 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoMedic: An Automated Evaluation Framework for Clinical Conversational Agents with Medical Dataset Grounding
Dec 11, 2025Evaluating large language models (LLMs) has recently emerged as a critical issue for safe and trustworthy application of LLMs in the medical domain. Although a variety of static medical question-answering (QA) benchmarks have been proposed, many aspects remain underexplored, such as the effectiveness of LLMs in generating responses in dynamic, interactive clinical multi-turn conversation situations and the identification of multi-faceted evaluation strategies beyond simple accuracy. However, formally evaluating a dynamic, interactive clinical situation is hindered by its vast combinatorial space of possible patient states and interaction trajectories, making it difficult to standardize and quantitatively measure such scenarios. Here, we introduce AutoMedic, a multi-agent simulation framework that enables automated evaluation of LLMs as clinical conversational agents. AutoMedic transforms off-the-shelf static QA datasets into virtual patient profiles, enabling realistic and clinically grounded multi-turn clinical dialogues between LLM agents. The performance of various clinical conversational agents is then assessed based on our CARE metric, which provides a multi-faceted evaluation standard of clinical conversational accuracy, efficiency/strategy, empathy, and robustness. Our findings, validated by human experts, demonstrate the validity of AutoMedic as an automated evaluation framework for clinical conversational agents, offering practical guidelines for the effective development of LLMs in conversational medical applications.
Rethinking Test-Time Scaling for Medical AI: Model and Task-Aware Strategies for LLMs and VLMs
Jun 16, 2025



Test-time scaling has recently emerged as a promising approach for enhancing the reasoning capabilities of large language models or vision-language models during inference. Although a variety of test-time scaling strategies have been proposed, and interest in their application to the medical domain is growing, many critical aspects remain underexplored, including their effectiveness for vision-language models and the identification of optimal strategies for different settings. In this paper, we conduct a comprehensive investigation of test-time scaling in the medical domain. We evaluate its impact on both large language models and vision-language models, considering factors such as model size, inherent model characteristics, and task complexity. Finally, we assess the robustness of these strategies under user-driven factors, such as misleading information embedded in prompts. Our findings offer practical guidelines for the effective use of test-time scaling in medical applications and provide insights into how these strategies can be further refined to meet the reliability and interpretability demands of the medical domain.
Read Like a Radiologist: Efficient Vision-Language Model for 3D Medical Imaging Interpretation
Dec 18, 2024



Recent medical vision-language models (VLMs) have shown promise in 2D medical image interpretation. However extending them to 3D medical imaging has been challenging due to computational complexities and data scarcity. Although a few recent VLMs specified for 3D medical imaging have emerged, all are limited to learning volumetric representation of a 3D medical image as a set of sub-volumetric features. Such process introduces overly correlated representations along the z-axis that neglect slice-specific clinical details, particularly for 3D medical images where adjacent slices have low redundancy. To address this limitation, we introduce MS-VLM that mimic radiologists' workflow in 3D medical image interpretation. Specifically, radiologists analyze 3D medical images by examining individual slices sequentially and synthesizing information across slices and views. Likewise, MS-VLM leverages self-supervised 2D transformer encoders to learn a volumetric representation that capture inter-slice dependencies from a sequence of slice-specific features. Unbound by sub-volumetric patchification, MS-VLM is capable of obtaining useful volumetric representations from 3D medical images with any slice length and from multiple images acquired from different planes and phases. We evaluate MS-VLM on publicly available chest CT dataset CT-RATE and in-house rectal MRI dataset. In both scenarios, MS-VLM surpasses existing methods in radiology report generation, producing more coherent and clinically relevant reports. These findings highlight the potential of MS-VLM to advance 3D medical image interpretation and improve the robustness of medical VLMs.
