 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSentence Curve Language Models
Feb 03, 2026Language models (LMs) are a central component of modern AI systems, and diffusion-based language models (DLMs) have recently emerged as a competitive alternative. Both paradigms rely on word embeddings not only to represent the input sentence, but also to represent the target sentence that backbone models are trained to predict. We argue that such static embedding of the target word is insensitive to neighboring words, encouraging locally accurate word prediction while neglecting global structure across the target sentence. To address this limitation, we propose a continuous sentence representation, termed sentence curve, defined as a spline curve whose control points affect multiple words in the sentence. Based on this representation, we introduce sentence curve language model (SCLM), which extends DLMs to predict sentence curves instead of the static word embeddings. We theoretically show that sentence curve prediction induces a regularization effect that promotes global structure modeling, and characterize how different sentence curve types affect this behavior. Empirically, SCLM achieves SOTA performance among DLMs on IWSLT14 and WMT14, shows stable training without burdensome knowledge distillation, and demonstrates promising potential compared to discrete DLMs on LM1B.
Convolutional Lie Operator for Sentence Classification
Dec 18, 2025Traditional Convolutional Neural Networks have been successful in capturing local, position-invariant features in text, but their capacity to model complex transformation within language can be further explored. In this work, we explore a novel approach by integrating Lie Convolutions into Convolutional-based sentence classifiers, inspired by the ability of Lie group operations to capture complex, non-Euclidean symmetries. Our proposed models SCLie and DPCLie empirically outperform traditional Convolutional-based sentence classifiers, suggesting that Lie-based models relatively improve the accuracy by capturing transformations not commonly associated with language. Our findings motivate more exploration of new paradigms in language modeling.
Dynamic Preference Multi-Objective Reinforcement Learning for Internet Network Management
Jun 16, 2025An internet network service provider manages its network with multiple objectives, such as high quality of service (QoS) and minimum computing resource usage. To achieve these objectives, a reinforcement learning-based (RL) algorithm has been proposed to train its network management agent. Usually, their algorithms optimize their agents with respect to a single static reward formulation consisting of multiple objectives with fixed importance factors, which we call preferences. However, in practice, the preference could vary according to network status, external concerns and so on. For example, when a server shuts down and it can cause other servers' traffic overloads leading to additional shutdowns, it is plausible to reduce the preference of QoS while increasing the preference of minimum computing resource usages. In this paper, we propose new RL-based network management agents that can select actions based on both states and preferences. With our proposed approach, we expect a single agent to generalize on various states and preferences. Furthermore, we propose a numerical method that can estimate the distribution of preference that is advantageous for unbiased training. Our experiment results show that the RL agents trained based on our proposed approach significantly generalize better with various preferences than the previous RL approaches, which assume static preference during training. Moreover, we demonstrate several analyses that show the advantages of our numerical estimation method.
Harnessing EHRs for Diffusion-based Anomaly Detection on Chest X-rays
May 22, 2025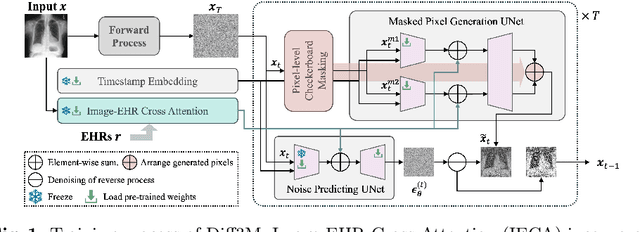
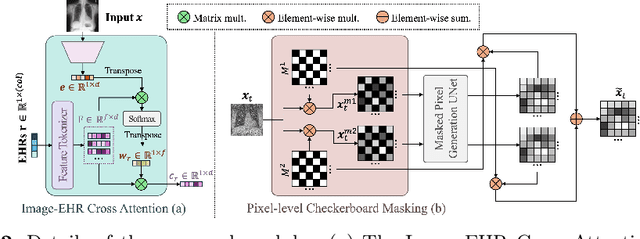
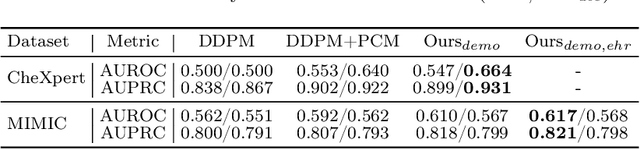
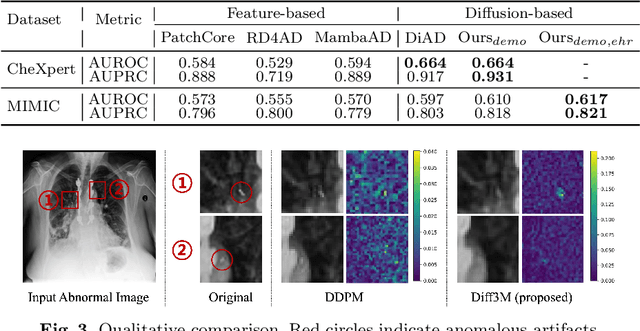
