 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalized Neural Speech Codec
Mar 31, 2024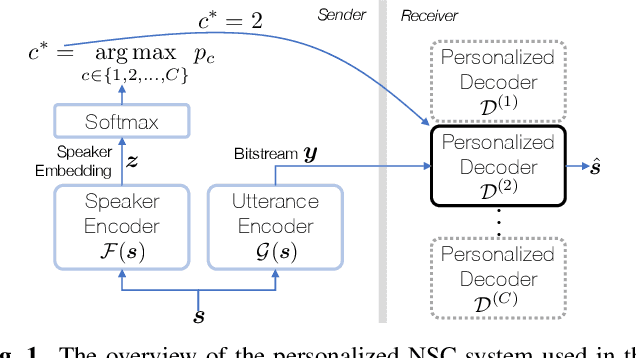



In this paper, we propose a personalized neural speech codec, envisioning that personalization can reduce the model complexity or improve perceptual speech quality. Despite the common usage of speech codecs where only a single talker is involved on each side of the communication, personalizing a codec for the specific user has rarely been explored in the literature. First, we assume speakers can be grouped into smaller subsets based on their perceptual similarity. Then, we also postulate that a group-specific codec can focus on the group's speech characteristics to improve its perceptual quality and computational efficiency. To this end, we first develop a Siamese network that learns the speaker embeddings from the LibriSpeech dataset, which are then grouped into underlying speaker clusters. Finally, we retrain the LPCNet-based speech codec baselines on each of the speaker clusters. Subjective listening tests show that the proposed personalization scheme introduces model compression while maintaining speech quality. In other words, with the same model complexity, personalized codecs produce better speech quality.
Hybrid noise shaping for audio coding using perfectly overlapped window
Aug 24, 2023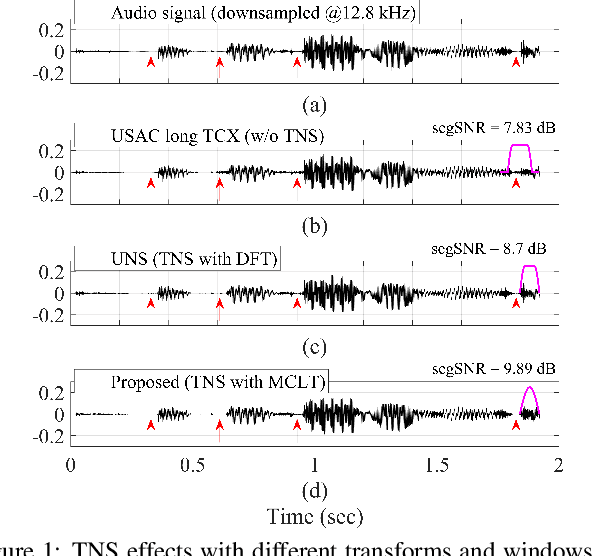
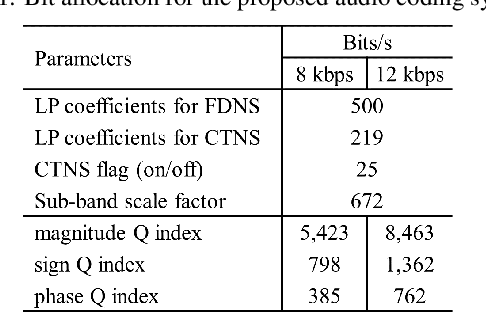
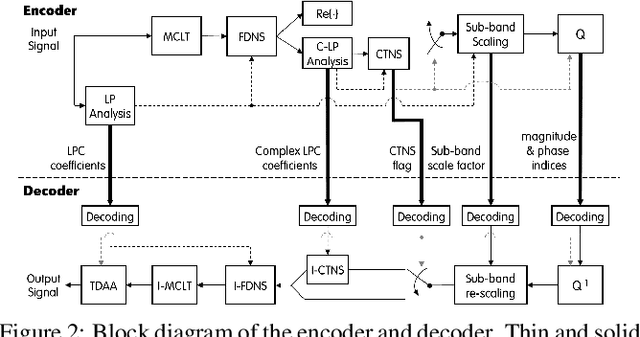
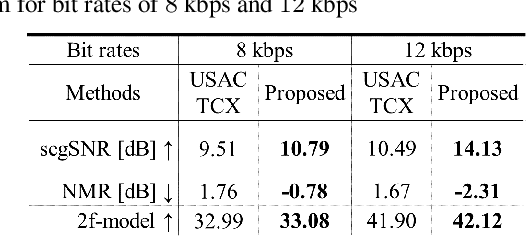
In recent years, audio coding technology has been standardized based on several frameworks that incorporate linear predictive coding (LPC). However, coding the transient signal using frequency-domain LP residual signals remains a challenge. To address this, temporal noise shaping (TNS) can be adapted, although it cannot be effectively operated since the estimated temporal envelope in the modified discrete cosine transform (MDCT) domain is accompanied by the time-domain aliasing (TDA) terms. In this study, we propose the modulated complex lapped transform-based coding framework integrated with transform coded excitation (TCX) and complex LPC-based TNS (CTNS). Our approach uses a 50\% overlap window and switching scheme for the CTNS to improve the coding efficiency. Additionally, an adaptive calculation of the target bits for the sub-bands using the frequency envelope information based on the quantized LPC coefficients is proposed. To minimize the quantization mismatch between both modes, an integrated quantization for real and complex values and a TDA augmentation method that compensates for the artificially generated TDA components during switching operations are proposed. The proposed coding framework shows a superior performance in both objective metrics and subjective listening tests, thereby demonstrating its low bit-rate audio coding.
