 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscrete Audio Tokens: More Than a Survey!
Jun 12, 2025Discrete audio tokens are compact representations that aim to preserve perceptual quality, phonetic content, and speaker characteristics while enabling efficient storage and inference, as well as competitive performance across diverse downstream tasks.They provide a practical alternative to continuous features, enabling the integration of speech and audio into modern large language models (LLMs). As interest in token-based audio processing grows, various tokenization methods have emerged, and several surveys have reviewed the latest progress in the field. However, existing studies often focus on specific domains or tasks and lack a unified comparison across various benchmarks. This paper presents a systematic review and benchmark of discrete audio tokenizers, covering three domains: speech, music, and general audio. We propose a taxonomy of tokenization approaches based on encoder-decoder, quantization techniques, training paradigm, streamability, and application domains. We evaluate tokenizers on multiple benchmarks for reconstruction, downstream performance, and acoustic language modeling, and analyze trade-offs through controlled ablation studies. Our findings highlight key limitations, practical considerations, and open challenges, providing insight and guidance for future research in this rapidly evolving area. For more information, including our main results and tokenizer database, please refer to our website: https://poonehmousavi.github.io/dates-website/.
Personalized Neural Speech Codec
Mar 31, 2024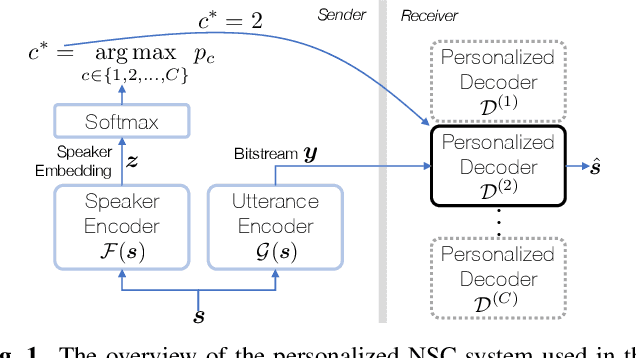



In this paper, we propose a personalized neural speech codec, envisioning that personalization can reduce the model complexity or improve perceptual speech quality. Despite the common usage of speech codecs where only a single talker is involved on each side of the communication, personalizing a codec for the specific user has rarely been explored in the literature. First, we assume speakers can be grouped into smaller subsets based on their perceptual similarity. Then, we also postulate that a group-specific codec can focus on the group's speech characteristics to improve its perceptual quality and computational efficiency. To this end, we first develop a Siamese network that learns the speaker embeddings from the LibriSpeech dataset, which are then grouped into underlying speaker clusters. Finally, we retrain the LPCNet-based speech codec baselines on each of the speaker clusters. Subjective listening tests show that the proposed personalization scheme introduces model compression while maintaining speech quality. In other words, with the same model complexity, personalized codecs produce better speech quality.
Generative De-Quantization for Neural Speech Codec via Latent Diffusion
Nov 15, 2023In low-bitrate speech coding, end-to-end speech coding networks aim to learn compact yet expressive features and a powerful decoder in a single network. A challenging problem as such results in unwelcome complexity increase and inferior speech quality. In this paper, we propose to separate the representation learning and information reconstruction tasks. We leverage an end-to-end codec for learning low-dimensional discrete tokens and employ a latent diffusion model to de-quantize coded features into a high-dimensional continuous space, relieving the decoder's burden of de-quantizing and upsampling. To mitigate the issue of over-smooth generation, we introduce midway-infilling with less noise reduction and stronger conditioning. In ablation studies, we investigate the hyperparameters for midway-infilling and latent diffusion space with different dimensions. Subjective listening tests show that our model outperforms the state-of-the-art at two low bitrates, 1.5 and 3 kbps. Codes and samples of this work are available on our webpage.
Neural Feature Predictor and Discriminative Residual Coding for Low-Bitrate Speech Coding
Nov 04, 2022Low and ultra-low-bitrate neural speech coding achieves unprecedented coding gain by generating speech signals from compact speech features. This paper introduces additional coding efficiency in neural speech coding by reducing the temporal redundancy existing in the frame-level feature sequence via a recurrent neural predictor. The prediction can achieve a low-entropy residual representation, which we discriminatively code based on their contribution to the signal reconstruction. The harmonization of feature prediction and discriminative coding results in a dynamic bit allocation algorithm that spends more bits on unpredictable but rare events. As a result, we develop a scalable, lightweight, low-latency, and low-bitrate neural speech coding system. We demonstrate the advantage of the proposed methods using the LPCNet as a neural vocoder. While the proposed method guarantees causality in its prediction, the subjective tests and feature space analysis show that our model achieves superior coding efficiency compared to LPCNet and Lyra V2 in the very low bitrates.
