 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAVMeme Exam: A Multimodal Multilingual Multicultural Benchmark for LLMs' Contextual and Cultural Knowledge and Thinking
Jan 25, 2026Internet audio-visual clips convey meaning through time-varying sound and motion, which extend beyond what text alone can represent. To examine whether AI models can understand such signals in human cultural contexts, we introduce AVMeme Exam, a human-curated benchmark of over one thousand iconic Internet sounds and videos spanning speech, songs, music, and sound effects. Each meme is paired with a unique Q&A assessing levels of understanding from surface content to context and emotion to usage and world knowledge, along with metadata such as original year, transcript, summary, and sensitivity. We systematically evaluate state-of-the-art multimodal large language models (MLLMs) alongside human participants using this benchmark. Our results reveal a consistent limitation: current models perform poorly on textless music and sound effects, and struggle to think in context and in culture compared to surface content. These findings highlight a key gap in human-aligned multimodal intelligence and call for models that can perceive contextually and culturally beyond the surface of what they hear and see. Project page: avmemeexam.github.io/public
That's Deprecated! Understanding, Detecting, and Steering Knowledge Conflicts in Language Models for Code Generation
Oct 21, 2025This paper investigates how large language models (LLMs) behave when faced with discrepancies between their parametric knowledge and conflicting information contained in a prompt. Building on prior question-answering (QA) research, we extend the investigation of knowledge conflicts to the realm of code generation. We propose a domain-agnostic framework for constructing and interpreting such conflicts, along with a novel evaluation method and dataset tailored to code conflict scenarios. Our experiments indicate that sufficiently large LLMs encode the notion of a knowledge conflict in their parameters, enabling us to detect knowledge conflicts with up to \textbf{80.65\%} accuracy. Building on these insights, we show that activation-level steering can achieve up to a \textbf{12.6\%} improvement in steering success over a random baseline. However, effectiveness depends critically on balancing model size, task domain, and steering direction. The experiment code and data will be made publicly available after acceptance.
Multimodal Representation Loss Between Timed Text and Audio for Regularized Speech Separation
