 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRETENTION: Resource-Efficient Tree-Based Ensemble Model Acceleration with Content-Addressable Memory
Jun 06, 2025Although deep learning has demonstrated remarkable capabilities in learning from unstructured data, modern tree-based ensemble models remain superior in extracting relevant information and learning from structured datasets. While several efforts have been made to accelerate tree-based models, the inherent characteristics of the models pose significant challenges for conventional accelerators. Recent research leveraging content-addressable memory (CAM) offers a promising solution for accelerating tree-based models, yet existing designs suffer from excessive memory consumption and low utilization. This work addresses these challenges by introducing RETENTION, an end-to-end framework that significantly reduces CAM capacity requirement for tree-based model inference. We propose an iterative pruning algorithm with a novel pruning criterion tailored for bagging-based models (e.g., Random Forest), which minimizes model complexity while ensuring controlled accuracy degradation. Additionally, we present a tree mapping scheme that incorporates two innovative data placement strategies to alleviate the memory redundancy caused by the widespread use of don't care states in CAM. Experimental results show that implementing the tree mapping scheme alone achieves $1.46\times$ to $21.30 \times$ better space efficiency, while the full RETENTION framework yields $4.35\times$ to $207.12\times$ improvement with less than 3% accuracy loss. These results demonstrate that RETENTION is highly effective in reducing CAM capacity requirement, providing a resource-efficient direction for tree-based model acceleration.
Easz: An Agile Transformer-based Image Compression Framework for Resource-constrained IoTs
May 03, 2025Neural image compression, necessary in various machine-to-machine communication scenarios, suffers from its heavy encode-decode structures and inflexibility in switching between different compression levels. Consequently, it raises significant challenges in applying the neural image compression to edge devices that are developed for powerful servers with high computational and storage capacities. We take a step to solve the challenges by proposing a new transformer-based edge-compute-free image coding framework called Easz. Easz shifts the computational overhead to the server, and hence avoids the heavy encoding and model switching overhead on the edge. Easz utilizes a patch-erase algorithm to selectively remove image contents using a conditional uniform-based sampler. The erased pixels are reconstructed on the receiver side through a transformer-based framework. To further reduce the computational overhead on the receiver, we then introduce a lightweight transformer-based reconstruction structure to reduce the reconstruction load on the receiver side. Extensive evaluations conducted on a real-world testbed demonstrate multiple advantages of Easz over existing compression approaches, in terms of adaptability to different compression levels, computational efficiency, and image reconstruction quality.
Retrieval-Augmented Generation for Natural Language Processing: A Survey
Jul 19, 2024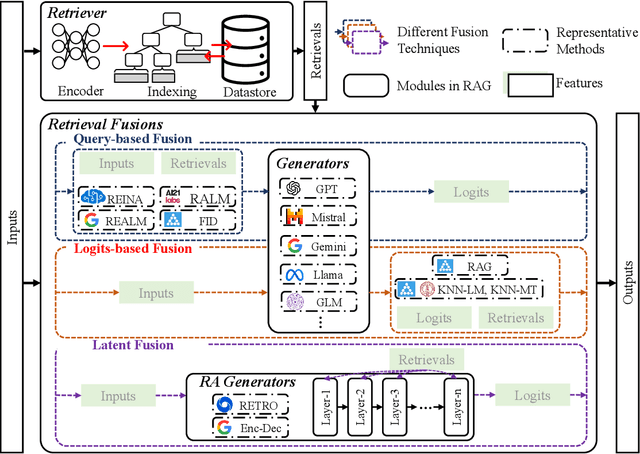
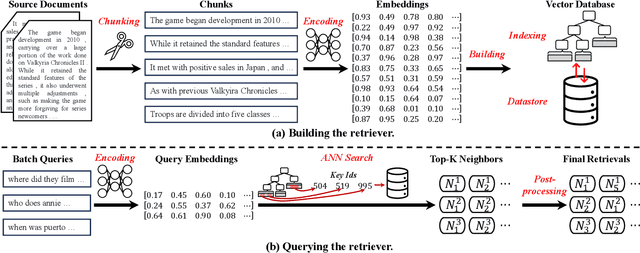
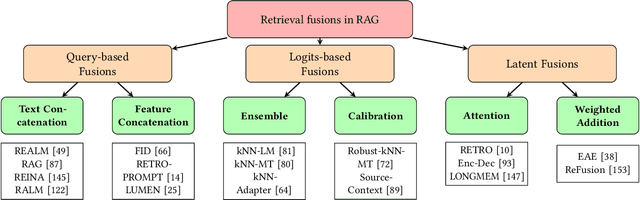
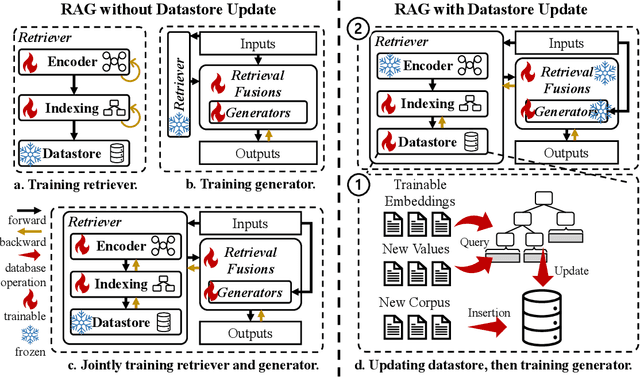