Upmixing via style transfer: a variational autoencoder for disentangling spatial images and musical content
Mar 22, 2022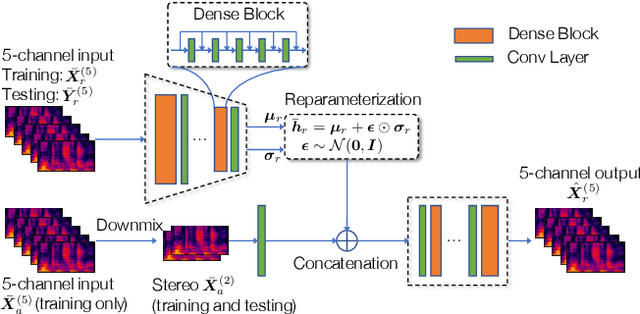

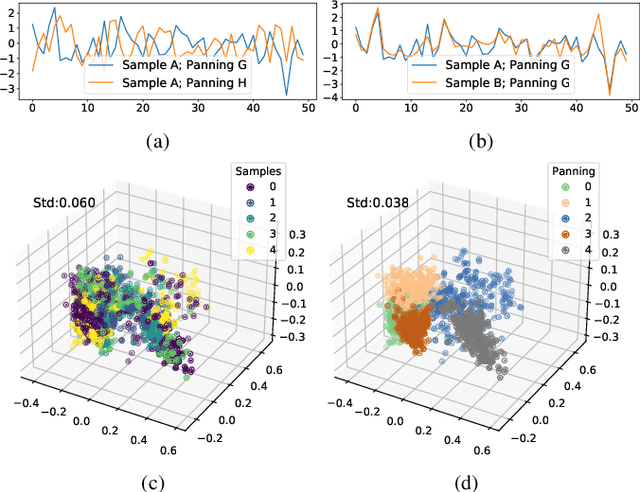
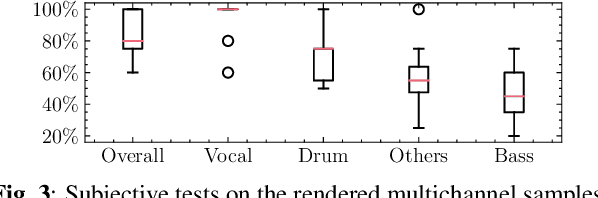
In the stereo-to-multichannel upmixing problem for music, one of the main tasks is to set the directionality of the instrument sources in the multichannel rendering results. In this paper, we propose a modified variational autoencoder model that learns a latent space to describe the spatial images in multichannel music. We seek to disentangle the spatial images and music content, so the learned latent variables are invariant to the music. At test time, we use the latent variables to control the panning of sources. We propose two upmixing use cases: transferring the spatial images from one song to another and blind panning based on the generative model. We report objective and subjective evaluation results to empirically show that our model captures spatial images separately from music content and achieves transfer-based interactive panning.
Neural Remixer: Learning to Remix Music with Interactive Control
Jul 28, 2021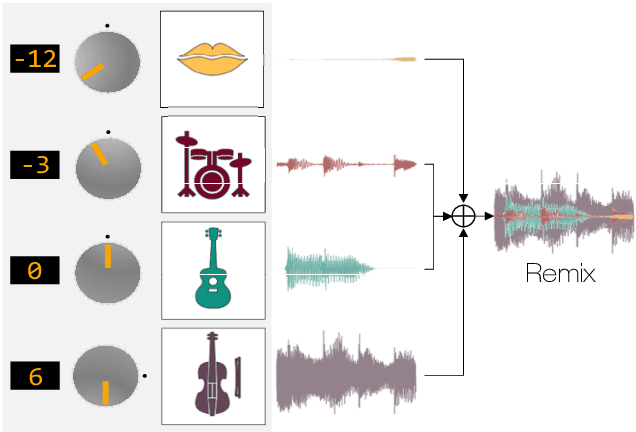
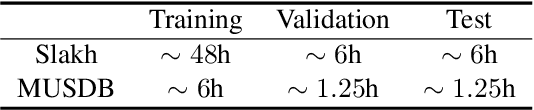
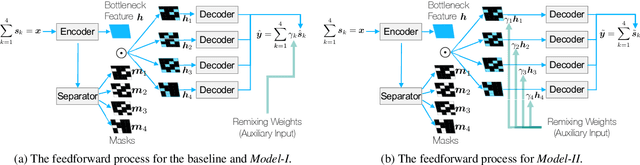
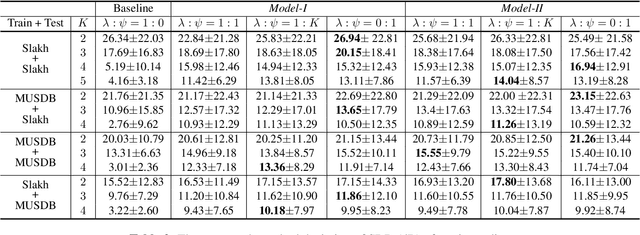
The task of manipulating the level and/or effects of individual instruments to recompose a mixture of recording, or remixing, is common across a variety of applications such as music production, audio-visual post-production, podcasts, and more. This process, however, traditionally requires access to individual source recordings, restricting the creative process. To work around this, source separation algorithms can separate a mixture into its respective components. Then, a user can adjust their levels and mix them back together. This two-step approach, however, still suffers from audible artifacts and motivates further work. In this work, we seek to learn to remix music directly. To do this, we propose two neural remixing architectures that extend Conv-TasNet to either remix via a) source estimates directly or b) their latent representations. Both methods leverage a remixing data augmentation scheme as well as a mixture reconstruction loss to achieve an end-to-end separation and remixing process. We evaluate our methods using the Slakh and MUSDB datasets and report both source separation performance and the remixing quality. Our results suggest learning-to-remix significantly outperforms a strong separation baseline, is particularly useful for small changes, and can provide interactive user-controls.