Unsupervised anomaly detection (UAD) in medical imaging is crucial for identifying pathological abnormalities without requiring extensive labeled data. However, existing diffusion-based UAD models rely solely on imaging features, limiting their ability to distinguish between normal anatomical variations and pathological anomalies. To address this, we propose Diff3M, a multi-modal diffusion-based framework that integrates chest X-rays and structured Electronic Health Records (EHRs) for enhanced anomaly detection. Specifically, we introduce a novel image-EHR cross-attention module to incorporate structured clinical context into the image generation process, improving the model's ability to differentiate normal from abnormal features. Additionally, we develop a static masking strategy to enhance the reconstruction of normal-like images from anomalies. Extensive evaluations on CheXpert and MIMIC-CXR/IV demonstrate that Diff3M achieves state-of-the-art performance, outperforming existing UAD methods in medical imaging. Our code is available at this http URL https://github.com/nth221/Diff3M
Data Augmentation With Back translation for Low Resource languages: A case of English and Luganda
May 05, 2025



In this paper,we explore the application of Back translation (BT) as a semi-supervised technique to enhance Neural Machine Translation(NMT) models for the English-Luganda language pair, specifically addressing the challenges faced by low-resource languages. The purpose of our study is to demonstrate how BT can mitigate the scarcity of bilingual data by generating synthetic data from monolingual corpora. Our methodology involves developing custom NMT models using both publicly available and web-crawled data, and applying Iterative and Incremental Back translation techniques. We strategically select datasets for incremental back translation across multiple small datasets, which is a novel element of our approach. The results of our study show significant improvements, with translation performance for the English-Luganda pair exceeding previous benchmarks by more than 10 BLEU score units across all translation directions. Additionally, our evaluation incorporates comprehensive assessment metrics such as SacreBLEU, ChrF2, and TER, providing a nuanced understanding of translation quality. The conclusion drawn from our research confirms the efficacy of BT when strategically curated datasets are utilized, establishing new performance benchmarks and demonstrating the potential of BT in enhancing NMT models for low-resource languages.
* NLPIR '24: Proceedings of the 2024 8th International Conference on Natural Language Processing and Information Retrieval
Generalized Probabilistic Attention Mechanism in Transformers
Oct 21, 2024

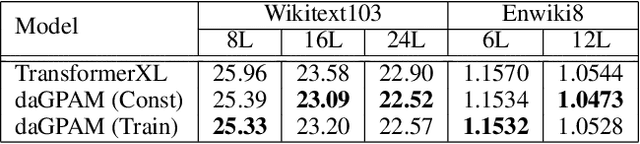

The Transformer architecture has become widely adopted due to its demonstrated success, attributed to the attention mechanism at its core. Despite these successes, the attention mechanism of Transformers is associated with two well-known issues: rank-collapse and gradient vanishing. In this paper, we present a theoretical analysis that it is inherently difficult to address both issues simultaneously in the conventional attention mechanism. To handle these issues, we introduce a novel class of attention mechanism, referred to as generalized probabilistic attention mechanism (GPAM), and its dual-attention implementation within the Transformer architecture. Unlike conventional attention mechanisms, GPAM allows for negative attention scores while preserving a fixed total sum. We provide theoretical evidence that the proposed dual-attention GPAM (daGPAM) effectively mitigates both the rank-collapse and gradient vanishing issues which are difficult to resolve simultaneously with the conventional attention mechanisms. Furthermore, we empirically validate this theoretical evidence, demonstrating the superiority of daGPAM compared to other alternative attention mechanisms that were proposed to address the same issues. Additionally, we demonstrate the practical benefits of GPAM in natural language processing tasks, such as language modeling and neural machine translation.