Large language models (LLMs) have demonstrated great success in various fields, benefiting from their huge amount of parameters that store knowledge. However, LLMs still suffer from several key issues, such as hallucination problems, knowledge update issues, and lacking domain-specific expertise. The appearance of retrieval-augmented generation (RAG), which leverages an external knowledge database to augment LLMs, makes up those drawbacks of LLMs. This paper reviews all significant techniques of RAG, especially in the retriever and the retrieval fusions. Besides, tutorial codes are provided for implementing the representative techniques in RAG. This paper further discusses the RAG training, including RAG with/without datastore update. Then, we introduce the application of RAG in representative natural language processing tasks and industrial scenarios. Finally, this paper discusses the future directions and challenges of RAG for promoting its development.
RAEE: A Training-Free Retrieval-Augmented Early Exiting Framework for Efficient Inference
May 24, 2024



Deploying large language model inference remains challenging due to their high computational overhead. Early exiting accelerates model inference by adaptively reducing the number of inference layers. Existing methods require training internal classifiers to determine whether to exit at each intermediate layer. However, such classifier-based early exiting frameworks require significant effort to design and train the classifiers. To address these limitations, this paper proposes RAEE, a training-free Retrieval-Augmented Early Exiting framework for efficient inference. First, this paper demonstrates that the early exiting problem can be modeled as a distribution prediction problem, where the distribution is approximated using similar data's existing information. Next, the paper details the process of collecting existing information to build the retrieval database. Finally, based on the pre-built retrieval database, RAEE leverages the retrieved similar data's exiting information to guide the backbone model to exit at the layer, which is predicted by the approximated distribution. Experimental results demonstrate that the proposed RAEE can significantly accelerate inference. RAEE also achieves state-of-the-art zero-shot performance on 8 classification tasks.
Improving Natural Language Understanding with Computation-Efficient Retrieval Representation Fusion
Jan 04, 2024Retrieval-based augmentations that aim to incorporate knowledge from an external database into language models have achieved great success in various knowledge-intensive (KI) tasks, such as question-answering and text generation. However, integrating retrievals in non-knowledge-intensive (NKI) tasks, such as text classification, is still challenging. Existing works focus on concatenating retrievals to inputs as context to form the prompt-based inputs. Unfortunately, such methods require language models to have the capability to handle long texts. Besides, inferring such concatenated data would also consume a significant amount of computational resources. To solve these challenges, we propose \textbf{ReFusion} in this paper, a computation-efficient \textbf{Re}trieval representation \textbf{Fusion} with neural architecture search. The main idea is to directly fuse the retrieval representations into the language models. Specifically, we first propose an online retrieval module that retrieves representations of similar sentences. Then, we present a retrieval fusion module including two effective ranking schemes, i.e., reranker-based scheme and ordered-mask-based scheme, to fuse the retrieval representations with hidden states. Furthermore, we use Neural Architecture Search (NAS) to seek the optimal fusion structure across different layers. Finally, we conduct comprehensive experiments, and the results demonstrate our ReFusion can achieve superior and robust performance on various NKI tasks.
