 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Spectral Band Generation for Audio Coding
Jun 07, 2025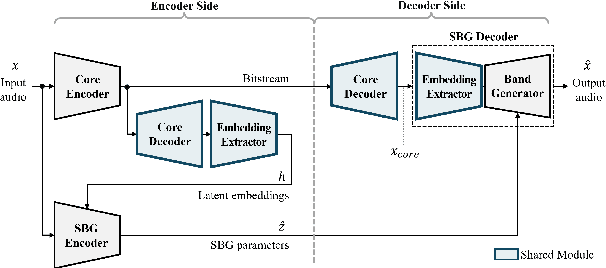
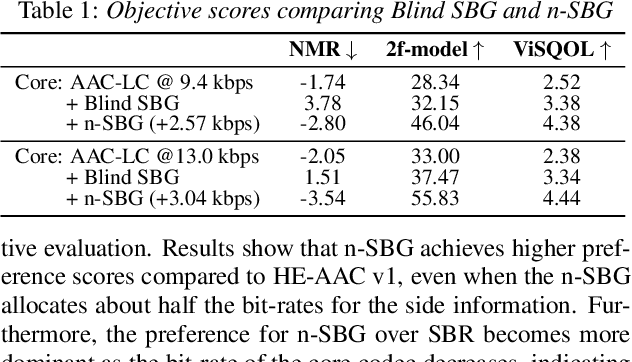
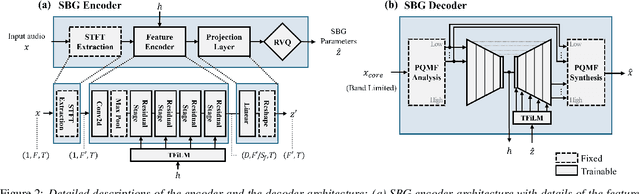
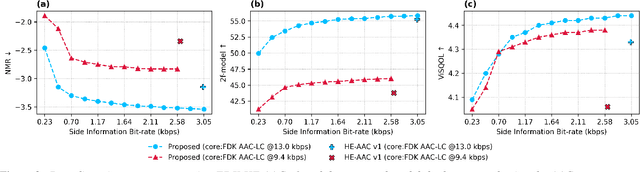
Audio bandwidth extension is the task of reconstructing missing high frequency components of bandwidth-limited audio signals, where bandwidth limitation is a common issue for audio signals due to several reasons, including channel capacity and data constraints. While conventional spectral band replication is a well-established parametric approach to audio bandwidth extension, the SBR usually entails coarse feature extraction and reconstruction techniques, which leads to limitations when processing various types of audio signals. In parallel, numerous deep neural network-based audio bandwidth extension methods have been proposed. These DNN-based methods are usually referred to as blind BWE, as these methods do not rely on prior information extracted from original signals, and only utilize given low frequency band signals to estimate missing high frequency components. In order to replace conventional SBR with DNNs, simply adopting existing DNN-based methodologies results in suboptimal performance due to the blindness of these methods. My proposed research suggests a new approach to parametric non-blind bandwidth extension, as DNN-based side information extraction and DNN-based bandwidth extension are performed only at the front and end of the audio coding pipeline.