Jun 12, 2024Recent studies highlight the potential of textual modalities in conditioning the speech separation model's inference process. However, regularization-based methods remain underexplored despite their advantages of not requiring auxiliary text data during the test time. To address this gap, we introduce a timed text-based regularization (TTR) method that uses language model-derived semantics to improve speech separation models. Our approach involves two steps. We begin with two pretrained audio and language models, WavLM and BERT, respectively. Then, a Transformer-based audio summarizer is learned to align the audio and word embeddings and to minimize their gap. The summarizer Transformer, incorporated as a regularizer, promotes the separated sources' alignment with the semantics from the timed text. Experimental results show that the proposed TTR method consistently improves the various objective metrics of the separation results over the unregularized baselines.
On the Importance of Neural Wiener Filter for Resource Efficient Multichannel Speech Enhancement
Jan 15, 2024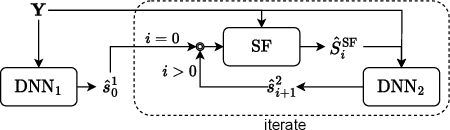
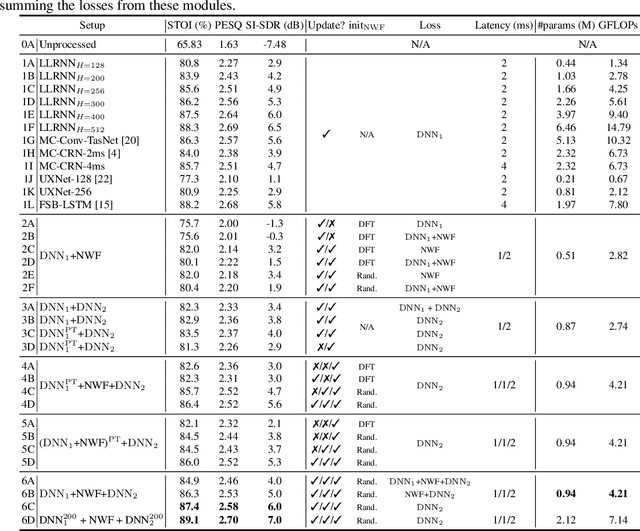
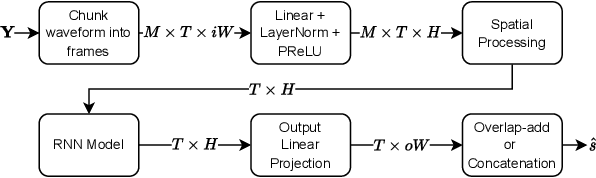
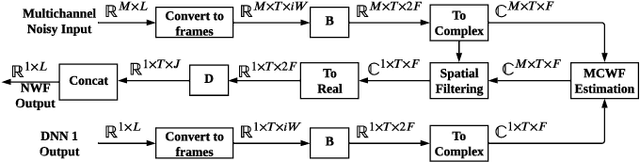
We introduce a time-domain framework for efficient multichannel speech enhancement, emphasizing low latency and computational efficiency. This framework incorporates two compact deep neural networks (DNNs) surrounding a multichannel neural Wiener filter (NWF). The first DNN enhances the speech signal to estimate NWF coefficients, while the second DNN refines the output from the NWF. The NWF, while conceptually similar to the traditional frequency-domain Wiener filter, undergoes a training process optimized for low-latency speech enhancement, involving fine-tuning of both analysis and synthesis transforms. Our research results illustrate that the NWF output, having minimal nonlinear distortions, attains performance levels akin to those of the first DNN, deviating from conventional Wiener filter paradigms. Training all components jointly outperforms sequential training, despite its simplicity. Consequently, this framework achieves superior performance with fewer parameters and reduced computational demands, making it a compelling solution for resource-efficient multichannel speech enhancement.
Inference and Denoise: Causal Inference-based Neural Speech Enhancement
Nov 02, 2022



This study addresses the speech enhancement (SE) task within the causal inference paradigm by modeling the noise presence as an intervention. Based on the potential outcome framework, the proposed causal inference-based speech enhancement (CISE) separates clean and noisy frames in an intervened noisy speech using a noise detector and assigns both sets of frames to two mask-based enhancement modules (EMs) to perform noise-conditional SE. Specifically, we use the presence of noise as guidance for EM selection during training, and the noise detector selects the enhancement module according to the prediction of the presence of noise for each frame. Moreover, we derived a SE-specific average treatment effect to quantify the causal effect adequately. Experimental evidence demonstrates that CISE outperforms a non-causal mask-based SE approach in the studied settings and has better performance and efficiency than more complex SE models.