BiTrackGAN: Cascaded CycleGANs to Constraint Face Aging
Apr 22, 2023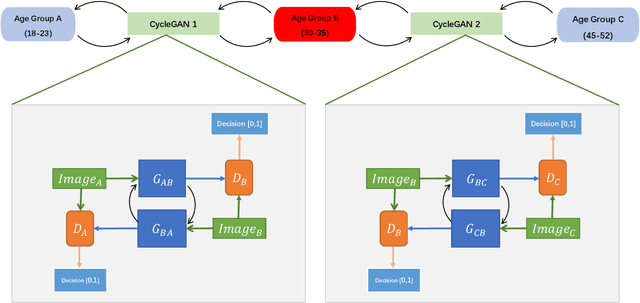


With the increased accuracy of modern computer vision technology, many access control systems are equipped with face recognition functions for faster identification. In order to maintain high recognition accuracy, it is necessary to keep the face database up-to-date. However, it is impractical to collect the latest facial picture of the system's user through human effort. Thus, we propose a bottom-up training method for our proposed network to address this challenge. Essentially, our proposed network is a translation pipeline that cascades two CycleGAN blocks (a widely used unpaired image-to-image translation generative adversarial network) called BiTrackGAN. By bottom-up training, it induces an ideal intermediate state between these two CycleGAN blocks, namely the constraint mechanism. Experimental results show that BiTrackGAN achieves more reasonable and diverse cross-age facial synthesis than other CycleGAN-related methods. As far as we know, it is a novel and effective constraint mechanism for more reason and accurate aging synthesis through the CycleGAN approach.
NFL: Robust Learned Index via Distribution Transformation
May 24, 2022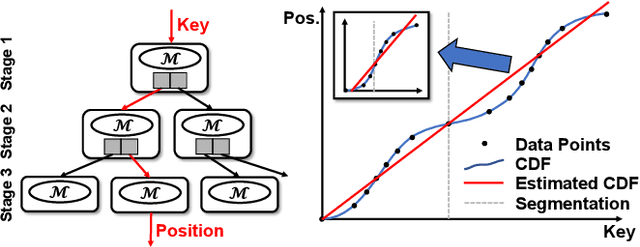
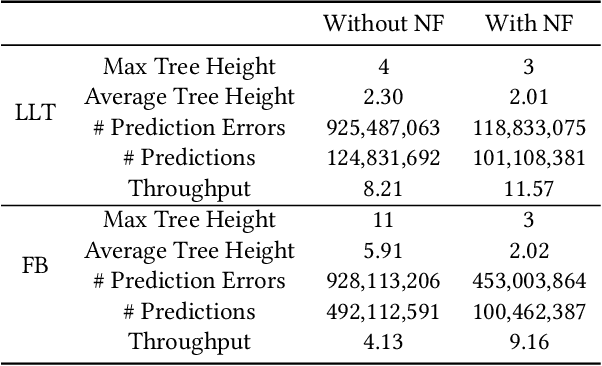
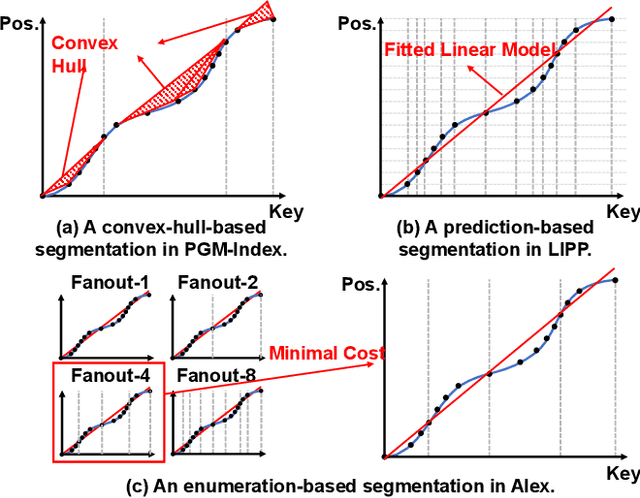
Recent works on learned index open a new direction for the indexing field. The key insight of the learned index is to approximate the mapping between keys and positions with piece-wise linear functions. Such methods require partitioning key space for a better approximation. Although lots of heuristics are proposed to improve the approximation quality, the bottleneck is that the segmentation overheads could hinder the overall performance. This paper tackles the approximation problem by applying a \textit{distribution transformation} to the keys before constructing the learned index. A two-stage Normalizing-Flow-based Learned index framework (NFL) is proposed, which first transforms the original complex key distribution into a near-uniform distribution, then builds a learned index leveraging the transformed keys. For effective distribution transformation, we propose a Numerical Normalizing Flow (Numerical NF). Based on the characteristics of the transformed keys, we propose a robust After-Flow Learned Index (AFLI). To validate the performance, comprehensive evaluations are conducted on both synthetic and real-world workloads, which shows that the proposed NFL produces the highest throughput and the lowest tail latency compared to the state-of-the-art learned indexes.
