 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatiotemporal Gaussian representation-based dynamic reconstruction and motion estimation framework for time-resolved volumetric MR imaging (DREME-GSMR)
Apr 07, 2026Time-resolved volumetric MR imaging that reconstructs a 3D MRI within sub-seconds to resolve deformable motion is essential for motion-adaptive radiotherapy. Representing patient anatomy and associated motion fields as 3D Gaussians, we developed a spatiotemporal Gaussian representation-based framework (DREME-GSMR), which enables time-resolved dynamic MRI reconstruction from a pre-treatment 3D MR scan without any prior anatomical/motion model. DREME-GSMR represents a reference MRI volume and a corresponding low-rank motion model (as motion-basis components) using 3D Gaussians, and incorporates a dual-path MLP/CNN motion encoder to estimate temporal motion coefficients of the motion model from raw k-space-derived signals. Furthermore, using the solved motion model, DREME-GSMR can infer motion coefficients directly from new online k-space data, allowing subsequent intra-treatment volumetric MR imaging and motion tracking (real-time imaging). A motion-augmentation strategy is further introduced to improve robustness to unseen motion patterns during real-time imaging. DREME-GSMR was evaluated on the XCAT digital phantom, a physical motion phantom, and MR-LINAC datasets acquired from 6 healthy volunteers and 20 patients (with independent sequential scans for cross-evaluation). DREME-GSMR reconstructs MRIs of a ~400ms temporal resolution, with an inference time of ~10ms/volume. In XCAT experiments, DREME-GSMR achieved mean(s.d.) SSIM, tumor center-of-mass-error(COME), and DSC of 0.92(0.01)/0.91(0.02), 0.50(0.15)/0.65(0.19) mm, and 0.92(0.02)/0.92(0.03) for dynamic reconstruction/real-time imaging. For the physical phantom, the mean target COME was 1.19(0.94)/1.40(1.15) mm for dynamic/real-time imaging, while for volunteers and patients, the mean liver COME for real-time imaging was 1.31(0.82) and 0.96(0.64) mm, respectively.
Adapting Segment Anything Model 3 for Concept-Driven Lesion Segmentation in Medical Images: An Experimental Study
Mar 26, 2026Accurate lesion segmentation is essential in medical image analysis, yet most existing methods are designed for specific anatomical sites or imaging modalities, limiting their generalizability. Recent vision-language foundation models enable concept-driven segmentation in natural images, offering a promising direction for more flexible medical image analysis. However, concept-prompt-based lesion segmentation, particularly with the latest Segment Anything Model 3 (SAM3), remains underexplored. In this work, we present a systematic evaluation of SAM3 for lesion segmentation. We assess its performance using geometric bounding boxes and concept-based text and image prompts across multiple modalities, including multiparametric MRI, CT, ultrasound, dermoscopy, and endoscopy. To improve robustness, we incorporate additional prior knowledge, such as adjacent-slice predictions, multiparametric information, and prior annotations. We further compare different fine-tuning strategies, including partial module tuning, adapter-based methods, and full-model optimization. Experiments on 13 datasets covering 11 lesion types demonstrate that SAM3 achieves strong cross-modality generalization, reliable concept-driven segmentation, and accurate lesion delineation. These results highlight the potential of concept-based foundation models for scalable and practical medical image segmentation. Code and trained models will be released at: https://github.com/apple1986/lesion-sam3
WeDefense: A Toolkit to Defend Against Fake Audio
Jan 21, 2026The advances in generative AI have enabled the creation of synthetic audio which is perceptually indistinguishable from real, genuine audio. Although this stellar progress enables many positive applications, it also raises risks of misuse, such as for impersonation, disinformation and fraud. Despite a growing number of open-source fake audio detection codes released through numerous challenges and initiatives, most are tailored to specific competitions, datasets or models. A standardized and unified toolkit that supports the fair benchmarking and comparison of competing solutions with not just common databases, protocols, metrics, but also a shared codebase, is missing. To address this, we propose WeDefense, the first open-source toolkit to support both fake audio detection and localization. Beyond model training, WeDefense emphasizes critical yet often overlooked components: flexible input and augmentation, calibration, score fusion, standardized evaluation metrics, and analysis tools for deeper understanding and interpretation. The toolkit is publicly available at https://github.com/zlin0/wedefense with interactive demos for fake audio detection and localization.