OSSEM: one-shot speaker adaptive speech enhancement using meta learning
Nov 10, 2021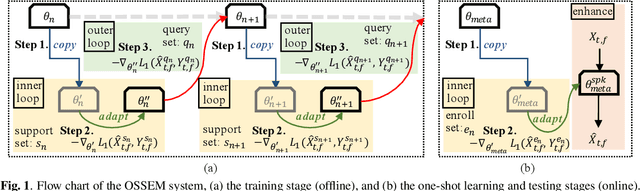
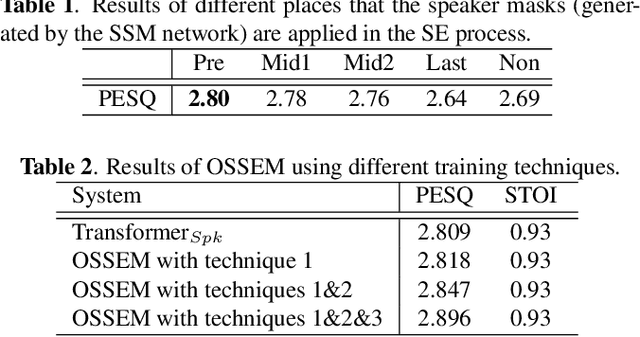
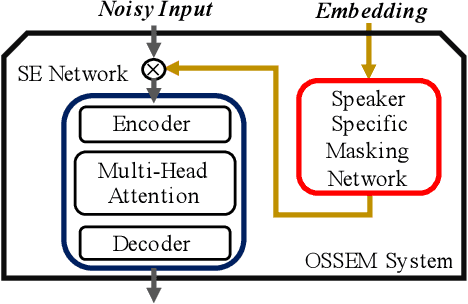
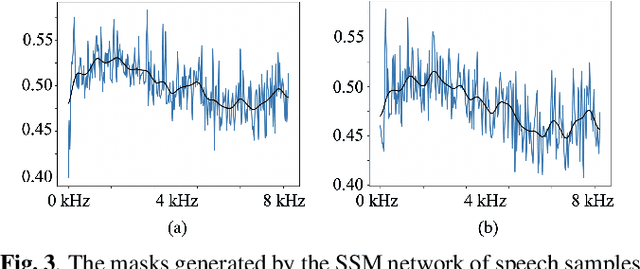
Although deep learning (DL) has achieved notable progress in speech enhancement (SE), further research is still required for a DL-based SE system to adapt effectively and efficiently to particular speakers. In this study, we propose a novel meta-learning-based speaker-adaptive SE approach (called OSSEM) that aims to achieve SE model adaptation in a one-shot manner. OSSEM consists of a modified transformer SE network and a speaker-specific masking (SSM) network. In practice, the SSM network takes an enrolled speaker embedding extracted using ECAPA-TDNN to adjust the input noisy feature through masking. To evaluate OSSEM, we designed a modified Voice Bank-DEMAND dataset, in which one utterance from the testing set was used for model adaptation, and the remaining utterances were used for testing the performance. Moreover, we set restrictions allowing the enhancement process to be conducted in real time, and thus designed OSSEM to be a causal SE system. Experimental results first show that OSSEM can effectively adapt a pretrained SE model to a particular speaker with only one utterance, thus yielding improved SE results. Meanwhile, OSSEM exhibits a competitive performance compared to state-of-the-art causal SE systems.
Intermittent Speech Recovery
Jun 09, 2021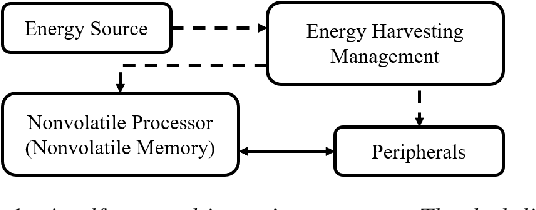

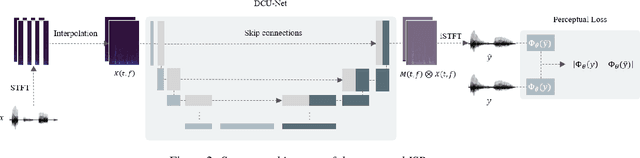
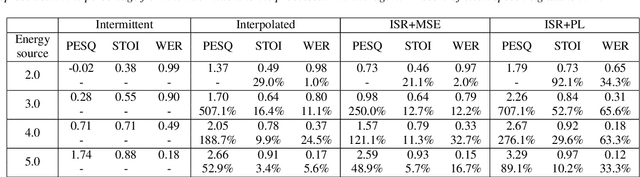
A large number of Internet of Things (IoT) devices today are powered by batteries, which are often expensive to maintain and may cause serious environmental pollution. To avoid these problems, researchers have begun to consider the use of energy systems based on energy-harvesting units for such devices. However, the power harvested from an ambient source is fundamentally small and unstable, resulting in frequent power failures during the operation of IoT applications involving, for example, intermittent speech signals and the streaming of videos. This paper presents a deep-learning-based speech recovery system that reconstructs intermittent speech signals from self-powered IoT devices. Our intermittent speech recovery system (ISR) consists of three stages: interpolation, recovery, and combination. The experimental results show that our recovery system increases speech quality by up to 707.1%, while increasing speech intelligibility by up to 92.1%. Most importantly, our ISR system also enhances the WER scores by up to 65.6%. To the best of our knowledge, this study is one of the first to reconstruct intermittent speech signals from self-powered-sensing IoT devices. These promising results suggest that even though self powered microphone devices function with weak energy sources, our ISR system can still maintain the performance of most speech-signal-based applications.