RT-Surv: Improving Mortality Prediction After Radiotherapy with Large Language Model Structuring of Large-Scale Unstructured Electronic Health Records
Aug 09, 2024Accurate patient selection is critical in radiotherapy (RT) to prevent ineffective treatments. Traditional survival prediction models, relying on structured data, often lack precision. This study explores the potential of large language models (LLMs) to structure unstructured electronic health record (EHR) data, thereby improving survival prediction accuracy through comprehensive clinical information integration. Data from 34,276 patients treated with RT at Yonsei Cancer Center between 2013 and 2023 were analyzed, encompassing both structured and unstructured data. An open-source LLM was used to structure the unstructured EHR data via single-shot learning, with its performance compared against a domain-specific medical LLM and a smaller variant. Survival prediction models were developed using statistical, machine learning, and deep learning approaches, incorporating both structured and LLM-structured data. Clinical experts evaluated the accuracy of the LLM-structured data. The open-source LLM achieved 87.5% accuracy in structuring unstructured EHR data without additional training, significantly outperforming the domain-specific medical LLM, which reached only 35.8% accuracy. Larger LLMs were more effective, particularly in extracting clinically relevant features like general condition and disease extent, which closely correlated with patient survival. Incorporating LLM-structured clinical features into survival prediction models significantly improved accuracy, with the C-index of deep learning models increasing from 0.737 to 0.820. These models also became more interpretable by emphasizing clinically significant factors. This study shows that general-domain LLMs, even without specific medical training, can effectively structure large-scale unstructured EHR data, substantially enhancing the accuracy and interpretability of clinical predictive models.
Enhancing Demand Prediction in Open Systems by Cartogram-aided Deep Learning
Mar 24, 2024Predicting temporal patterns across various domains poses significant challenges due to their nuanced and often nonlinear trajectories. To address this challenge, prediction frameworks have been continuously refined, employing data-driven statistical methods, mathematical models, and machine learning. Recently, as one of the challenging systems, shared transport systems such as public bicycles have gained prominence due to urban constraints and environmental concerns. Predicting rental and return patterns at bicycle stations remains a formidable task due to the system's openness and imbalanced usage patterns across stations. In this study, we propose a deep learning framework to predict rental and return patterns by leveraging cartogram approaches. The cartogram approach facilitates the prediction of demand for newly installed stations with no training data as well as long-period prediction, which has not been achieved before. We apply this method to public bicycle rental-and-return data in Seoul, South Korea, employing a spatial-temporal convolutional graph attention network. Our improved architecture incorporates batch attention and modified node feature updates for better prediction accuracy across different time scales. We demonstrate the effectiveness of our framework in predicting temporal patterns and its potential applications.