A Fast Transformer-based General-Purpose Lossless Compressor
Apr 01, 2022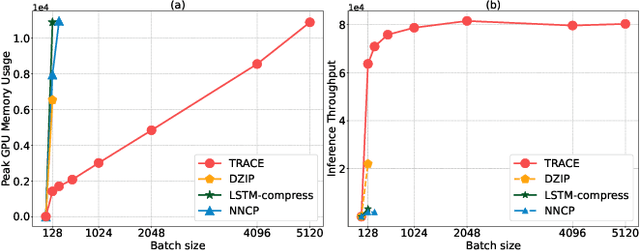
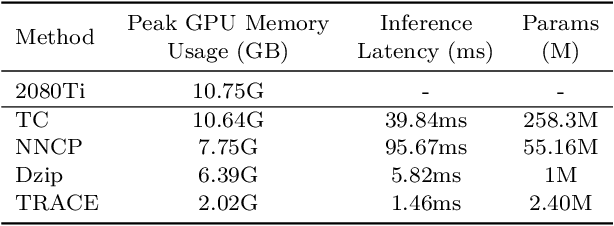
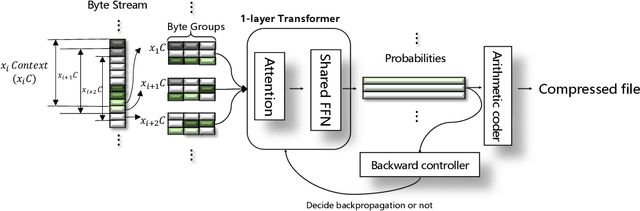
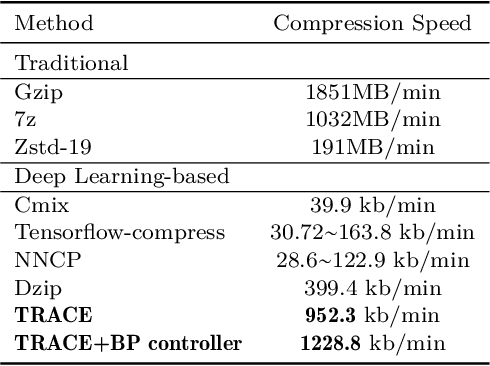
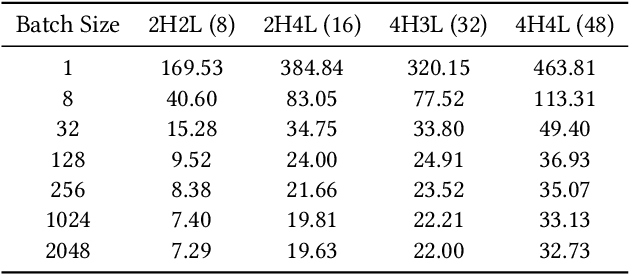
Deep-learning-based compressor has received interests recently due to much improved compression ratio. However, modern approaches suffer from long execution time. To ease this problem, this paper targets on cutting down the execution time of deep-learning-based compressors. Building history-dependencies sequentially (e.g., recurrent neural networks) is responsible for long inference latency. Instead, we introduce transformer into deep learning compressors to build history-dependencies in parallel. However, existing transformer is too heavy in computation and incompatible to compression tasks. This paper proposes a fast general-purpose lossless compressor, TRACE, by designing a compression-friendly structure based on a single-layer transformer. We first design a new metric to advise the selection part of compression model structures. Byte-grouping and Shared-ffn schemes are further proposed to fully utilize the capacity of the single-layer transformer. These features allow TRACE to achieve competitive compression ratio and a much faster speed. In addition, we further accelerate the compression procedure by designing a controller to reduce the parameter updating overhead. Experiments show that TRACE achieves an overall $\sim$3x speedup while keeps a comparable compression ratio to the state-of-the-art compressors. The source code for TRACE and links to the datasets are available at https://github.com/mynotwo/A-Fast-Transformer-based-General-Purpose-LosslessCompressor.