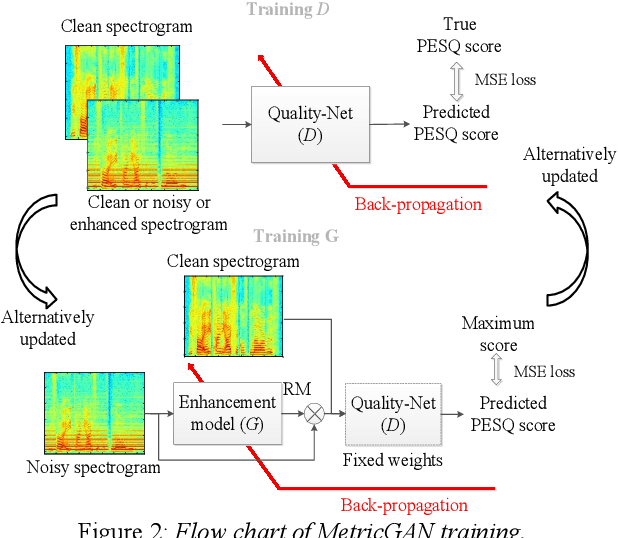
MetricGAN+: An Improved Version of MetricGAN for Speech Enhancement
Apr 08, 2021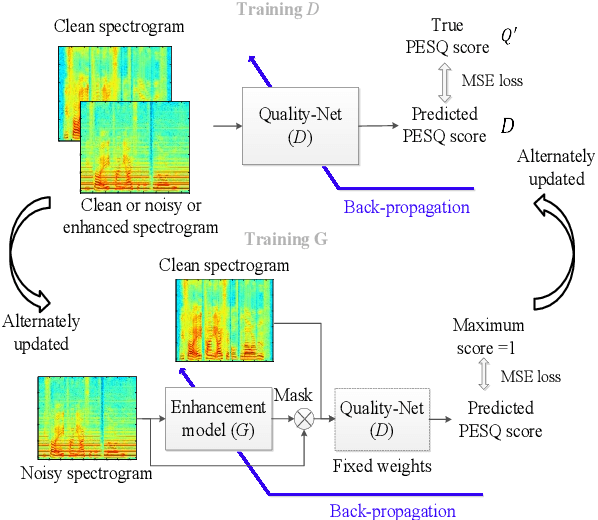
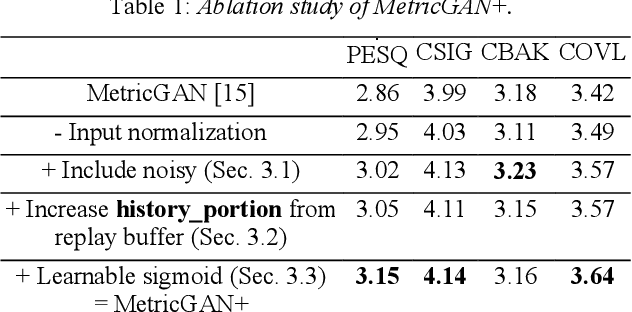
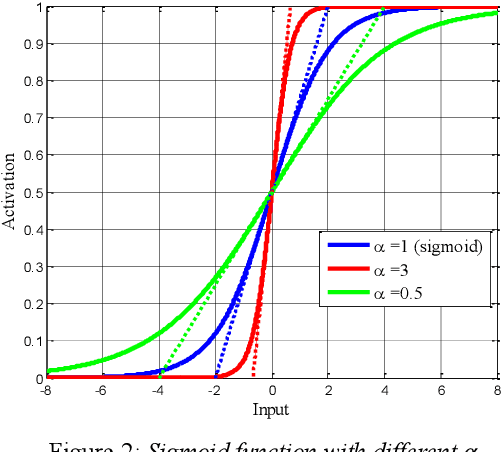

The discrepancy between the cost function used for training a speech enhancement model and human auditory perception usually makes the quality of enhanced speech unsatisfactory. Objective evaluation metrics which consider human perception can hence serve as a bridge to reduce the gap. Our previously proposed MetricGAN was designed to optimize objective metrics by connecting the metric with a discriminator. Because only the scores of the target evaluation functions are needed during training, the metrics can even be non-differentiable. In this study, we propose a MetricGAN+ in which three training techniques incorporating domain-knowledge of speech processing are proposed. With these techniques, experimental results on the VoiceBank-DEMAND dataset show that MetricGAN+ can increase PESQ score by 0.3 compared to the previous MetricGAN and achieve state-of-the-art results (PESQ score = 3.15).
