 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Guideline-Aware AI Agent for Zero-Shot Target Volume Auto-Delineation
Mar 10, 2026Delineating the clinical target volume (CTV) in radiotherapy involves complex margins constrained by tumor location and anatomical barriers. While deep learning models automate this process, their rigid reliance on expert-annotated data requires costly retraining whenever clinical guidelines update. To overcome this limitation, we introduce OncoAgent, a novel guideline-aware AI agent framework that seamlessly converts textual clinical guidelines into three-dimensional target contours in a training-free manner. Evaluated on esophageal cancer cases, the agent achieves a zero-shot Dice similarity coefficient of 0.842 for the CTV and 0.880 for the planning target volume, demonstrating performance highly comparable to a fully supervised nnU-Net baseline. Notably, in a blinded clinical evaluation, physicians strongly preferred OncoAgent over the supervised baseline, rating it higher in guideline compliance, modification effort, and clinical acceptability. Furthermore, the framework generalizes zero-shot to alternative esophageal guidelines and other anatomical sites (e.g., prostate) without any retraining. Beyond mere volumetric overlap, our agent-based paradigm offers near-instantaneous adaptability to alternative guidelines, providing a scalable and transparent pathway toward interpretability in radiotherapy treatment planning.
Multi-Class Segmentation of Aortic Branches and Zones in Computed Tomography Angiography: The AortaSeg24 Challenge
Feb 07, 2025



Multi-class segmentation of the aorta in computed tomography angiography (CTA) scans is essential for diagnosing and planning complex endovascular treatments for patients with aortic dissections. However, existing methods reduce aortic segmentation to a binary problem, limiting their ability to measure diameters across different branches and zones. Furthermore, no open-source dataset is currently available to support the development of multi-class aortic segmentation methods. To address this gap, we organized the AortaSeg24 MICCAI Challenge, introducing the first dataset of 100 CTA volumes annotated for 23 clinically relevant aortic branches and zones. This dataset was designed to facilitate both model development and validation. The challenge attracted 121 teams worldwide, with participants leveraging state-of-the-art frameworks such as nnU-Net and exploring novel techniques, including cascaded models, data augmentation strategies, and custom loss functions. We evaluated the submitted algorithms using the Dice Similarity Coefficient (DSC) and Normalized Surface Distance (NSD), highlighting the approaches adopted by the top five performing teams. This paper presents the challenge design, dataset details, evaluation metrics, and an in-depth analysis of the top-performing algorithms. The annotated dataset, evaluation code, and implementations of the leading methods are publicly available to support further research. All resources can be accessed at https://aortaseg24.grand-challenge.org.
RO-LLaMA: Generalist LLM for Radiation Oncology via Noise Augmentation and Consistency Regularization
Nov 27, 2023Recent advancements in Artificial Intelligence (AI) have profoundly influenced medical fields, by providing tools to reduce clinical workloads. However, most AI models are constrained to execute uni-modal tasks, in stark contrast to the comprehensive approaches utilized by medical professionals. To address this, here we present RO-LLaMA, a versatile generalist large language model (LLM) tailored for the field of radiation oncology. This model seamlessly covers a wide range of the workflow of radiation oncologists, adept at various tasks such as clinical report summarization, radiation therapy plan suggestion, and plan-guided therapy target volume segmentation. In particular, to maximize the end-to-end performance, we further present a novel Consistency Embedding Fine-Tuning (CEFTune) technique, which boosts LLM's robustness to additional errors at the intermediates while preserving the capability of handling clean inputs, and creatively transform this concept into LLM-driven segmentation framework as Consistency Embedding Segmentation (CESEG). Experimental results on multi-centre cohort sets demonstrate our proposed RO-LLaMA's promising performance for diverse tasks with generalization capabilities.
