 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscrete Audio Tokens: More Than a Survey!
Jun 12, 2025Discrete audio tokens are compact representations that aim to preserve perceptual quality, phonetic content, and speaker characteristics while enabling efficient storage and inference, as well as competitive performance across diverse downstream tasks.They provide a practical alternative to continuous features, enabling the integration of speech and audio into modern large language models (LLMs). As interest in token-based audio processing grows, various tokenization methods have emerged, and several surveys have reviewed the latest progress in the field. However, existing studies often focus on specific domains or tasks and lack a unified comparison across various benchmarks. This paper presents a systematic review and benchmark of discrete audio tokenizers, covering three domains: speech, music, and general audio. We propose a taxonomy of tokenization approaches based on encoder-decoder, quantization techniques, training paradigm, streamability, and application domains. We evaluate tokenizers on multiple benchmarks for reconstruction, downstream performance, and acoustic language modeling, and analyze trade-offs through controlled ablation studies. Our findings highlight key limitations, practical considerations, and open challenges, providing insight and guidance for future research in this rapidly evolving area. For more information, including our main results and tokenizer database, please refer to our website: https://poonehmousavi.github.io/dates-website/.
Seeing Sound: Assembling Sounds from Visuals for Audio-to-Image Generation
Jan 09, 2025Training audio-to-image generative models requires an abundance of diverse audio-visual pairs that are semantically aligned. Such data is almost always curated from in-the-wild videos, given the cross-modal semantic correspondence that is inherent to them. In this work, we hypothesize that insisting on the absolute need for ground truth audio-visual correspondence, is not only unnecessary, but also leads to severe restrictions in scale, quality, and diversity of the data, ultimately impairing its use in the modern generative models. That is, we propose a scalable image sonification framework where instances from a variety of high-quality yet disjoint uni-modal origins can be artificially paired through a retrieval process that is empowered by reasoning capabilities of modern vision-language models. To demonstrate the efficacy of this approach, we use our sonified images to train an audio-to-image generative model that performs competitively against state-of-the-art. Finally, through a series of ablation studies, we exhibit several intriguing auditory capabilities like semantic mixing and interpolation, loudness calibration and acoustic space modeling through reverberation that our model has implicitly developed to guide the image generation process.
VERSA: A Versatile Evaluation Toolkit for Speech, Audio, and Music
Dec 23, 2024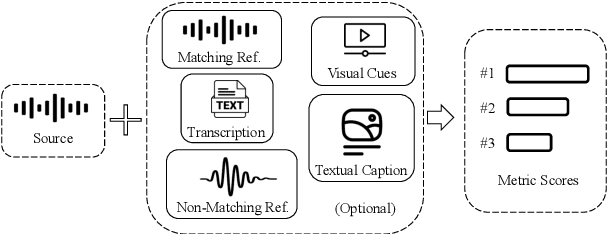
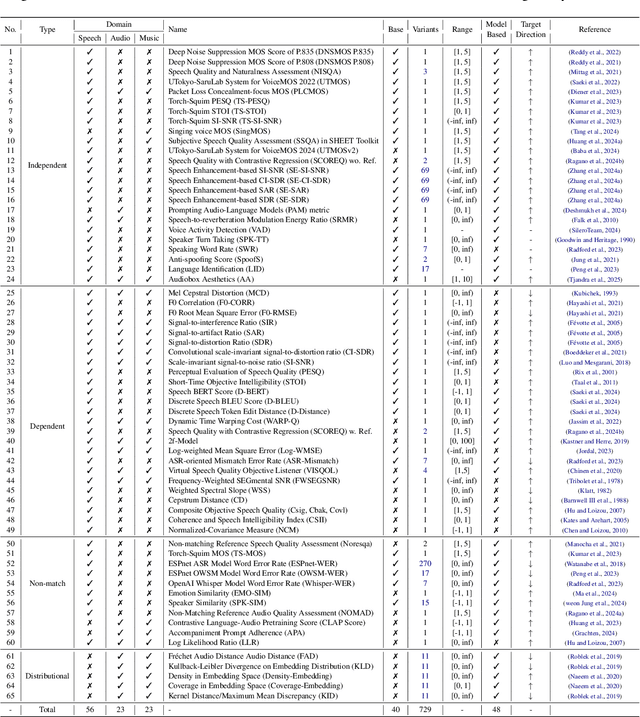