Exploiting DINOv3-Based Self-Supervised Features for Robust Few-Shot Medical Image Segmentation
Jan 12, 2026Deep learning-based automatic medical image segmentation plays a critical role in clinical diagnosis and treatment planning but remains challenging in few-shot scenarios due to the scarcity of annotated training data. Recently, self-supervised foundation models such as DINOv3, which were trained on large natural image datasets, have shown strong potential for dense feature extraction that can help with the few-shot learning challenge. Yet, their direct application to medical images is hindered by domain differences. In this work, we propose DINO-AugSeg, a novel framework that leverages DINOv3 features to address the few-shot medical image segmentation challenge. Specifically, we introduce WT-Aug, a wavelet-based feature-level augmentation module that enriches the diversity of DINOv3-extracted features by perturbing frequency components, and CG-Fuse, a contextual information-guided fusion module that exploits cross-attention to integrate semantic-rich low-resolution features with spatially detailed high-resolution features. Extensive experiments on six public benchmarks spanning five imaging modalities, including MRI, CT, ultrasound, endoscopy, and dermoscopy, demonstrate that DINO-AugSeg consistently outperforms existing methods under limited-sample conditions. The results highlight the effectiveness of incorporating wavelet-domain augmentation and contextual fusion for robust feature representation, suggesting DINO-AugSeg as a promising direction for advancing few-shot medical image segmentation. Code and data will be made available on https://github.com/apple1986/DINO-AugSeg.
How Does Instrumental Music Help SingFake Detection?
Sep 18, 2025Although many models exist to detect singing voice deepfakes (SingFake), how these models operate, particularly with instrumental accompaniment, is unclear. We investigate how instrumental music affects SingFake detection from two perspectives. To investigate the behavioral effect, we test different backbones, unpaired instrumental tracks, and frequency subbands. To analyze the representational effect, we probe how fine-tuning alters encoders' speech and music capabilities. Our results show that instrumental accompaniment acts mainly as data augmentation rather than providing intrinsic cues (e.g., rhythm or harmony). Furthermore, fine-tuning increases reliance on shallow speaker features while reducing sensitivity to content, paralinguistic, and semantic information. These insights clarify how models exploit vocal versus instrumental cues and can inform the design of more interpretable and robust SingFake detection systems.
Segment Anything for Video: A Comprehensive Review of Video Object Segmentation and Tracking from Past to Future
Jul 30, 2025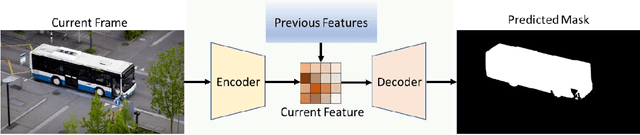
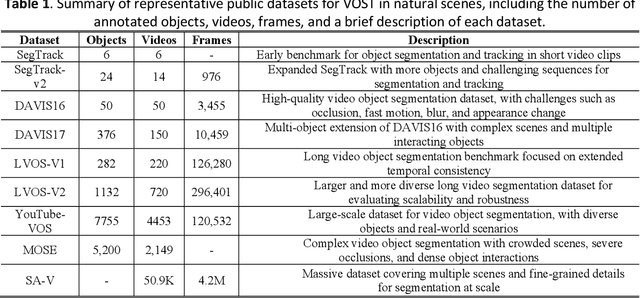
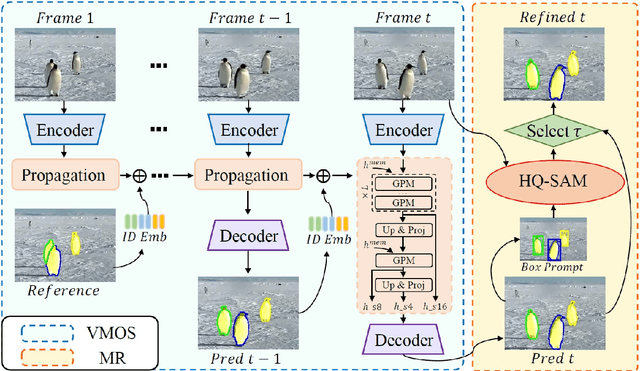