Objective and Interpretable Breast Cosmesis Evaluation with Attention Guided Denoising Diffusion Anomaly Detection Model
Feb 28, 2024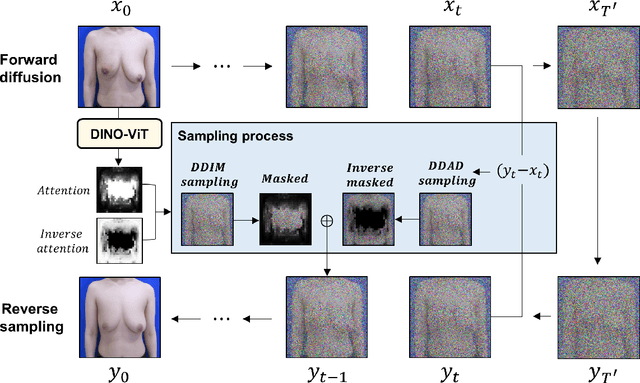
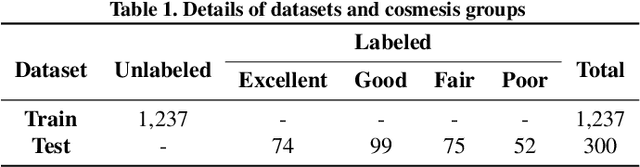
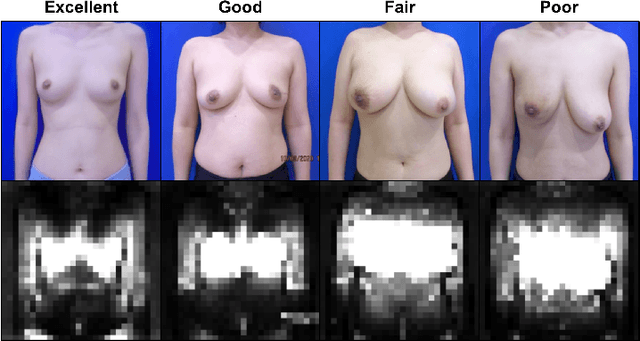
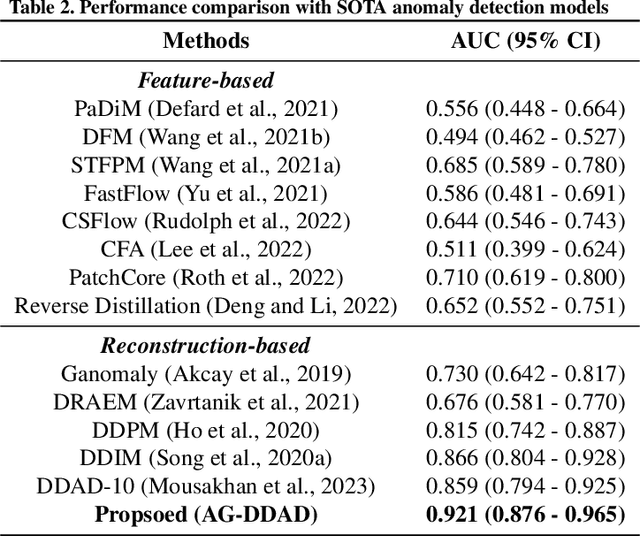
As advancements in the field of breast cancer treatment continue to progress, the assessment of post-surgical cosmetic outcomes has gained increasing significance due to its substantial impact on patients' quality of life. However, evaluating breast cosmesis presents challenges due to the inherently subjective nature of expert labeling. In this study, we present a novel automated approach, Attention-Guided Denoising Diffusion Anomaly Detection (AG-DDAD), designed to assess breast cosmesis following surgery, addressing the limitations of conventional supervised learning and existing anomaly detection models. Our approach leverages the attention mechanism of the distillation with no label (DINO) self-supervised Vision Transformer (ViT) in combination with a diffusion model to achieve high-quality image reconstruction and precise transformation of discriminative regions. By training the diffusion model on unlabeled data predominantly with normal cosmesis, we adopt an unsupervised anomaly detection perspective to automatically score the cosmesis. Real-world data experiments demonstrate the effectiveness of our method, providing visually appealing representations and quantifiable scores for cosmesis evaluation. Compared to commonly used rule-based programs, our fully automated approach eliminates the need for manual annotations and offers objective evaluation. Moreover, our anomaly detection model exhibits state-of-the-art performance, surpassing existing models in accuracy. Going beyond the scope of breast cosmesis, our research represents a significant advancement in unsupervised anomaly detection within the medical domain, thereby paving the way for future investigations.
RO-LLaMA: Generalist LLM for Radiation Oncology via Noise Augmentation and Consistency Regularization
Nov 27, 2023Recent advancements in Artificial Intelligence (AI) have profoundly influenced medical fields, by providing tools to reduce clinical workloads. However, most AI models are constrained to execute uni-modal tasks, in stark contrast to the comprehensive approaches utilized by medical professionals. To address this, here we present RO-LLaMA, a versatile generalist large language model (LLM) tailored for the field of radiation oncology. This model seamlessly covers a wide range of the workflow of radiation oncologists, adept at various tasks such as clinical report summarization, radiation therapy plan suggestion, and plan-guided therapy target volume segmentation. In particular, to maximize the end-to-end performance, we further present a novel Consistency Embedding Fine-Tuning (CEFTune) technique, which boosts LLM's robustness to additional errors at the intermediates while preserving the capability of handling clean inputs, and creatively transform this concept into LLM-driven segmentation framework as Consistency Embedding Segmentation (CESEG). Experimental results on multi-centre cohort sets demonstrate our proposed RO-LLaMA's promising performance for diverse tasks with generalization capabilities.
