality is often observed in the other two axial image planes. To address this, here we propose a novel unsupervised deep learning approach to improve 3-D US image quality. In particular, using {\em unmatched} high-quality 2-D US images as a reference, we trained a recently proposed switchable CycleGAN architecture so that every mapping plane in 3-D US can learn the image quality of 2-D US images. Thanks to the switchable architecture, our network can also provide real-time control of image enhancement level based on user preference, which is ideal for a user-centric scanner setup. Extensive experiments with clinical evaluation confirm that our method offers significantly improved image quality as well user-friendly flexibility.
Self-Supervised Domain Adaptation for Visual Navigation with Global Map Consistency
Oct 14, 2021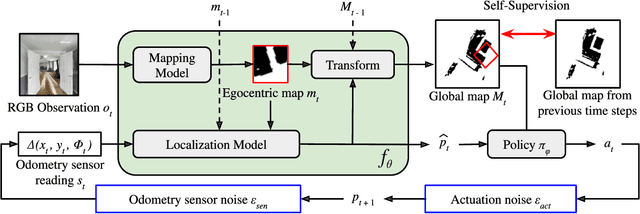
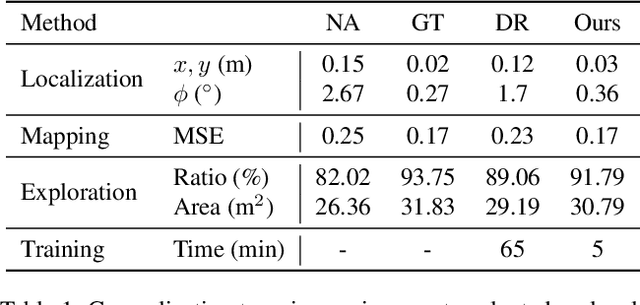
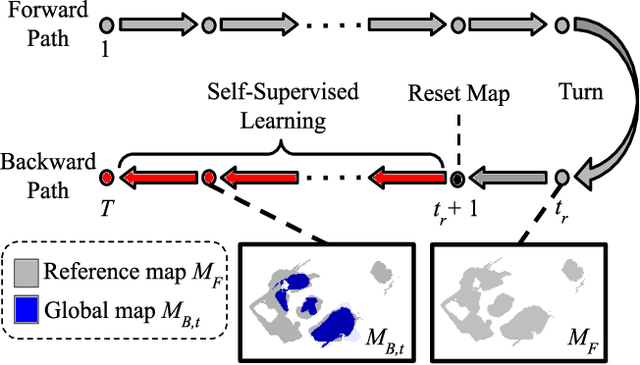
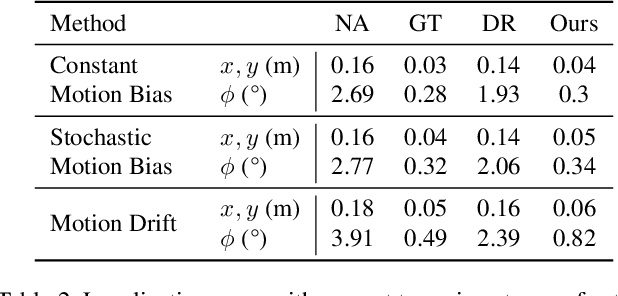
We propose a light-weight, self-supervised adaptation for a visual navigation agent to generalize to unseen environment. Given an embodied agent trained in a noiseless environment, our objective is to transfer the agent to a noisy environment where actuation and odometry sensor noise is present. Our method encourages the agent to maximize the consistency between the global maps generated at different time steps in a round-trip trajectory. The proposed task is completely self-supervised, not requiring any supervision from ground-truth pose data or explicit noise model. In addition, optimization of the task objective is extremely light-weight, as training terminates within a few minutes on a commodity GPU. Our experiments show that the proposed task helps the agent to successfully transfer to new, noisy environments. The transferred agent exhibits improved localization and mapping accuracy, further leading to enhanced performance in downstream visual navigation tasks. Moreover, we demonstrate test-time adaptation with our self-supervised task to show its potential applicability in real-world deployment.
SGoLAM: Simultaneous Goal Localization and Mapping for Multi-Object Goal Navigation
Oct 14, 2021
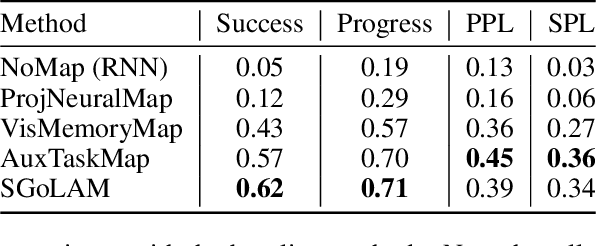
We present SGoLAM, short for simultaneous goal localization and mapping, which is a simple and efficient algorithm for Multi-Object Goal navigation. Given an agent equipped with an RGB-D camera and a GPS/Compass sensor, our objective is to have the agent navigate to a sequence of target objects in realistic 3D environments. Our pipeline fully leverages the strength of classical approaches for visual navigation, by decomposing the problem into two key components: mapping and goal localization. The mapping module converts the depth observations into an occupancy map, and the goal localization module marks the locations of goal objects. The agent's policy is determined using the information provided by the two modules: if a current goal is found, plan towards the goal and otherwise, perform exploration. As our approach does not require any training of neural networks, it could be used in an off-the-shelf manner, and amenable for fast generalization in new, unseen environments. Nonetheless, our approach performs on par with the state-of-the-art learning-based approaches. SGoLAM is ranked 2nd in the CVPR 2021 MultiON (Multi-Object Goal Navigation) challenge. We have made our code publicly available at \emph{https://github.com/eunsunlee/SGoLAM}.