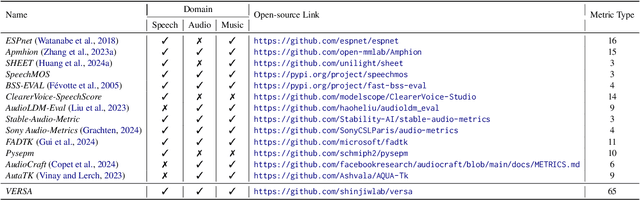
In this work, we introduce VERSA, a unified and standardized evaluation toolkit designed for various speech, audio, and music signals. The toolkit features a Pythonic interface with flexible configuration and dependency control, making it user-friendly and efficient. With full installation, VERSA offers 63 metrics with 711 metric variations based on different configurations. These metrics encompass evaluations utilizing diverse external resources, including matching and non-matching reference audio, text transcriptions, and text captions. As a lightweight yet comprehensive toolkit, VERSA is versatile to support the evaluation of a wide range of downstream scenarios. To demonstrate its capabilities, this work highlights example use cases for VERSA, including audio coding, speech synthesis, speech enhancement, singing synthesis, and music generation. The toolkit is available at https://github.com/shinjiwlab/versa.
Hyperbolic Distance-Based Speech Separation
Jan 07, 2024In this work, we explore the task of hierarchical distance-based speech separation defined on a hyperbolic manifold. Based on the recent advent of audio-related tasks performed in non-Euclidean spaces, we propose to make use of the Poincar\'e ball to effectively unveil the inherent hierarchical structure found in complex speaker mixtures. We design two sets of experiments in which the distance-based parent sound classes, namely "near" and "far", can contain up to two or three speakers (i.e., children) each. We show that our hyperbolic approach is suitable for unveiling hierarchical structure from the problem definition, resulting in improved child-level separation. We further show that a clear correlation emerges between the notion of hyperbolic certainty (i.e., the distance to the ball's origin) and acoustic semantics such as speaker density, inter-source location, and microphone-to-speaker distance.
Native Multi-Band Audio Coding within Hyper-Autoencoded Reconstruction Propagation Networks
Mar 14, 2023Spectral sub-bands do not portray the same perceptual relevance. In audio coding, it is therefore desirable to have independent control over each of the constituent bands so that bitrate assignment and signal reconstruction can be achieved efficiently. In this work, we present a novel neural audio coding network that natively supports a multi-band coding paradigm. Our model extends the idea of compressed skip connections in the U-Net-based codec, allowing for independent control over both core and high band-specific reconstructions and bit allocation. Our system reconstructs the full-band signal mainly from the condensed core-band code, therefore exploiting and showcasing its bandwidth extension capabilities to its fullest. Meanwhile, the low-bitrate high-band code helps the high-band reconstruction similarly to MPEG audio codecs' spectral bandwidth replication. MUSHRA tests show that the proposed model not only improves the quality of the core band by explicitly assigning more bits to it but retains a good quality in the high-band as well.
