 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSentence Curve Language Models
Feb 03, 2026Language models (LMs) are a central component of modern AI systems, and diffusion-based language models (DLMs) have recently emerged as a competitive alternative. Both paradigms rely on word embeddings not only to represent the input sentence, but also to represent the target sentence that backbone models are trained to predict. We argue that such static embedding of the target word is insensitive to neighboring words, encouraging locally accurate word prediction while neglecting global structure across the target sentence. To address this limitation, we propose a continuous sentence representation, termed sentence curve, defined as a spline curve whose control points affect multiple words in the sentence. Based on this representation, we introduce sentence curve language model (SCLM), which extends DLMs to predict sentence curves instead of the static word embeddings. We theoretically show that sentence curve prediction induces a regularization effect that promotes global structure modeling, and characterize how different sentence curve types affect this behavior. Empirically, SCLM achieves SOTA performance among DLMs on IWSLT14 and WMT14, shows stable training without burdensome knowledge distillation, and demonstrates promising potential compared to discrete DLMs on LM1B.
Dynamic Preference Multi-Objective Reinforcement Learning for Internet Network Management
Jun 16, 2025An internet network service provider manages its network with multiple objectives, such as high quality of service (QoS) and minimum computing resource usage. To achieve these objectives, a reinforcement learning-based (RL) algorithm has been proposed to train its network management agent. Usually, their algorithms optimize their agents with respect to a single static reward formulation consisting of multiple objectives with fixed importance factors, which we call preferences. However, in practice, the preference could vary according to network status, external concerns and so on. For example, when a server shuts down and it can cause other servers' traffic overloads leading to additional shutdowns, it is plausible to reduce the preference of QoS while increasing the preference of minimum computing resource usages. In this paper, we propose new RL-based network management agents that can select actions based on both states and preferences. With our proposed approach, we expect a single agent to generalize on various states and preferences. Furthermore, we propose a numerical method that can estimate the distribution of preference that is advantageous for unbiased training. Our experiment results show that the RL agents trained based on our proposed approach significantly generalize better with various preferences than the previous RL approaches, which assume static preference during training. Moreover, we demonstrate several analyses that show the advantages of our numerical estimation method.
Generalized Probabilistic Attention Mechanism in Transformers
Oct 21, 2024

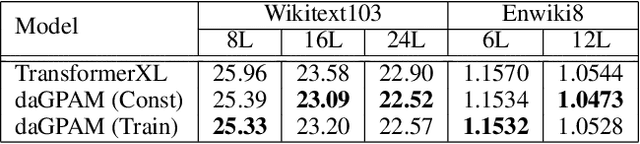

The Transformer architecture has become widely adopted due to its demonstrated success, attributed to the attention mechanism at its core. Despite these successes, the attention mechanism of Transformers is associated with two well-known issues: rank-collapse and gradient vanishing. In this paper, we present a theoretical analysis that it is inherently difficult to address both issues simultaneously in the conventional attention mechanism. To handle these issues, we introduce a novel class of attention mechanism, referred to as generalized probabilistic attention mechanism (GPAM), and its dual-attention implementation within the Transformer architecture. Unlike conventional attention mechanisms, GPAM allows for negative attention scores while preserving a fixed total sum. We provide theoretical evidence that the proposed dual-attention GPAM (daGPAM) effectively mitigates both the rank-collapse and gradient vanishing issues which are difficult to resolve simultaneously with the conventional attention mechanisms. Furthermore, we empirically validate this theoretical evidence, demonstrating the superiority of daGPAM compared to other alternative attention mechanisms that were proposed to address the same issues. Additionally, we demonstrate the practical benefits of GPAM in natural language processing tasks, such as language modeling and neural machine translation.
N-gram Prediction and Word Difference Representations for Language Modeling
Sep 05, 2024



Causal language modeling (CLM) serves as the foundational framework underpinning remarkable successes of recent large language models (LLMs). Despite its success, the training approach for next word prediction poses a potential risk of causing the model to overly focus on local dependencies within a sentence. While prior studies have been introduced to predict future N words simultaneously, they were primarily applied to tasks such as masked language modeling (MLM) and neural machine translation (NMT). In this study, we introduce a simple N-gram prediction framework for the CLM task. Moreover, we introduce word difference representation (WDR) as a surrogate and contextualized target representation during model training on the basis of N-gram prediction framework. To further enhance the quality of next word prediction, we propose an ensemble method that incorporates the future N words' prediction results. Empirical evaluations across multiple benchmark datasets encompassing CLM and NMT tasks demonstrate the significant advantages of our proposed methods over the conventional CLM.
