 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalized Neural Speech Codec
Mar 31, 2024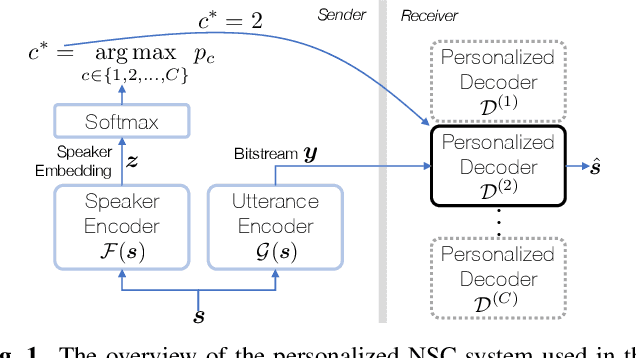



In this paper, we propose a personalized neural speech codec, envisioning that personalization can reduce the model complexity or improve perceptual speech quality. Despite the common usage of speech codecs where only a single talker is involved on each side of the communication, personalizing a codec for the specific user has rarely been explored in the literature. First, we assume speakers can be grouped into smaller subsets based on their perceptual similarity. Then, we also postulate that a group-specific codec can focus on the group's speech characteristics to improve its perceptual quality and computational efficiency. To this end, we first develop a Siamese network that learns the speaker embeddings from the LibriSpeech dataset, which are then grouped into underlying speaker clusters. Finally, we retrain the LPCNet-based speech codec baselines on each of the speaker clusters. Subjective listening tests show that the proposed personalization scheme introduces model compression while maintaining speech quality. In other words, with the same model complexity, personalized codecs produce better speech quality.
Conditional variational autoencoder to improve neural audio synthesis for polyphonic music sound
Nov 16, 2022Deep generative models for audio synthesis have recently been significantly improved. However, the task of modeling raw-waveforms remains a difficult problem, especially for audio waveforms and music signals. Recently, the realtime audio variational autoencoder (RAVE) method was developed for high-quality audio waveform synthesis. The RAVE method is based on the variational autoencoder and utilizes the two-stage training strategy. Unfortunately, the RAVE model is limited in reproducing wide-pitch polyphonic music sound. Therefore, to enhance the reconstruction performance, we adopt the pitch activation data as an auxiliary information to the RAVE model. To handle the auxiliary information, we propose an enhanced RAVE model with a conditional variational autoencoder structure and an additional fully-connected layer. To evaluate the proposed structure, we conducted a listening experiment based on multiple stimulus tests with hidden references and an anchor (MUSHRA) with the MAESTRO. The obtained results indicate that the proposed model exhibits a more significant performance and stability improvement than the conventional RAVE model.
Neural Feature Predictor and Discriminative Residual Coding for Low-Bitrate Speech Coding
Nov 04, 2022Low and ultra-low-bitrate neural speech coding achieves unprecedented coding gain by generating speech signals from compact speech features. This paper introduces additional coding efficiency in neural speech coding by reducing the temporal redundancy existing in the frame-level feature sequence via a recurrent neural predictor. The prediction can achieve a low-entropy residual representation, which we discriminatively code based on their contribution to the signal reconstruction. The harmonization of feature prediction and discriminative coding results in a dynamic bit allocation algorithm that spends more bits on unpredictable but rare events. As a result, we develop a scalable, lightweight, low-latency, and low-bitrate neural speech coding system. We demonstrate the advantage of the proposed methods using the LPCNet as a neural vocoder. While the proposed method guarantees causality in its prediction, the subjective tests and feature space analysis show that our model achieves superior coding efficiency compared to LPCNet and Lyra V2 in the very low bitrates.