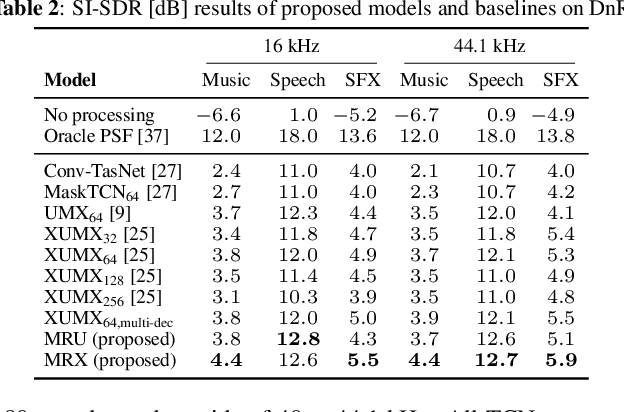
Tackling the Cocktail Fork Problem for Separation and Transcription of Real-World Soundtracks
Dec 14, 2022
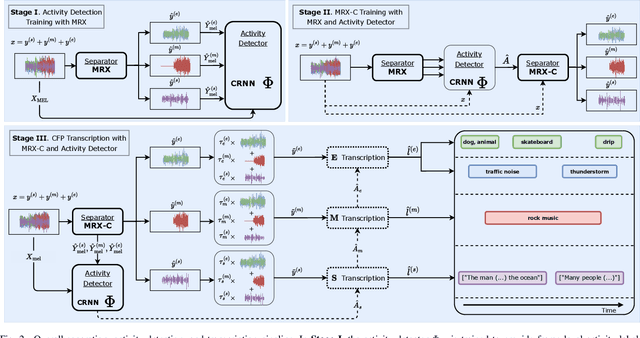
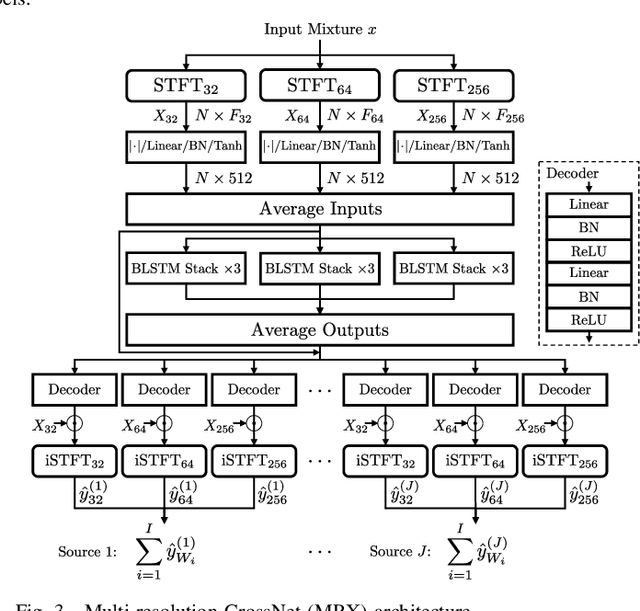
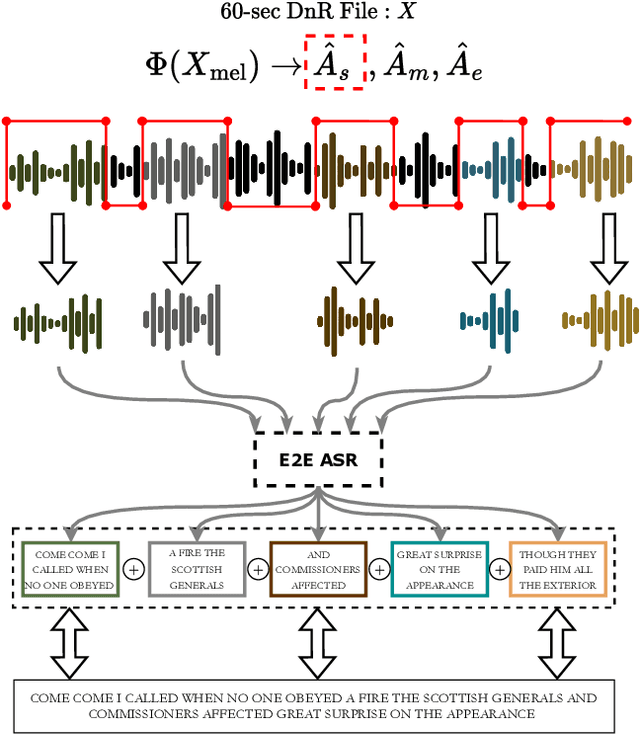
Emulating the human ability to solve the cocktail party problem, i.e., focus on a source of interest in a complex acoustic scene, is a long standing goal of audio source separation research. Much of this research investigates separating speech from noise, speech from speech, musical instruments from each other, or sound events from each other. In this paper, we focus on the cocktail fork problem, which takes a three-pronged approach to source separation by separating an audio mixture such as a movie soundtrack or podcast into the three broad categories of speech, music, and sound effects (SFX - understood to include ambient noise and natural sound events). We benchmark the performance of several deep learning-based source separation models on this task and evaluate them with respect to simple objective measures such as signal-to-distortion ratio (SDR) as well as objective metrics that better correlate with human perception. Furthermore, we thoroughly evaluate how source separation can influence downstream transcription tasks. First, we investigate the task of activity detection on the three sources as a way to both further improve source separation and perform transcription. We formulate the transcription tasks as speech recognition for speech and audio tagging for music and SFX. We observe that, while the use of source separation estimates improves transcription performance in comparison to the original soundtrack, performance is still sub-optimal due to artifacts introduced by the separation process. Therefore, we thoroughly investigate how remixing of the three separated source stems at various relative levels can reduce artifacts and consequently improve the transcription performance. We find that remixing music and SFX interferences at a target SNR of 17.5 dB reduces speech recognition word error rate, and similar impact from remixing is observed for tagging music and SFX content.