Shared Latent Space by Both Languages in Non-Autoregressive Neural Machine Translation
May 02, 2023Latent variable modeling in non-autoregressive neural machine translation (NAT) is a promising approach to mitigate the multimodality problem. In the previous works, they added an auxiliary model to estimate the posterior distribution of the latent variable conditioned on the source and target sentences. However, it causes several disadvantages, such as redundant information extraction in the latent variable, increasing parameters, and a tendency to ignore a part of the information from the inputs. In this paper, we propose a new latent variable modeling that is based on a dual reconstruction perspective and an advanced hierarchical latent modeling approach. Our proposed method, {\em LadderNMT}, shares a latent space across both languages so that it hypothetically alleviates or solves the above disadvantages. Experimental results quantitatively and qualitatively demonstrate that our proposed latent variable modeling learns an advantageous latent space and significantly improves translation quality in WMT translation tasks.
Advanced Scaling Methods for VNF deployment with Reinforcement Learning
Jan 19, 2023



Network function virtualization (NFV) and software-defined network (SDN) have become emerging network paradigms, allowing virtualized network function (VNF) deployment at a low cost. Even though VNF deployment can be flexible, it is still challenging to optimize VNF deployment due to its high complexity. Several studies have approached the task as dynamic programming, e.g., integer linear programming (ILP). However, optimizing VNF deployment for highly complex networks remains a challenge. Alternatively, reinforcement learning (RL) based approaches have been proposed to optimize this task, especially to employ a scaling action-based method which can deploy VNFs within less computational time. However, the model architecture can be improved further to generalize to the different networking settings. In this paper, we propose an enhanced model which can be adapted to more general network settings. We adopt the improved GNN architecture and a few techniques to obtain a better node representation for the VNF deployment task. Furthermore, we apply a recently proposed RL method, phasic policy gradient (PPG), to leverage the shared representation of the service function chain (SFC) generation model from the value function. We evaluate the proposed method in various scenarios, achieving a better QoS with minimum resource utilization compared to the previous methods. Finally, as a qualitative evaluation, we analyze our proposed encoder's representation for the nodes, which shows a more disentangled representation.
End-to-End Training of Both Translation Models in the Back-Translation Framework
Feb 17, 2022



Semi-supervised learning algorithms in neural machine translation (NMT) have significantly improved translation quality compared to the supervised learning algorithms by using additional monolingual corpora. Among them, back-translation is a theoretically well-structured and cutting-edge method. Given two pre-trained NMT models between source and target languages, one translates a monolingual sentence as a latent sentence, and the other reconstructs the monolingual input sentence given the latent sentence. Therefore, previous works tried to apply the variational auto-encoder's (VAE) training framework to the back-translation framework. However, the discrete property of the latent sentence made it impossible to use backpropagation in the framework. This paper proposes a categorical reparameterization trick that generates a differentiable sentence, with which we practically implement the VAE's training framework for the back-translation and train it by end-to-end backpropagation. In addition, we propose several regularization techniques that are especially advantageous to this framework. In our experiments, we demonstrate that our method makes backpropagation available through the latent sentences and improves the BLEU scores on the datasets of the WMT18 translation task.