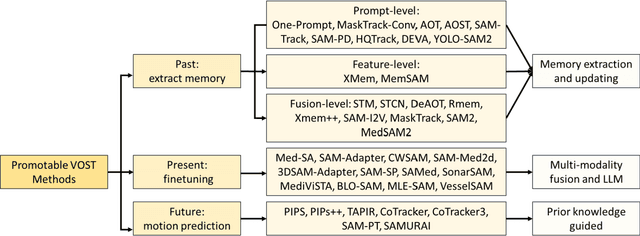
Video Object Segmentation and Tracking (VOST) presents a complex yet critical challenge in computer vision, requiring robust integration of segmentation and tracking across temporally dynamic frames. Traditional methods have struggled with domain generalization, temporal consistency, and computational efficiency. The emergence of foundation models like the Segment Anything Model (SAM) and its successor, SAM2, has introduced a paradigm shift, enabling prompt-driven segmentation with strong generalization capabilities. Building upon these advances, this survey provides a comprehensive review of SAM/SAM2-based methods for VOST, structured along three temporal dimensions: past, present, and future. We examine strategies for retaining and updating historical information (past), approaches for extracting and optimizing discriminative features from the current frame (present), and motion prediction and trajectory estimation mechanisms for anticipating object dynamics in subsequent frames (future). In doing so, we highlight the evolution from early memory-based architectures to the streaming memory and real-time segmentation capabilities of SAM2. We also discuss recent innovations such as motion-aware memory selection and trajectory-guided prompting, which aim to enhance both accuracy and efficiency. Finally, we identify remaining challenges including memory redundancy, error accumulation, and prompt inefficiency, and suggest promising directions for future research. This survey offers a timely and structured overview of the field, aiming to guide researchers and practitioners in advancing the state of VOST through the lens of foundation models.
Towards Perception-Informed Latent HRTF Representations
Jul 03, 2025Personalized head-related transfer functions (HRTFs) are essential for ensuring a realistic auditory experience over headphones, because they take into account individual anatomical differences that affect listening. Most machine learning approaches to HRTF personalization rely on a learned low-dimensional latent space to generate or select custom HRTFs for a listener. However, these latent representations are typically learned in a manner that optimizes for spectral reconstruction but not for perceptual compatibility, meaning they may not necessarily align with perceptual distance. In this work, we first study whether traditionally learned HRTF representations are well correlated with perceptual relations using auditory-based objective perceptual metrics; we then propose a method for explicitly embedding HRTFs into a perception-informed latent space, leveraging a metric-based loss function and supervision via Metric Multidimensional Scaling (MMDS). Finally, we demonstrate the applicability of these learned representations to the task of HRTF personalization. We suggest that our method has the potential to render personalized spatial audio, leading to an improved listening experience.