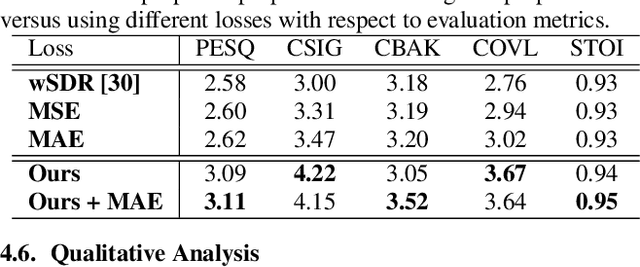
Improving Perceptual Quality by Phone-Fortified Perceptual Loss for Speech Enhancement
Oct 30, 2020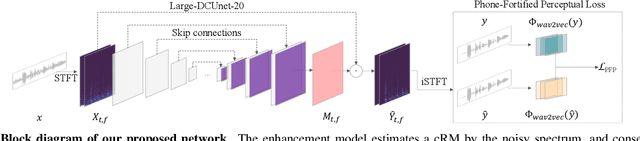
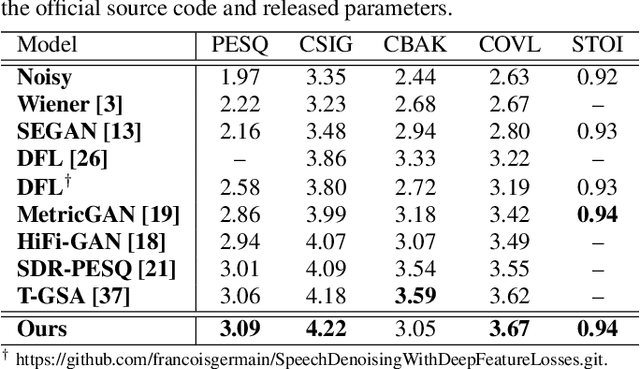
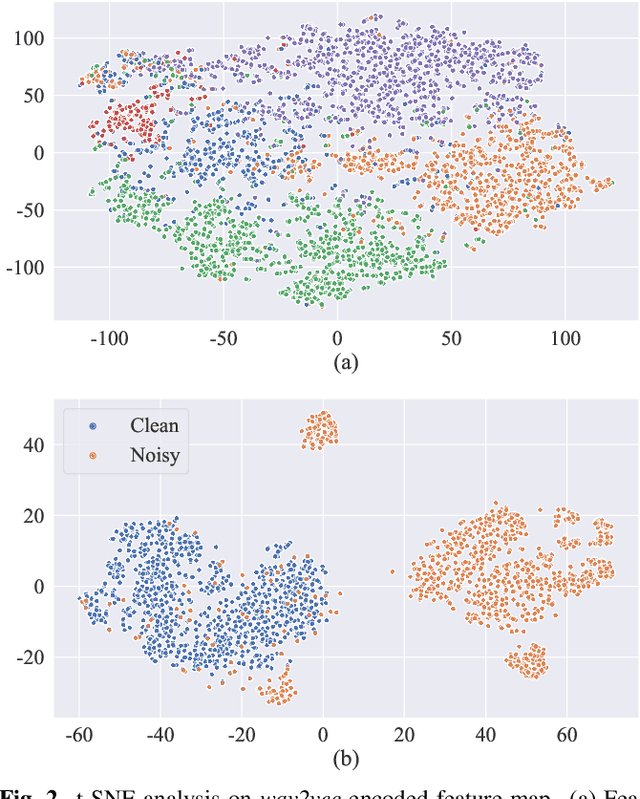
Speech enhancement (SE) aims to improve speech quality and intelligibility, which are both related to a smooth transition in speech segments that may carry linguistic information, e.g. phones and syllables. In this study, we took phonetic characteristics into account in the SE training process. Hence, we designed a phone-fortified perceptual (PFP) loss, and the training of our SE model was guided by PFP loss. In PFP loss, phonetic characteristics are extracted by wav2vec, an unsupervised learning model based on the contrastive predictive coding (CPC) criterion. Different from previous deep-feature-based approaches, the proposed approach explicitly uses the phonetic information in the deep feature extraction process to guide the SE model training. To test the proposed approach, we first confirmed that the wav2vec representations carried clear phonetic information using a t-distributed stochastic neighbor embedding (t-SNE) analysis. Next, we observed that the proposed PFP loss was more strongly