LLM-driven Multimodal Target Volume Contouring in Radiation Oncology
Nov 03, 2023Target volume contouring for radiation therapy is considered significantly more challenging than the normal organ segmentation tasks as it necessitates the utilization of both image and text-based clinical information. Inspired by the recent advancement of large language models (LLMs) that can facilitate the integration of the textural information and images, here we present a novel LLM-driven multi-modal AI that utilizes the clinical text information and is applicable to the challenging task of target volume contouring for radiation therapy, and validate it within the context of breast cancer radiation therapy target volume contouring. Using external validation and data-insufficient environments, which attributes highly conducive to real-world applications, we demonstrate that the proposed model exhibits markedly improved performance compared to conventional vision-only AI models, particularly exhibiting robust generalization performance and data-efficiency. To our best knowledge, this is the first LLM-driven multimodal AI model that integrates the clinical text information into target volume delineation for radiation oncology.
Improving Medical Speech-to-Text Accuracy with Vision-Language Pre-training Model
Feb 27, 2023



Automatic Speech Recognition (ASR) is a technology that converts spoken words into text, facilitating interaction between humans and machines. One of the most common applications of ASR is Speech-To-Text (STT) technology, which simplifies user workflows by transcribing spoken words into text. In the medical field, STT has the potential to significantly reduce the workload of clinicians who rely on typists to transcribe their voice recordings. However, developing an STT model for the medical domain is challenging due to the lack of sufficient speech and text datasets. To address this issue, we propose a medical-domain text correction method that modifies the output text of a general STT system using the Vision Language Pre-training (VLP) method. VLP combines textual and visual information to correct text based on image knowledge. Our extensive experiments demonstrate that the proposed method offers quantitatively and clinically significant improvements in STT performance in the medical field. We further show that multi-modal understanding of image and text information outperforms single-modal understanding using only text information.
MS-DINO: Efficient Distributed Training of Vision Transformer Foundation Model in Medical Domain through Masked Sampling
Jan 05, 2023

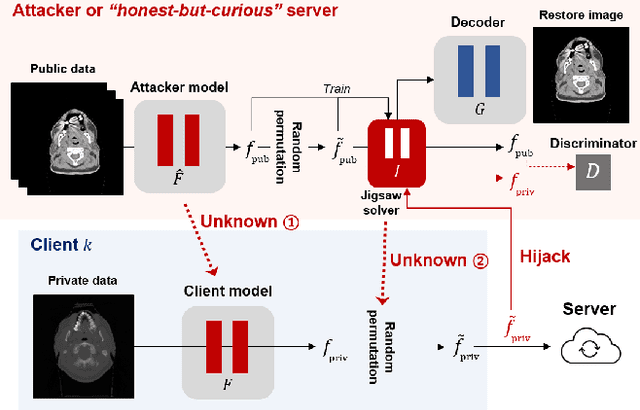

In spite of the recent success of deep learning in the medical domain, the problem of data scarcity in the medical domain gets aggravated due to privacy and data ownership issues. Distributed learning approaches including federated learning have been studied to alleviate the problems, but they suffer from cumbersome communication overheads and weakness in privacy protection. To address this, here we propose a self-supervised masked sampling distillation method for vision transformer that can be performed without continuous communication but still enhance privacy using a vision transformer-specific encryption method. The effectiveness of our method is demonstrated with extensive experiments on two medical domain data and two different downstream tasks, showing superior performances than those obtained with the existing distributed learning strategy as well as the fine-tuning only baseline. As the self-supervised model built with the proposed method is capable of having a general semantic understanding of the modality, we demonstrate its potential as a task-agnostic foundation model for various medical tasks, widening the applicability in the medical domain.