LLM-driven Multimodal Target Volume Contouring in Radiation Oncology
Nov 03, 2023Target volume contouring for radiation therapy is considered significantly more challenging than the normal organ segmentation tasks as it necessitates the utilization of both image and text-based clinical information. Inspired by the recent advancement of large language models (LLMs) that can facilitate the integration of the textural information and images, here we present a novel LLM-driven multi-modal AI that utilizes the clinical text information and is applicable to the challenging task of target volume contouring for radiation therapy, and validate it within the context of breast cancer radiation therapy target volume contouring. Using external validation and data-insufficient environments, which attributes highly conducive to real-world applications, we demonstrate that the proposed model exhibits markedly improved performance compared to conventional vision-only AI models, particularly exhibiting robust generalization performance and data-efficiency. To our best knowledge, this is the first LLM-driven multimodal AI model that integrates the clinical text information into target volume delineation for radiation oncology.
Reachable Set-based Path Planning for Automated Vertical Parking System
Aug 11, 2023



This paper proposes a local path planning method with a reachable set for Automated vertical Parking Systems (APS). First, given a parking lot layout with a goal position, we define an intermediate pose for the APS to accomplish reverse parking with a single maneuver, i.e., without changing the gear shift. Then, we introduce a reachable set which is a set of points consisting of the grid points of all possible intermediate poses. Once the APS approaches the goal position, it must select an intermediate pose in the reachable set. A minimization problem was formulated and solved to choose the intermediate pose. We performed various scenarios