Hyperbolic Audio Source Separation
Dec 09, 2022We introduce a framework for audio source separation using embeddings on a hyperbolic manifold that compactly represent the hierarchical relationship between sound sources and time-frequency features. Inspired by recent successes modeling hierarchical relationships in text and images with hyperbolic embeddings, our algorithm obtains a hyperbolic embedding for each time-frequency bin of a mixture signal and estimates masks using hyperbolic softmax layers. On a synthetic dataset containing mixtures of multiple people talking and musical instruments playing, our hyperbolic model performed comparably to a Euclidean baseline in terms of source to distortion ratio, with stronger performance at low embedding dimensions. Furthermore, we find that time-frequency regions containing multiple overlapping sources are embedded towards the center (i.e., the most uncertain region) of the hyperbolic space, and we can use this certainty estimate to efficiently trade-off between artifact introduction and interference reduction when isolating individual sounds.
SpaIn-Net: Spatially-Informed Stereophonic Music Source Separation
Feb 15, 2022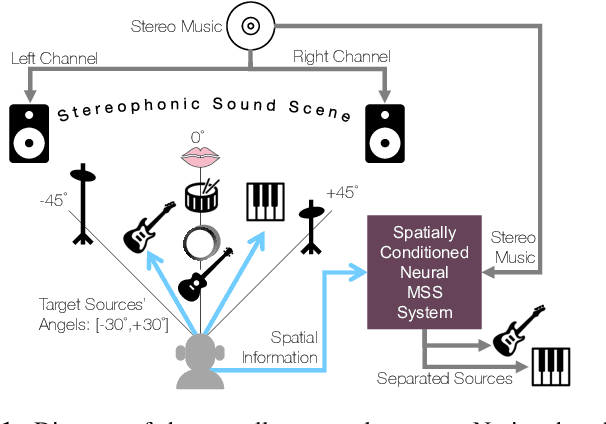

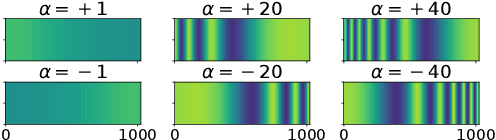

With the recent advancements of data driven approaches using deep neural networks, music source separation has been formulated as an instrument-specific supervised problem. While existing deep learning models implicitly absorb the spatial information conveyed by the multi-channel input signals, we argue that a more explicit and active use of spatial information could not only improve the separation process but also provide an entry-point for many user-interaction based tools. To this end, we introduce a control method based on the stereophonic location of the sources of interest, expressed as the panning angle. We present various conditioning mechanisms, including the use of raw angle and its derived feature representations, and show that spatial information helps. Our proposed approaches improve the separation performance compared to location agnostic architectures by 1.8 dB SI-SDR in our Slakh-based simulated experiments. Furthermore, the proposed methods allow for the disentanglement of same-class instruments, for example, in mixtures containing two guitar tracks. Finally, we also demonstrate that our approach is robust to incorrect source panning information, which can be incurred by our proposed user interaction.