correlated with the perceptual evaluation metrics than point-wise and signal-level losses, thus achieving higher scores for standardized quality and intelligibility evaluation metrics in the Voice Bank-DEMAND dataset.
Boosting Objective Scores of Speech Enhancement Model through MetricGAN Post-Processing
Jun 18, 2020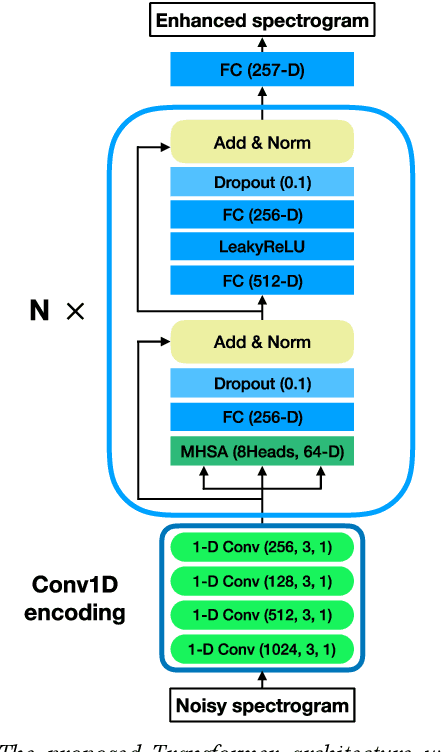
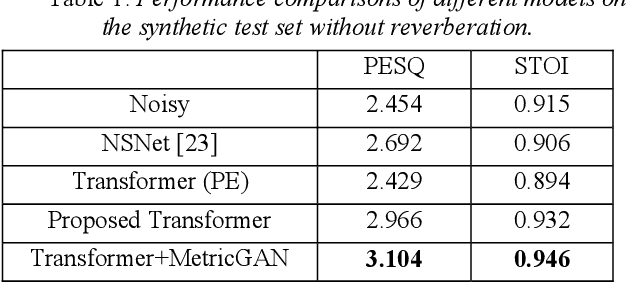

The Transformer architecture has shown its superior ability than recurrent neural networks on many different natural language processing applications. Therefore, this study applies a modified Transformer on the speech enhancement task. Specifically, the positional encoding may not be necessary and hence is replaced by convolutional layers. To further improve PESQ scores of enhanced speech, the L_1 pre-trained Transformer is fine-tuned by MetricGAN framework. The proposed MetricGAN can be treated as a general post-processing module to further boost interested objective scores. The experiments are conducted using the data sets provided by the organizer of the Deep Noise Suppression (DNS) challenge. Experimental results demonstrate that the proposed system outperforms the challenge baseline in both subjective and objective evaluation with a large margin.