Personalized Neural Speech Codec
Mar 31, 2024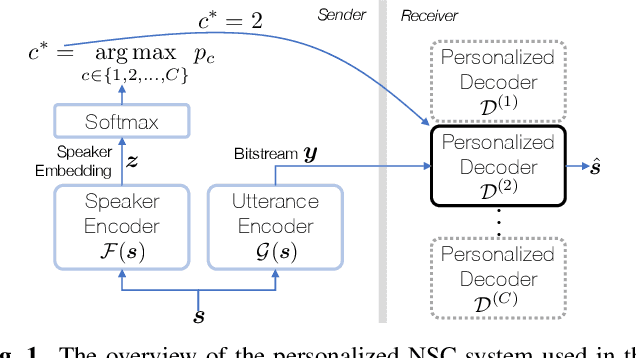



In this paper, we propose a personalized neural speech codec, envisioning that personalization can reduce the model complexity or improve perceptual speech quality. Despite the common usage of speech codecs where only a single talker is involved on each side of the communication, personalizing a codec for the specific user has rarely been explored in the literature. First, we assume speakers can be grouped into smaller subsets based on their perceptual similarity. Then, we also postulate that a group-specific codec can focus on the group's speech characteristics to improve its perceptual quality and computational efficiency. To this end, we first develop a Siamese network that learns the speaker embeddings from the LibriSpeech dataset, which are then grouped into underlying speaker clusters. Finally, we retrain the LPCNet-based speech codec baselines on each of the speaker clusters. Subjective listening tests show that the proposed personalization scheme introduces model compression while maintaining speech quality. In other words, with the same model complexity, personalized codecs produce better speech quality.
Generative De-Quantization for Neural Speech Codec via Latent Diffusion
Nov 15, 2023In low-bitrate speech coding, end-to-end speech coding networks aim to learn compact yet expressive features and a powerful decoder in a single network. A challenging problem as such results in unwelcome complexity increase and inferior speech quality. In this paper, we propose to separate the representation learning and information reconstruction tasks. We leverage an end-to-end codec for learning low-dimensional discrete tokens and employ a latent diffusion model to de-quantize coded features into a high-dimensional continuous space, relieving the decoder's burden of de-quantizing and upsampling. To mitigate the issue of over-smooth generation, we introduce midway-infilling with less noise reduction and stronger conditioning. In ablation studies, we investigate the hyperparameters for midway-infilling and latent diffusion space with different dimensions. Subjective listening tests show that our model outperforms the state-of-the-art at two low bitrates, 1.5 and 3 kbps. Codes and samples of this work are available on our webpage.
Native Multi-Band Audio Coding within Hyper-Autoencoded Reconstruction Propagation Networks
Mar 14, 2023Spectral sub-bands do not portray the same perceptual relevance. In audio coding, it is therefore desirable to have independent control over each of the constituent bands so that bitrate assignment and signal reconstruction can be achieved efficiently. In this work, we present a novel neural audio coding network that natively supports a multi-band coding paradigm. Our model extends the idea of compressed skip connections in the U-Net-based codec, allowing for independent control over both core and high band-specific reconstructions and bit allocation. Our system reconstructs the full-band signal mainly from the condensed core-band code, therefore exploiting and showcasing its bandwidth extension capabilities to its fullest. Meanwhile, the low-bitrate high-band code helps the high-band reconstruction similarly to MPEG audio codecs' spectral bandwidth replication. MUSHRA tests show that the proposed model not only improves the quality of the core band by explicitly assigning more bits to it but retains a good quality in the high-band as well.
Conditional variational autoencoder to improve neural audio synthesis for polyphonic music sound
Nov 16, 2022Deep generative models for audio synthesis have recently been significantly improved. However, the task of modeling raw-waveforms remains a difficult problem, especially for audio waveforms and music signals. Recently, the realtime audio variational autoencoder (RAVE) method was developed for high-quality audio waveform synthesis. The RAVE method is based on the variational autoencoder and utilizes the two-stage training strategy. Unfortunately, the RAVE model is limited in reproducing wide-pitch polyphonic music sound. Therefore, to enhance the reconstruction performance, we adopt the pitch activation data as an auxiliary information to the RAVE model. To handle the auxiliary information, we propose an enhanced RAVE model with a conditional variational autoencoder structure and an additional fully-connected layer. To evaluate the proposed structure, we conducted a listening experiment based on multiple stimulus tests with hidden references and an anchor (MUSHRA) with the MAESTRO. The obtained results indicate that the proposed model exhibits a more significant performance and stability improvement than the conventional RAVE model.
