 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized Probabilistic Attention Mechanism in Transformers
Paper and Code
Oct 21, 2024

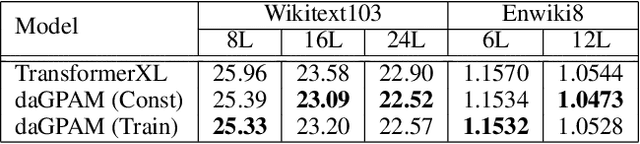

The Transformer architecture has become widely adopted due to its demonstrated success, attributed to the attention mechanism at its core. Despite these successes, the attention mechanism of Transformers is associated with two well-known issues: rank-collapse and gradient vanishing. In this paper, we present a theoretical analysis that it is inherently difficult to address both issues simultaneously in the conventional attention mechanism. To handle these issues, we introduce a novel class of attention mechanism, referred to as generalized probabilistic attention mechanism (GPAM), and its dual-attention implementation within the Transformer architecture. Unlike conventional attention mechanisms, GPAM allows for negative attention scores while preserving a fixed total sum. We provide theoretical evidence that the proposed dual-attention GPAM (daGPAM) effectively mitigates both the rank-collapse and gradient vanishing issues which are difficult to resolve simultaneously with the conventional attention mechanisms. Furthermore, we empirically validate this theoretical evidence, demonstrating the superiority of daGPAM compared to other alternative attention mechanisms that were proposed to address the same issues. Additionally, we demonstrate the practical benefits of GPAM in natural language processing tasks, such as language modeling and neural machine translation.