with different parking lot conditions. We used the Hybrid-A* algorithm for the global path planning to move the vehicle from the starting pose to the intermediate pose and utilized clothoid-based local path planning to move from the intermediate pose to the goal pose. Additionally, we designed a controller to follow the generated path and validated its tracking performance. It was confirmed that the tracking error in the mean root square for the lateral position was bounded within 0.06m and for orientation within 0.01rad.
Classification Method of Road Surface Condition and Type with LiDAR Using Spatiotemporal Information
Aug 11, 2023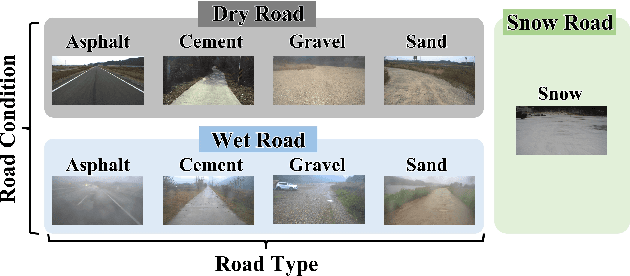
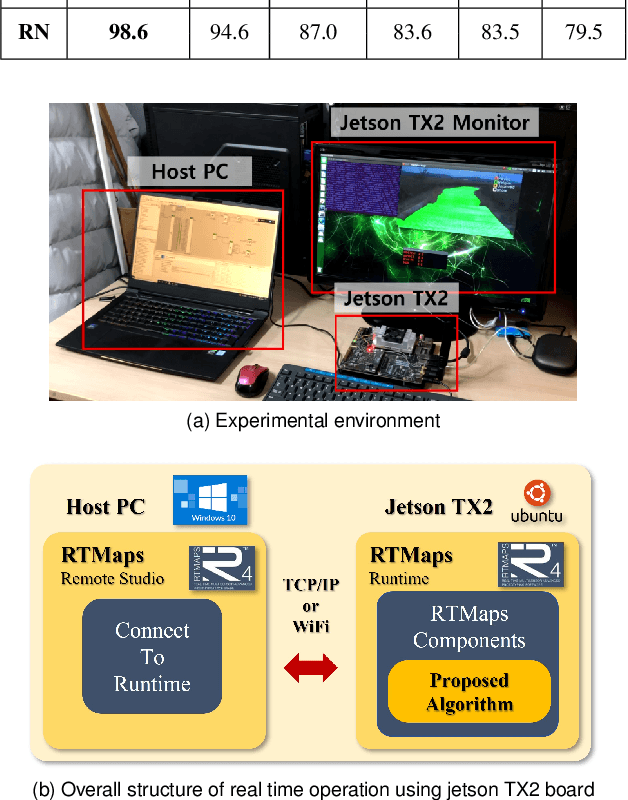
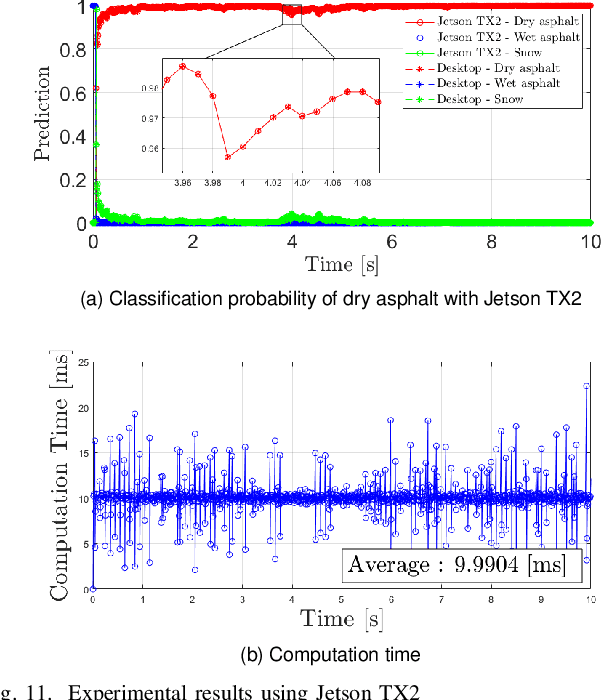
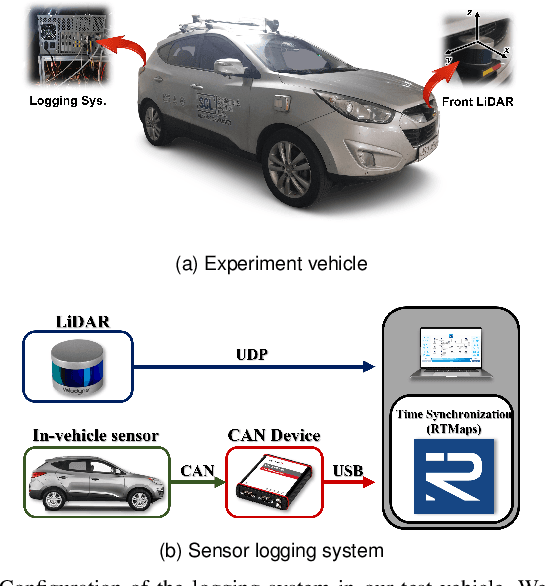
This paper proposes a spatiotemporal architecture with a deep neural network (DNN) for road surface conditions and types classification using LiDAR. It is known that LiDAR provides information on the reflectivity and number of point clouds depending on a road surface. Thus, this paper utilizes the information to classify the road surface. We divided the front road area into four subregions. First, we constructed feature vectors using each subregion's reflectivity, number of point clouds, and in-vehicle information. Second, the DNN classifies road surface conditions and types for each subregion. Finally, the output of the DNN feeds into the spatiotemporal process to make the final classification reflecting vehicle speed and probability given by the outcomes of softmax functions of the DNN output layer. To validate the effectiveness of the proposed method, we performed a comparative study with five other algorithms. With the proposed DNN, we obtained the highest accuracy of 98.0\% and 98.6\% for two subregions near the vehicle. In addition, we implemented the proposed method on the Jetson TX2 board to confirm that it is applicable in real-time.