Audio coding with unified noise shaping and phase contrast control
Apr 17, 2023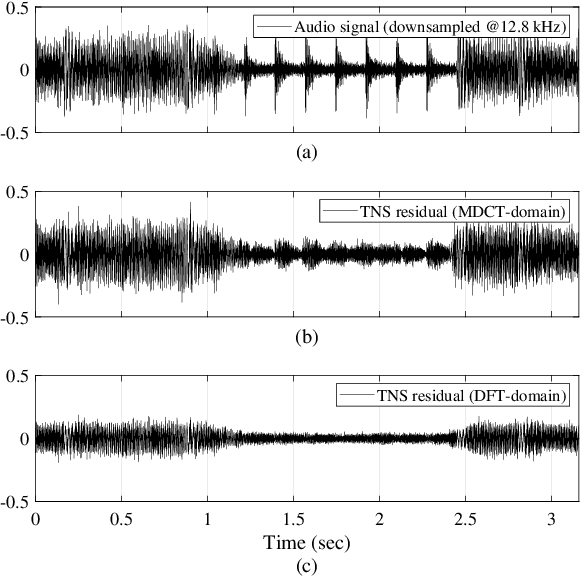


Over the past decade, audio coding technology has seen standardization and the development of many frameworks incorporated with linear predictive coding (LPC). As LPC reduces information in the frequency domain, LP-based frequency-domain noise-shaping (FDNS) was previously proposed. To code transient signals effectively, FDNS with temporal noise shaping (TNS) has emerged. However, these mainly operated in the modified discrete cosine transform domain, which essentially accompanies time domain aliasing. In this paper, a unified noise-shaping (UNS) framework including FDNS and complex LPC-based TNS (CTNS) in the DFT domain is proposed to overcome the aliasing issues. Additionally, a modified polar quantizer with phase contrast control is proposed, which saves phase bits depending on the frequency envelope information. The core coding feasibility at low bit rates is verified through various objective metrics and subjective listening evaluations.
HARP-Net: Hyper-Autoencoded Reconstruction Propagation for Scalable Neural Audio Coding
Jul 23, 2021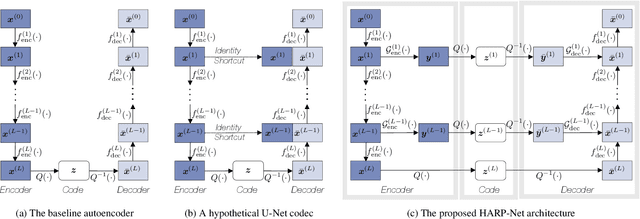

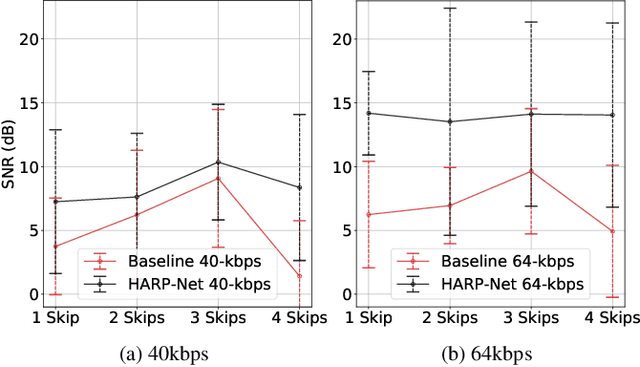
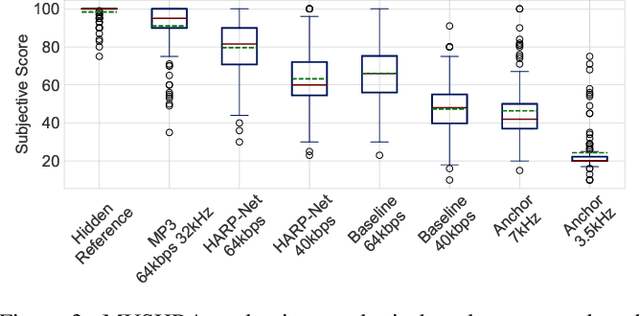
An autoencoder-based codec employs quantization to turn its bottleneck layer activation into bitstrings, a process that hinders information flow between the encoder and decoder parts. To circumvent this issue, we employ additional skip connections between the corresponding pair of encoder-decoder layers. The assumption is that, in a mirrored autoencoder topology, a decoder layer reconstructs the intermediate feature representation of its corresponding encoder layer. Hence, any additional information directly propagated from the corresponding encoder layer helps the reconstruction. We implement this kind of skip connections in the form of additional autoencoders, each of which is a small codec that compresses the massive data transfer between the paired encoder-decoder layers. We empirically verify that the proposed hyper-autoencoded architecture improves perceptual audio quality compared to an ordinary autoencoder baseline.