Sequential Deep Learning Architectures for Anomaly Detection in Virtual Network Function Chains
Sep 29, 2021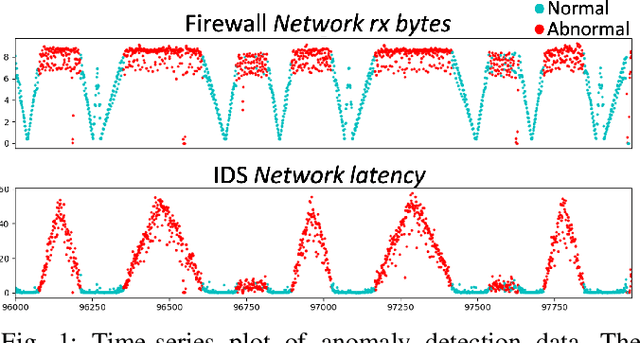
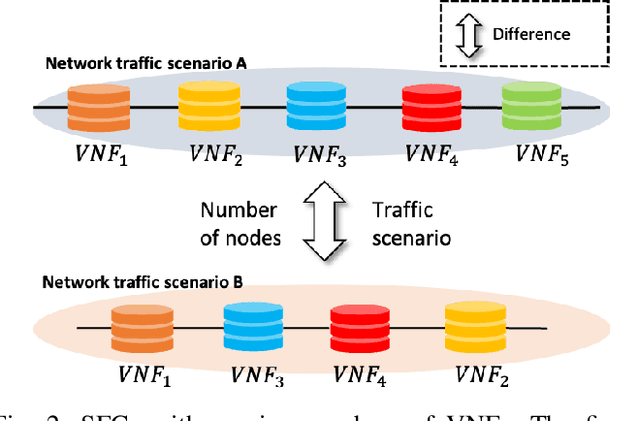
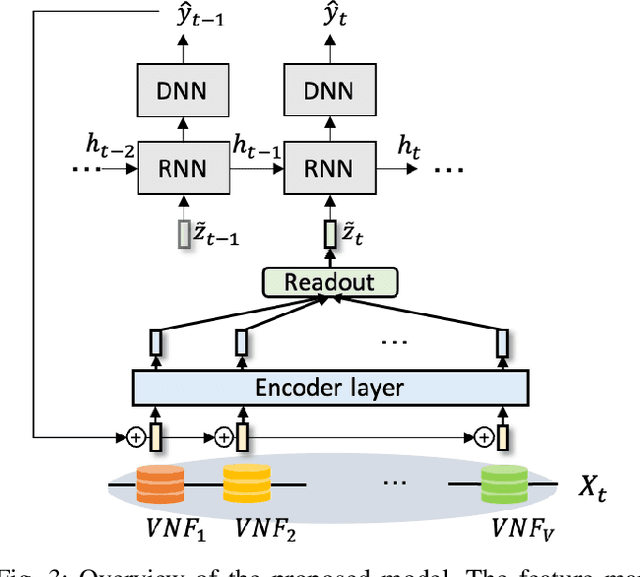
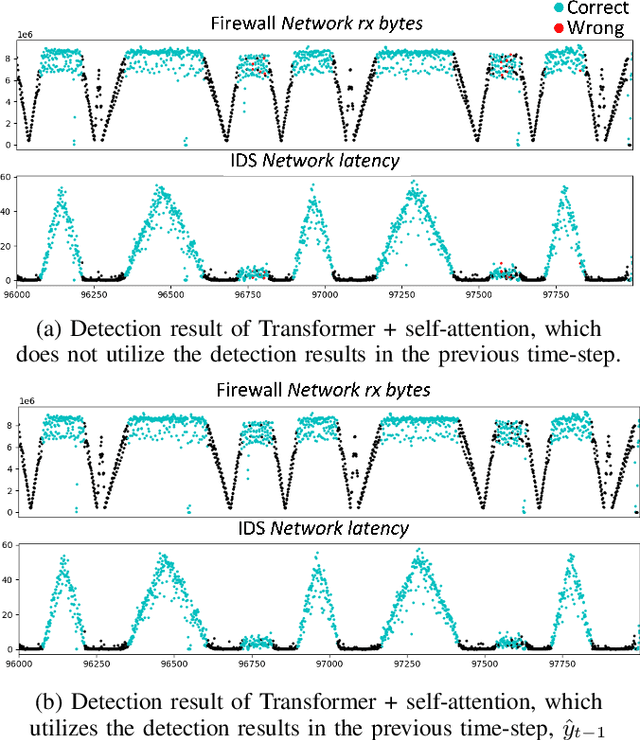
Software-defined networking (SDN) and network function virtualization (NFV) have enabled the efficient provision of network service. However, they also raised new tasks to monitor and ensure the status of virtualized service, and anomaly detection is one of such tasks. There have been many data-driven approaches to implement anomaly detection system (ADS) for virtual network functions in service function chains (SFCs). In this paper, we aim to develop more advanced deep learning models for ADS. Previous approaches used learning algorithms such as random forest (RF), gradient boosting machine (GBM), or deep neural networks (DNNs). However, these models have not utilized sequential dependencies in the data. Furthermore, they are limited as they can only apply to the SFC setting from which they were trained. Therefore, we propose several sequential deep learning models to learn time-series patterns and sequential patterns of the virtual network functions (VNFs) in the chain with variable lengths. As a result, the suggested models improve detection performance and apply to SFCs with varying numbers of VNFs.