Boosted Locality Sensitive Hashing: Discriminative Binary Codes for Source Separation
Feb 14, 2020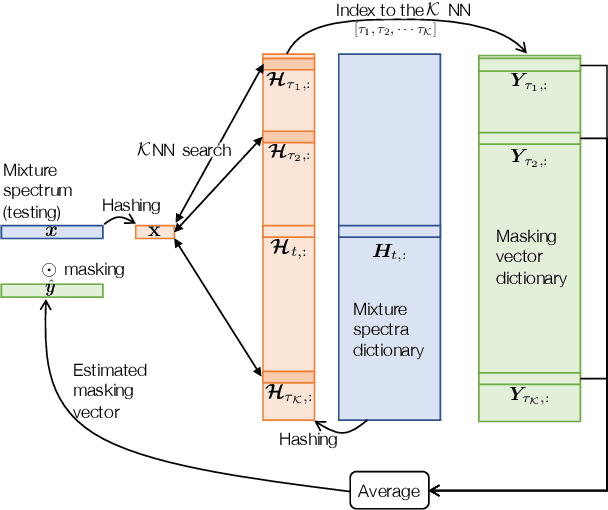
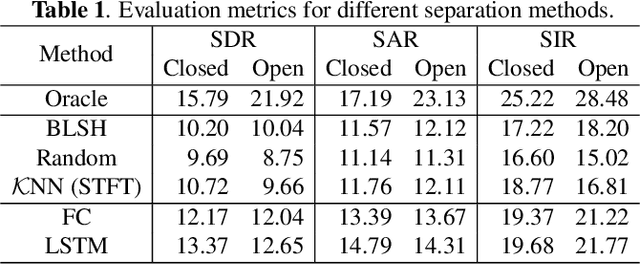

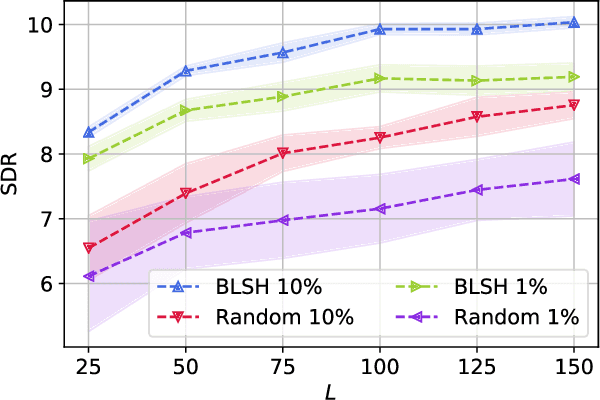
Speech enhancement tasks have seen significant improvements with the advance of deep learning technology, but with the cost of increased computational complexity. In this study, we propose an adaptive boosting approach to learning locality sensitive hash codes, which represent audio spectra efficiently. We use the learned hash codes for single-channel speech denoising tasks as an alternative to a complex machine learning model, particularly to address the resource-constrained environments. Our adaptive boosting algorithm learns simple logistic regressors as the weak learners. Once trained, their binary classification results transform each spectrum of test noisy speech into a bit string. Simple bitwise operations calculate Hamming distance to find the K-nearest matching frames in the dictionary of training noisy speech spectra, whose associated ideal binary masks are averaged to estimate the denoising mask for that test mixture. Our proposed learning algorithm differs from AdaBoost in the sense that the projections are trained to minimize the distances between the self-similarity matrix of the hash codes and that of the original spectra, rather than the misclassification rate. We evaluate our discriminative hash codes on the TIMIT corpus with various noise types, and show comparative performance to deep learning methods in terms of denoising performance and complexity.