Psychoacoustic Calibration of Loss Functions for Efficient End-to-End Neural Audio Coding
Dec 31, 2020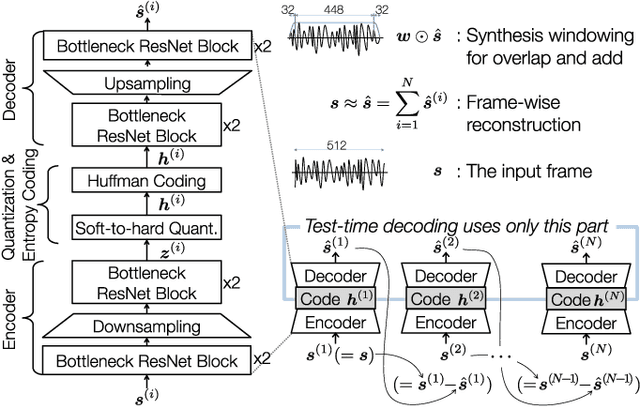
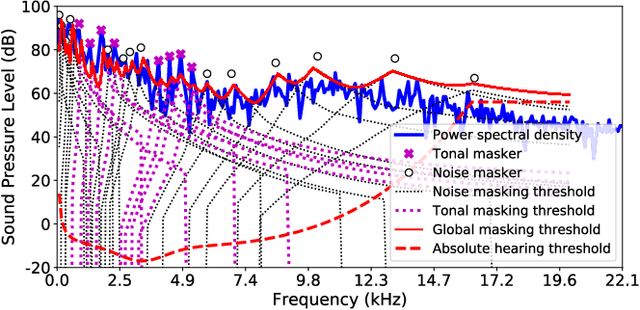
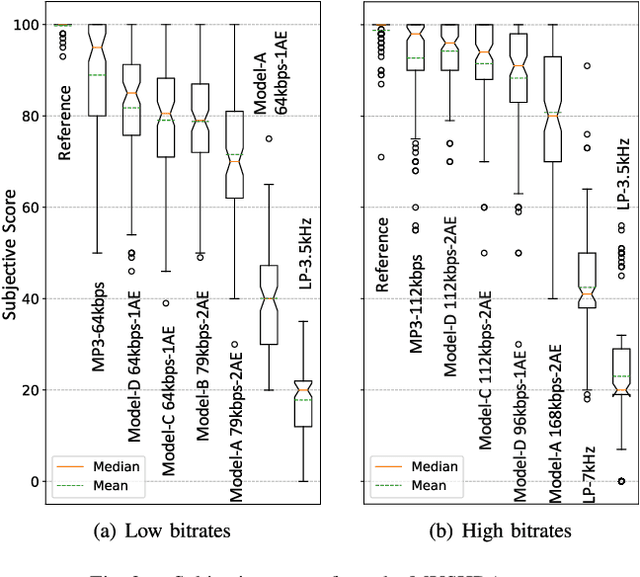
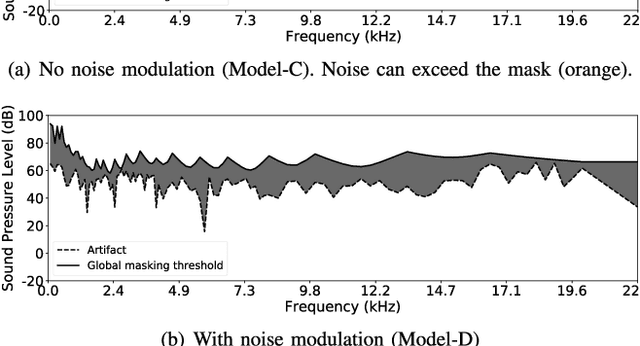
Conventional audio coding technologies commonly leverage human perception of sound, or psychoacoustics, to reduce the bitrate while preserving the perceptual quality of the decoded audio signals. For neural audio codecs, however, the objective nature of the loss function usually leads to suboptimal sound quality as well as high run-time complexity due to the large model size. In this work, we present a psychoacoustic calibration scheme to re-define the loss functions of neural audio coding systems so that it can decode signals more perceptually similar to the reference, yet with a much lower model complexity. The proposed loss function incorporates the global masking threshold, allowing the reconstruction error that corresponds to inaudible artifacts. Experimental results show that the proposed model outperforms the baseline neural codec twice as large and consuming 23.4% more bits per second. With the proposed method, a lightweight neural codec, with only 0.9 million parameters, performs near-transparent audio coding comparable with the commercial MPEG-1 Audio Layer III codec at 112 kbps.