Intentional Deep Overfit Learning (IDOL): A Novel Deep Learning Strategy for Adaptive Radiation Therapy
Apr 23, 2021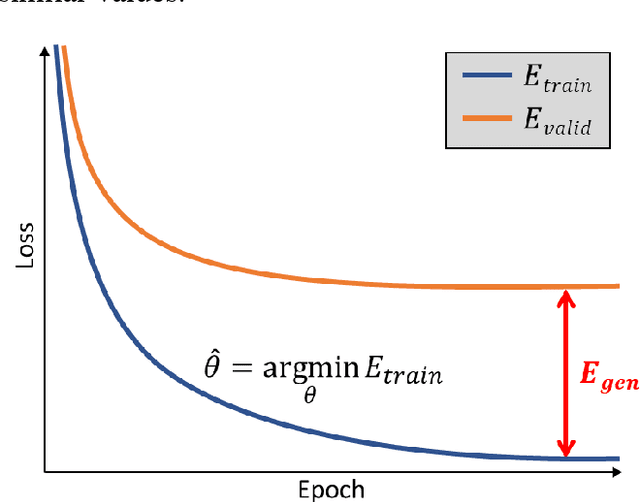
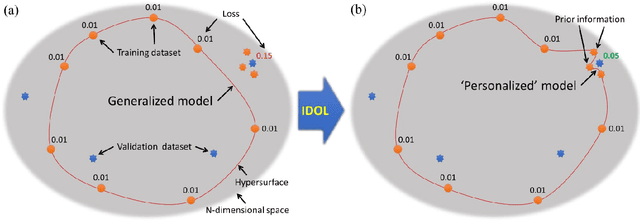
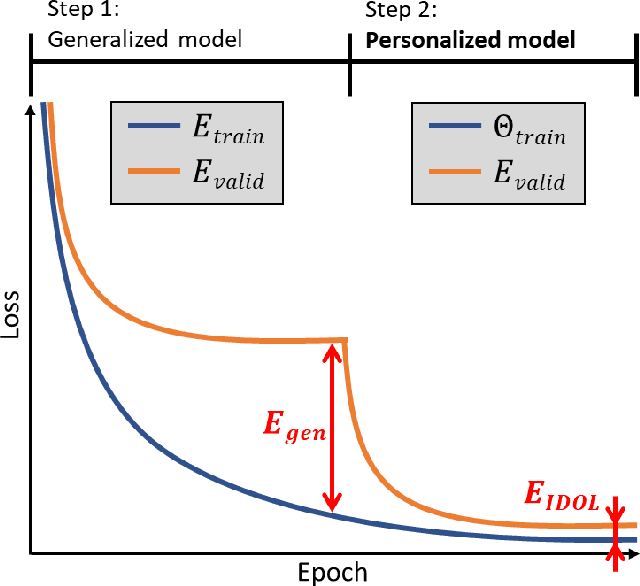
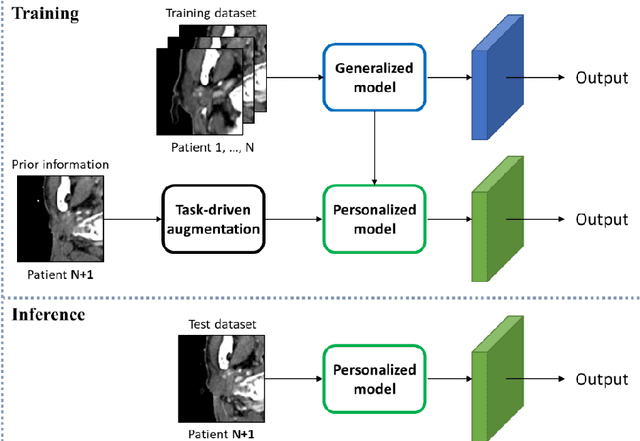
In this study, we propose a tailored DL framework for patient-specific performance that leverages the behavior of a model intentionally overfitted to a patient-specific training dataset augmented from the prior information available in an ART workflow - an approach we term Intentional Deep Overfit Learning (IDOL). Implementing the IDOL framework in any task in radiotherapy consists of two training stages: 1) training a generalized model with a diverse training dataset of N patients, just as in the conventional DL approach, and 2) intentionally overfitting this general model to a small training dataset-specific the patient of interest (N+1) generated through perturbations and augmentations of the available task- and patient-specific prior information to establish a personalized IDOL model. The IDOL framework itself is task-agnostic and is thus widely applicable to many components of the ART workflow, three of which we use as a proof of concept here: the auto-contouring task on re-planning CTs for traditional ART, the MRI super-resolution (SR) task for MRI-guided ART, and the synthetic CT (sCT) reconstruction task for MRI-only ART. In the re-planning CT auto-contouring task, the accuracy measured by the Dice similarity coefficient improves from 0.847 with the general model to 0.935 by adopting the IDOL model. In the case of MRI SR, the mean absolute error (MAE) is improved by 40% using the IDOL framework over the conventional model. Finally, in the sCT reconstruction task, the MAE is reduced from 68 to 22 HU by utilizing the IDOL framework.