Adversarial Training with Contrastive Learning in NLP
Sep 19, 2021



For years, adversarial training has been extensively studied in natural language processing (NLP) settings. The main goal is to make models robust so that similar inputs derive in semantically similar outcomes, which is not a trivial problem since there is no objective measure of semantic similarity in language. Previous works use an external pre-trained NLP model to tackle this challenge, introducing an extra training stage with huge memory consumption during training. However, the recent popular approach of contrastive learning in language processing hints a convenient way of obtaining such similarity restrictions. The main advantage of the contrastive learning approach is that it aims for similar data points to be mapped close to each other and further from different ones in the representation space. In this work, we propose adversarial training with contrastive learning (ATCL) to adversarially train a language processing task using the benefits of contrastive learning. The core idea is to make linear perturbations in the embedding space of the input via fast gradient methods (FGM) and train the model to keep the original and perturbed representations close via contrastive learning. In NLP experiments, we applied ATCL to language modeling and neural machine translation tasks. The results show not only an improvement in the quantitative (perplexity and BLEU) scores when compared to the baselines, but ATCL also achieves good qualitative results in the semantic level for both tasks without using a pre-trained model.
Reinforcement Learning of Graph Neural Networks for Service Function Chaining
Nov 17, 2020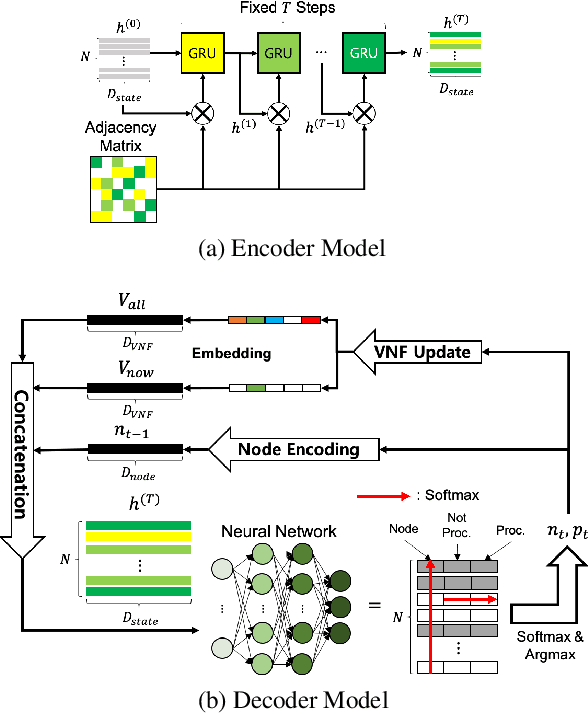
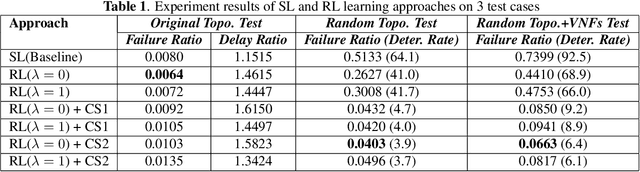
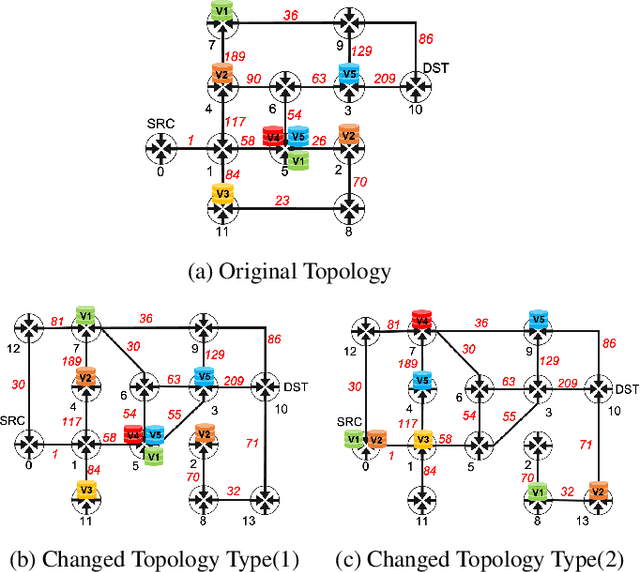
In the management of computer network systems, the service function chaining (SFC) modules play an important role by generating efficient paths for network traffic through physical servers with virtualized network functions (VNF). To provide the highest quality of services, the SFC module should generate a valid path quickly even in various network topology situations including dynamic VNF resources, various requests, and changes of topologies. The previous supervised learning method demonstrated that the network features can be represented by graph neural networks (GNNs) for the SFC task. However, the performance was limited to only the fixed topology with labeled data. In this paper, we apply reinforcement learning methods for training models on various network topologies with unlabeled data. In the experiments, compared to the previous supervised learning method, the proposed methods demonstrated remarkable flexibility in new topologies without re-designing and re-training, while preserving a similar level of performance.