 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlternating Cross-attention Vision-Language Model for Efficient Learning with Medical Image and Report without Curation
Paper and Code
Aug 10, 2022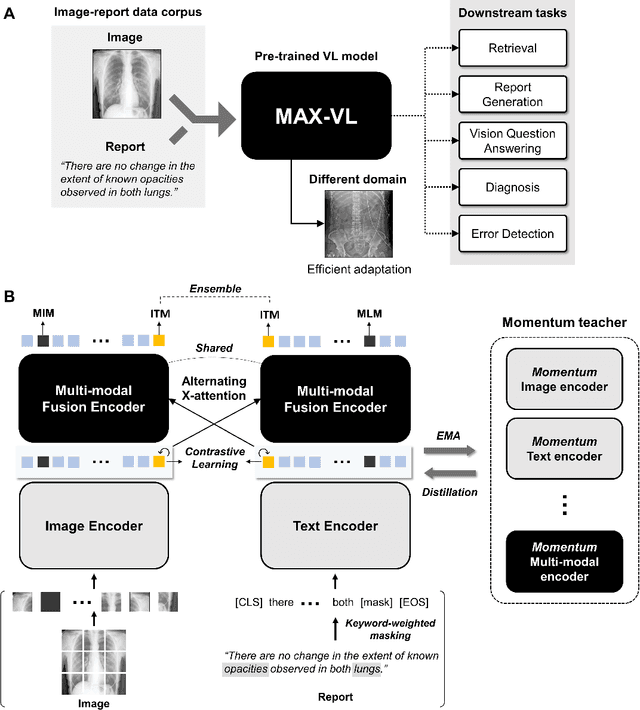
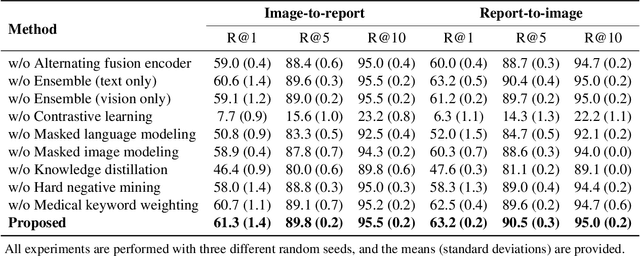
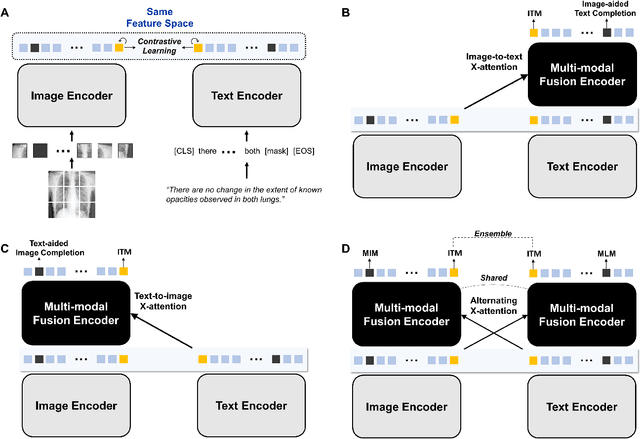
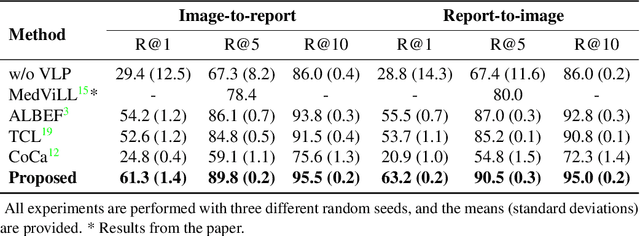
Recent advances in vision-language pre-training have demonstrated astounding performances in diverse vision-language tasks, shedding a light on the long-standing problems of a comprehensive understanding of both visual and textual concepts in artificial intelligence research. However, there has been limited success in the application of vision-language pre-training in the medical domain, as the current vision-language models and learning strategies for photographic images and captions are not optimal to process the medical data which are usually insufficient in the amount and the diversity, which impedes successful learning of joint vision-language concepts. In this study, we introduce MAX-VL, a model tailored for efficient vision-language pre-training in the medical domain. We experimentally demonstrated that the pre-trained MAX-VL model outperforms the current state-of-the-art vision language models in various vision-language tasks. We also suggested the clinical utility for the diagnosis of newly emerging diseases and human error detection as well as showed the widespread applicability of the model in different domain data.