Deep Neural Networks and End-to-End Learning for Audio Compression
May 25, 2021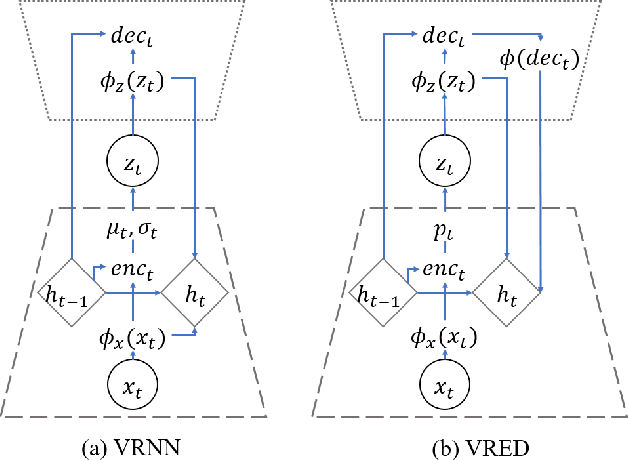
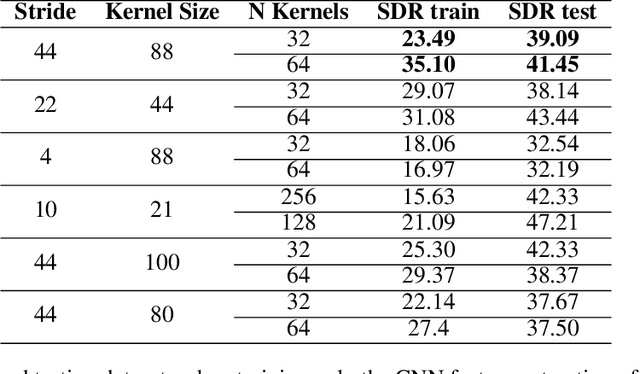
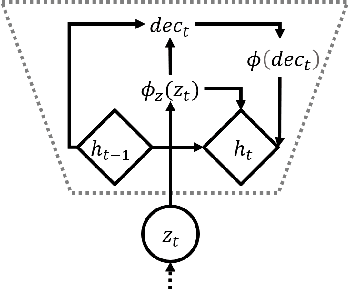
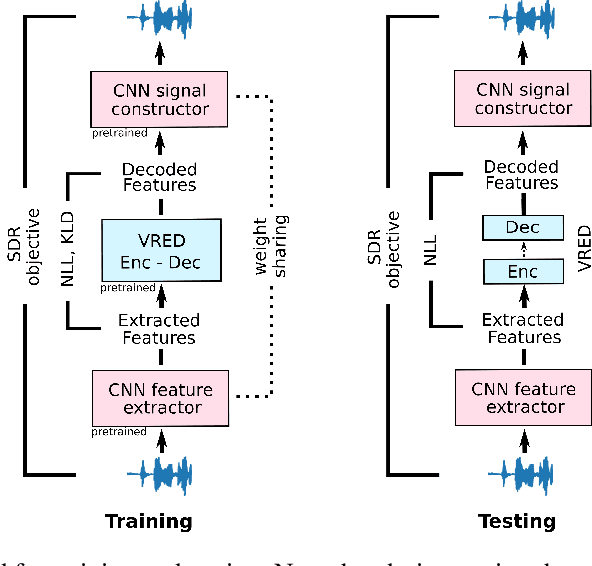
Recent achievements in end-to-end deep learning have encouraged the exploration of tasks dealing with highly structured data with unified deep network models. Having such models for compressing audio signals has been challenging since it requires discrete representations that are not easy to train with end-to-end backpropagation. In this paper, we present an end-to-end deep learning approach that combines recurrent neural networks (RNNs) within the training strategy of variational autoencoders (VAEs) with a binary representation of the latent space. We apply a reparametrization trick for the Bernoulli distribution for the discrete representations, which allows smooth backpropagation. In addition, our approach allows the separation of the encoder and decoder, which is necessary for compression tasks. To our best knowledge, this is the first end-to-end learning for a single audio compression model with RNNs, and our model achieves a Signal to Distortion Ratio (SDR) of 20.54.