Cascaded Cross-Module Residual Learning towards Lightweight End-to-End Speech Coding
Jun 18, 2019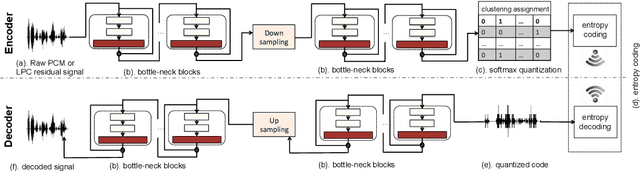
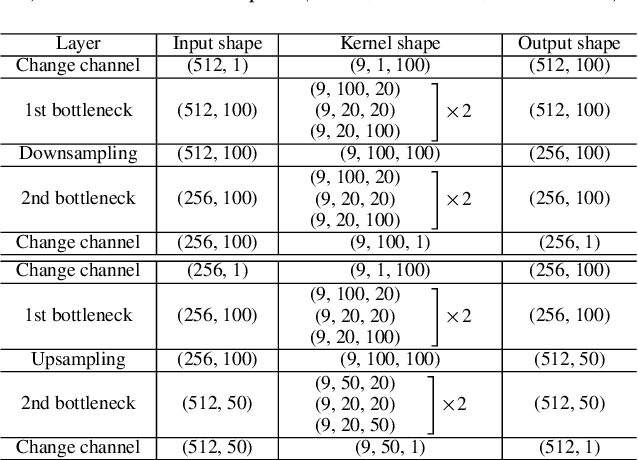
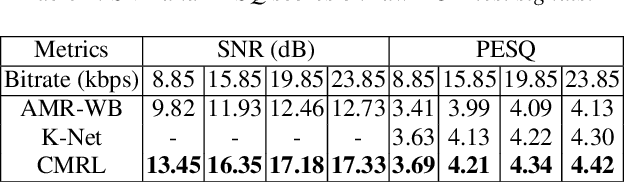
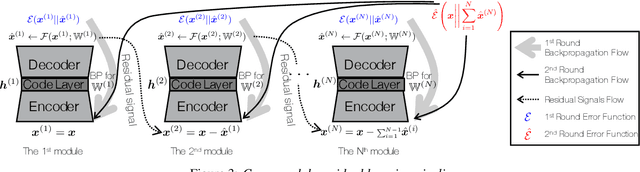
Speech codecs learn compact representations of speech signals to facilitate data transmission. Many recent deep neural network (DNN) based end-to-end speech codecs achieve low bitrates and high perceptual quality at the cost of model complexity. We propose a cross-module residual learning (CMRL) pipeline as a module carrier with each module reconstructing the residual from its preceding modules. CMRL differs from other DNN-based speech codecs, in that rather than modeling speech compression problem in a single large neural network, it optimizes a series of less-complicated modules in a two-phase training scheme. The proposed method shows better objective performance than AMR-WB and the state-of-the-art DNN-based speech codec with a similar network architecture. As an end-to-end model, it takes raw PCM signals as an input, but is also compatible with linear predictive coding (LPC), showing better subjective quality at high bitrates than AMR-WB and OPUS. The gain is achieved by using only 0.9 million trainable parameters, a significantly less complex architecture than the other DNN-based codecs in the literature.