SAM-aware Test-time Adaptation for Universal Medical Image Segmentation
Jun 05, 2025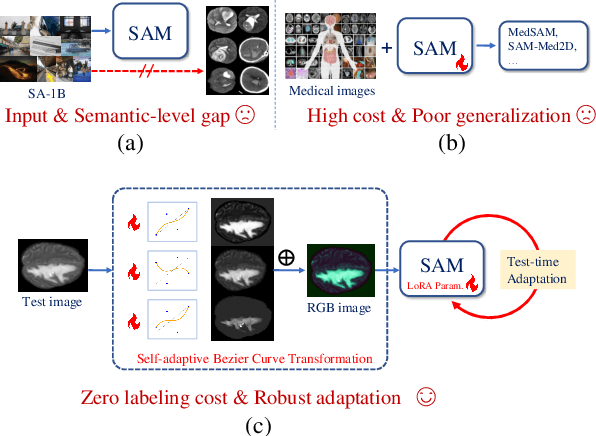
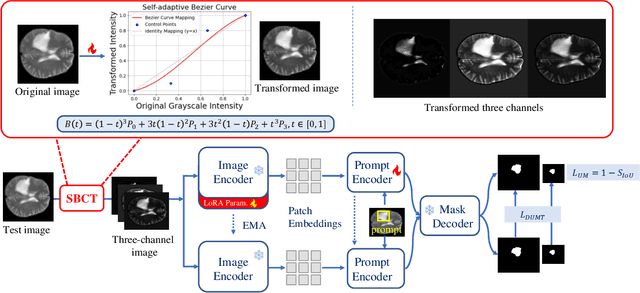
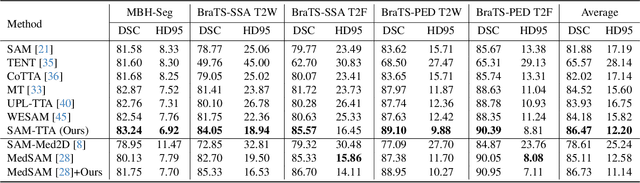
Universal medical image segmentation using the Segment Anything Model (SAM) remains challenging due to its limited adaptability to medical domains. Existing adaptations, such as MedSAM, enhance SAM's performance in medical imaging but at the cost of reduced generalization to unseen data. Therefore, in this paper, we propose SAM-aware Test-Time Adaptation (SAM-TTA), a fundamentally different pipeline that preserves the generalization of SAM while improving its segmentation performance in medical imaging via a test-time framework. SAM-TTA tackles two key challenges: (1) input-level discrepancies caused by differences in image acquisition between natural and medical images and (2) semantic-level discrepancies due to fundamental differences in object definition between natural and medical domains (e.g., clear boundaries vs. ambiguous structures). Specifically, our SAM-TTA framework comprises (1) Self-adaptive Bezier Curve-based Transformation (SBCT), which adaptively converts single-channel medical images into three-channel SAM-compatible inputs while maintaining structural integrity, to mitigate the input gap between medical and natural images, and (2) Dual-scale Uncertainty-driven Mean Teacher adaptation (DUMT), which employs consistency learning to align SAM's internal representations to medical semantics, enabling efficient adaptation without auxiliary supervision or expensive retraining. Extensive experiments on five public datasets demonstrate that our SAM-TTA outperforms existing TTA approaches and even surpasses fully fine-tuned models such as MedSAM in certain scenarios, establishing a new paradigm for universal medical image segmentation. Code can be found at https://github.com/JianghaoWu/SAM-TTA.
Time-resolved dynamic CBCT reconstruction using prior-model-free spatiotemporal Gaussian representation (PMF-STGR)
Mar 28, 2025Time-resolved CBCT imaging, which reconstructs a dynamic sequence of CBCTs reflecting intra-scan motion (one CBCT per x-ray projection without phase sorting or binning), is highly desired for regular and irregular motion characterization, patient setup, and motion-adapted radiotherapy. Representing patient anatomy and associated motion fields as 3D Gaussians, we developed a Gaussian representation-based framework (PMF-STGR) for fast and accurate dynamic CBCT reconstruction. PMF-STGR comprises three major components: a dense set of 3D Gaussians to reconstruct a reference-frame CBCT for the dynamic sequence; another 3D Gaussian set to capture three-level, coarse-to-fine motion-basis-components (MBCs) to model the intra-scan motion; and a CNN-based motion encoder to solve projection-specific temporal coefficients for the MBCs. Scaled by the temporal coefficients, the learned MBCs will combine into deformation vector fields to deform the reference CBCT into projection-specific, time-resolved CBCTs to capture the dynamic motion. Due to the strong representation power of 3D Gaussians, PMF-STGR can reconstruct dynamic CBCTs in a 'one-shot' training fashion from a standard 3D CBCT scan, without using any prior anatomical or motion model. We evaluated PMF-STGR using XCAT phantom simulations and real patient scans. Metrics including the image relative error, structural-similarity-index-measure, tumor center-of-mass-error, and landmark localization error were used to evaluate the accuracy of solved dynamic CBCTs and motion. PMF-STGR shows clear advantages over a state-of-the-art, INR-based approach, PMF-STINR. Compared with PMF-STINR, PMF-STGR reduces reconstruction time by 50% while reconstructing less blurred images with better motion accuracy. With improved efficiency and accuracy, PMF-STGR enhances the applicability of dynamic CBCT imaging for potential clinical translation.