The Cocktail Fork Problem: Three-Stem Audio Separation for Real-World Soundtracks
Oct 19, 2021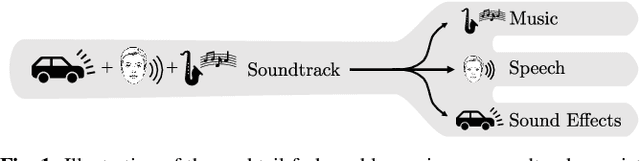


The cocktail party problem aims at isolating any source of interest within a complex acoustic scene, and has long inspired audio source separation research. Recent efforts have mainly focused on separating speech from noise, speech from speech, musical instruments from each other, or sound events from each other. However, separating an audio mixture (e.g., movie soundtrack) into the three broad categories of speech, music, and sound effects (here understood to include ambient noise and natural sound events) has been left largely unexplored, despite a wide range of potential applications. This paper formalizes this task as the cocktail fork problem, and presents the Divide and Remaster (DnR) dataset to foster research on this topic. DnR is built from three well-established audio datasets (LibriVox, FMA, FSD50k), taking care to reproduce conditions similar to professionally produced content in terms of source overlap and relative loudness, and made available at CD quality. We benchmark standard source separation algorithms on DnR, and further introduce a new mixed-STFT-resolution model to better address the variety of acoustic characteristics of the three source types. Our best model produces SI-SDR improvements over the mixture of 11.3 dB for music, 11.8 dB for speech, and 10.9 dB for sound effects.
HARP-Net: Hyper-Autoencoded Reconstruction Propagation for Scalable Neural Audio Coding
Jul 23, 2021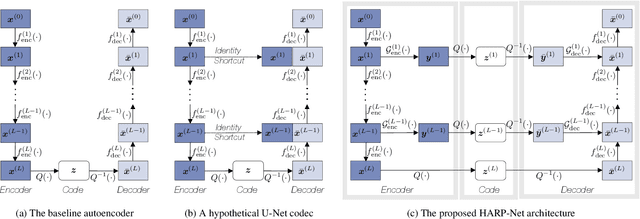

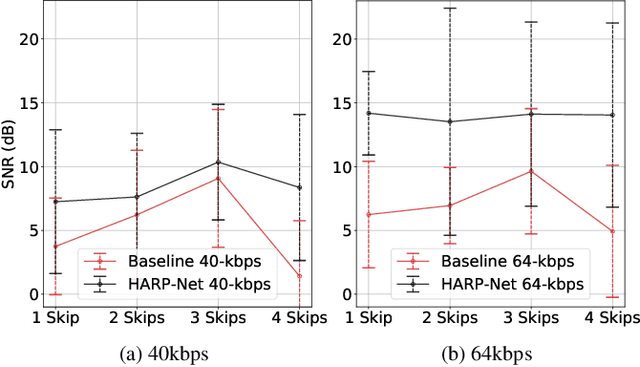
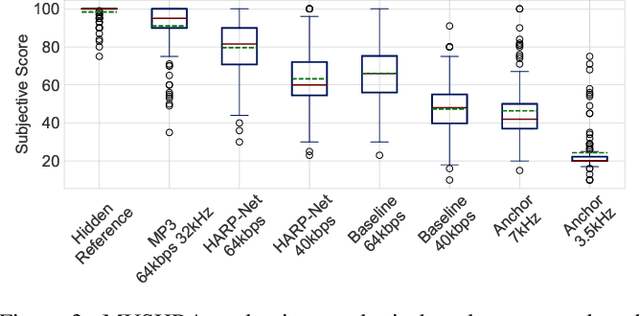
An autoencoder-based codec employs quantization to turn its bottleneck layer activation into bitstrings, a process that hinders information flow between the encoder and decoder parts. To circumvent this issue, we employ additional skip connections between the corresponding pair of encoder-decoder layers. The assumption is that, in a mirrored autoencoder topology, a decoder layer reconstructs the intermediate feature representation of its corresponding encoder layer. Hence, any additional information directly propagated from the corresponding encoder layer helps the reconstruction. We implement this kind of skip connections in the form of additional autoencoders, each of which is a small codec that compresses the massive data transfer between the paired encoder-decoder layers. We empirically verify that the proposed hyper-autoencoded architecture improves perceptual audio quality compared to an ordinary autoencoder baseline.