N-gram Prediction and Word Difference Representations for Language Modeling
Sep 05, 2024



Causal language modeling (CLM) serves as the foundational framework underpinning remarkable successes of recent large language models (LLMs). Despite its success, the training approach for next word prediction poses a potential risk of causing the model to overly focus on local dependencies within a sentence. While prior studies have been introduced to predict future N words simultaneously, they were primarily applied to tasks such as masked language modeling (MLM) and neural machine translation (NMT). In this study, we introduce a simple N-gram prediction framework for the CLM task. Moreover, we introduce word difference representation (WDR) as a surrogate and contextualized target representation during model training on the basis of N-gram prediction framework. To further enhance the quality of next word prediction, we propose an ensemble method that incorporates the future N words' prediction results. Empirical evaluations across multiple benchmark datasets encompassing CLM and NMT tasks demonstrate the significant advantages of our proposed methods over the conventional CLM.
Empirical Study of Symmetrical Reasoning in Conversational Chatbots
Jul 08, 2024This work explores the capability of conversational chatbots powered by large language models (LLMs), to understand and characterize predicate symmetry, a cognitive linguistic function traditionally believed to be an inherent human trait. Leveraging in-context learning (ICL), a paradigm shift enabling chatbots to learn new tasks from prompts without re-training, we assess the symmetrical reasoning of five chatbots: ChatGPT 4, Huggingface chat AI, Microsoft's Copilot AI, LLaMA through Perplexity, and Gemini Advanced. Using the Symmetry Inference Sentence (SIS) dataset by Tanchip et al. (2020), we compare chatbot responses against human evaluations to gauge their understanding of predicate symmetry. Experiment results reveal varied performance among chatbots, with some approaching human-like reasoning capabilities. Gemini, for example, reaches a correlation of 0.85 with human scores, while providing a sounding justification for each symmetry evaluation. This study underscores the potential and limitations of LLMs in mirroring complex cognitive processes as symmetrical reasoning.
Multimodal Representation Loss Between Timed Text and Audio for Regularized Speech Separation
Jun 12, 2024Recent studies highlight the potential of textual modalities in conditioning the speech separation model's inference process. However, regularization-based methods remain underexplored despite their advantages of not requiring auxiliary text data during the test time. To address this gap, we introduce a timed text-based regularization (TTR) method that uses language model-derived semantics to improve speech separation models. Our approach involves two steps. We begin with two pretrained audio and language models, WavLM and BERT, respectively. Then, a Transformer-based audio summarizer is learned to align the audio and word embeddings and to minimize their gap. The summarizer Transformer, incorporated as a regularizer, promotes the separated sources' alignment with the semantics from the timed text. Experimental results show that the proposed TTR method consistently improves the various objective metrics of the separation results over the unregularized baselines.
Advancing AI with Integrity: Ethical Challenges and Solutions in Neural Machine Translation
Apr 01, 2024This paper addresses the ethical challenges of Artificial Intelligence in Neural Machine Translation (NMT) systems, emphasizing the imperative for developers to ensure fairness and cultural sensitivity. We investigate the ethical competence of AI models in NMT, examining the Ethical considerations at each stage of NMT development, including data handling, privacy, data ownership, and consent. We identify and address ethical issues through empirical studies. These include employing Transformer models for Luganda-English translations and enhancing efficiency with sentence mini-batching. And complementary studies that refine data labeling techniques and fine-tune BERT and Longformer models for analyzing Luganda and English social media content. Our second approach is a literature review from databases such as Google Scholar and platforms like GitHub. Additionally, the paper probes the distribution of responsibility between AI systems and humans, underscoring the essential role of human oversight in upholding NMT ethical standards. Incorporating a biblical perspective, we discuss the societal impact of NMT and the broader ethical responsibilities of developers, positing them as stewards accountable for the societal repercussions of their creations.