 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Neural Networks and End-to-End Learning for Audio Compression
Paper and Code
May 25, 2021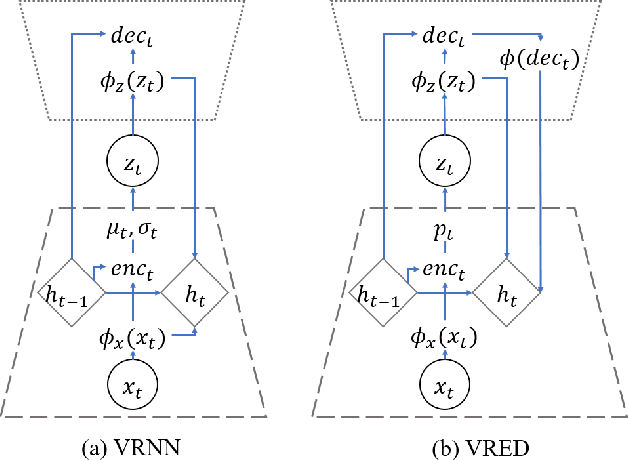
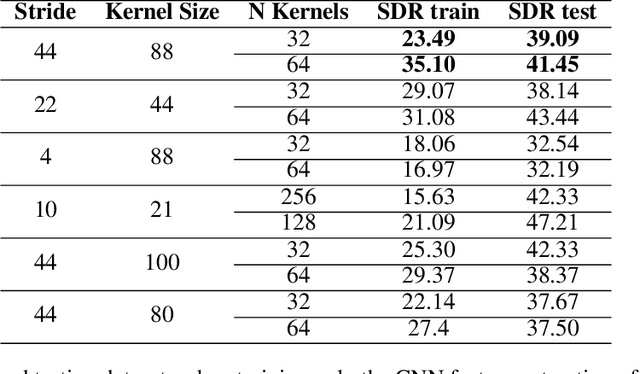
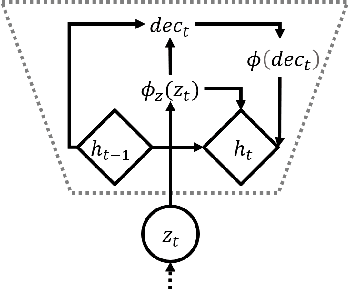
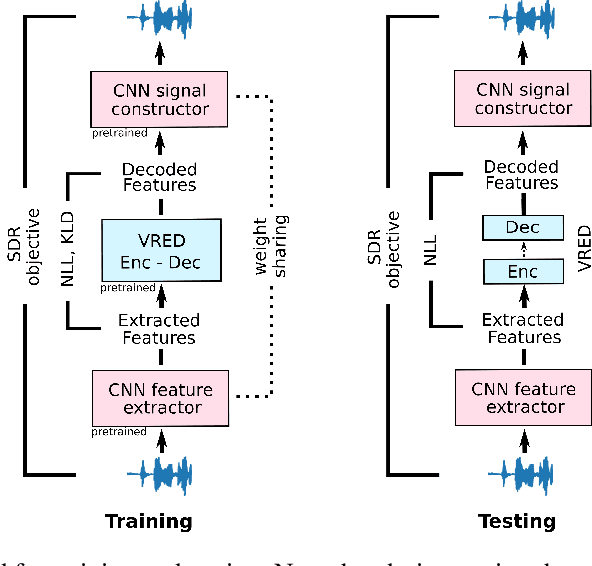
Recent achievements in end-to-end deep learning have encouraged the exploration of tasks dealing with highly structured data with unified deep network models. Having such models for compressing audio signals has been challenging since it requires discrete representations that are not easy to train with end-to-end backpropagation. In this paper, we present an end-to-end deep learning approach that combines recurrent neural networks (RNNs) within the training strategy of variational autoencoders (VAEs) with a binary representation of the latent space. We apply a reparametrization trick for the Bernoulli distribution for the discrete representations, which allows smooth backpropagation. In addition, our approach allows the separation of the encoder and decoder, which is necessary for compression tasks. To our best knowledge, this is the first end-to-end learning for a single audio compression model with RNNs, and our model achieves a Signal to Distortion Ratio (SDR) of 20.54.