Multi-Attribute Multi-Grained Adaptation of Pre-Trained Language Models for Text Understanding from Bayesian Perspective
Mar 08, 2025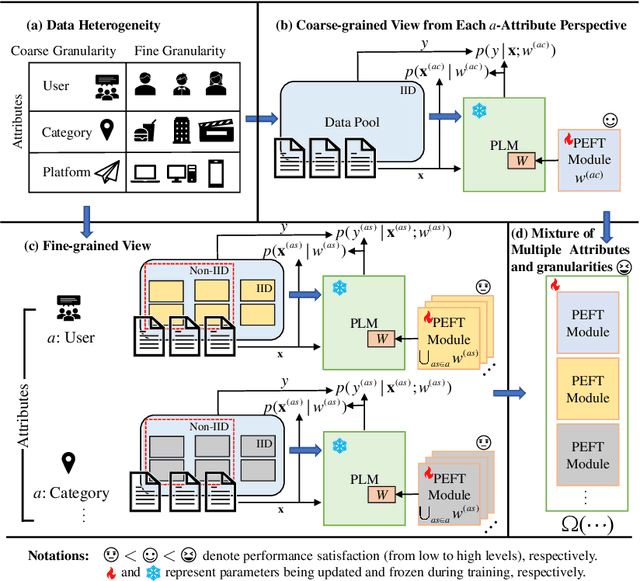
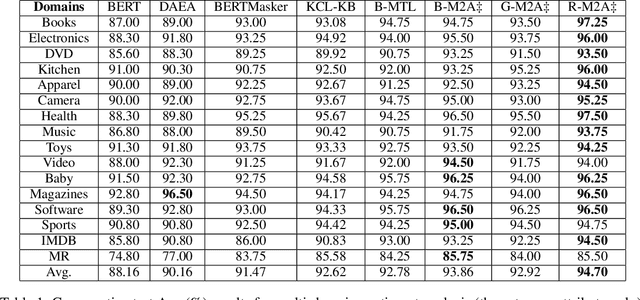
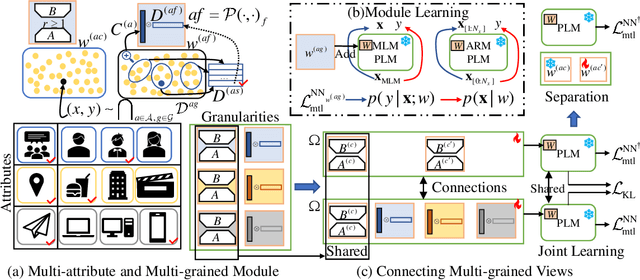
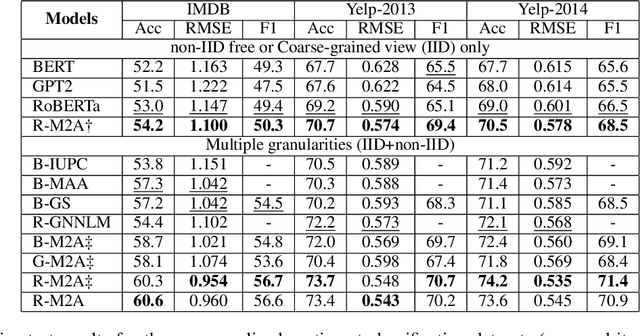
Current neural networks often employ multi-domain-learning or attribute-injecting mechanisms to incorporate non-independent and identically distributed (non-IID) information for text understanding tasks by capturing individual characteristics and the relationships among samples. However, the extent of the impact of non-IID information and how these methods affect pre-trained language models (PLMs) remains unclear. This study revisits the assumption that non-IID information enhances PLMs to achieve performance improvements from a Bayesian perspective, which unearths and integrates non-IID and IID features. Furthermore, we proposed a multi-attribute multi-grained framework for PLM adaptations (M2A), which combines multi-attribute and multi-grained views to mitigate uncertainty in a lightweight manner. We evaluate M2A through prevalent text-understanding datasets and demonstrate its superior performance, mainly when data are implicitly non-IID, and PLMs scale larger.