SEOFP-NET: Compression and Acceleration of Deep Neural Networks for Speech Enhancement Using Sign-Exponent-Only Floating-Points
Nov 08, 2021
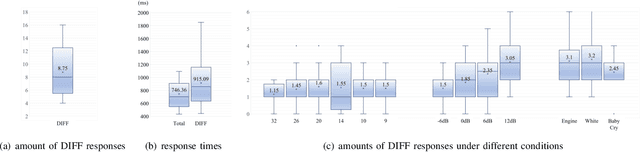
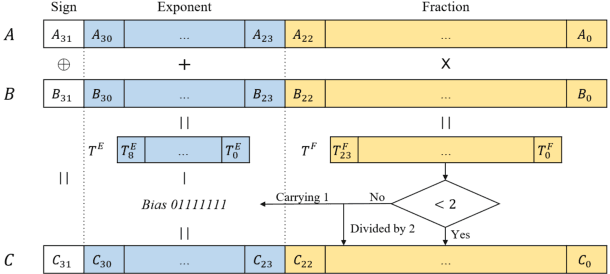
Numerous compression and acceleration strategies have achieved outstanding results on classification tasks in various fields, such as computer vision and speech signal processing. Nevertheless, the same strategies have yielded ungratified performance on regression tasks because the nature between these and classification tasks differs. In this paper, a novel sign-exponent-only floating-point network (SEOFP-NET) technique is proposed to compress the model size and accelerate the inference time for speech enhancement, a regression task of speech signal processing. The proposed method compressed the sizes of deep neural network (DNN)-based speech enhancement models by quantizing the fraction bits of single-precision floating-point parameters during training. Before inference implementation, all parameters in the trained SEOFP-NET model are slightly adjusted to accelerate the inference time by replacing the floating-point multiplier with an integer-adder. For generalization, the SEOFP-NET technique is introduced to different speech enhancement tasks in speech signal processing with different model architectures under various corpora. The experimental results indicate that the size of SEOFP-NET models can be significantly compressed by up to 81.249% without noticeably downgrading their speech enhancement performance, and the inference time can be accelerated to 1.212x compared with the baseline models. The results also verify that the proposed SEOFP-NET can cooperate with other efficiency strategies to achieve a synergy effect for model compression. In addition, the just noticeable difference (JND) was applied to the user study experiment to statistically analyze the effect of speech enhancement on listening. The results indicate that the listeners cannot facilely differentiate between the enhanced speech signals processed by the baseline model and the proposed SEOFP-NET.
Intermittent Speech Recovery
Jun 09, 2021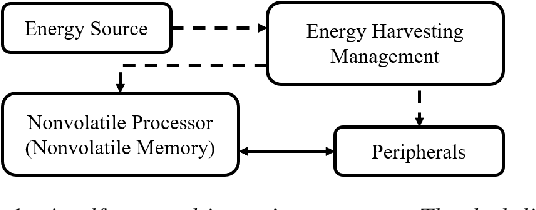

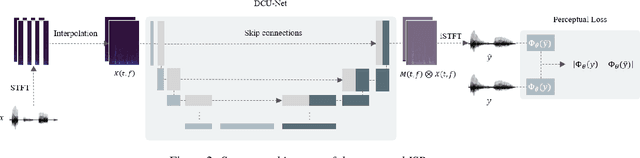
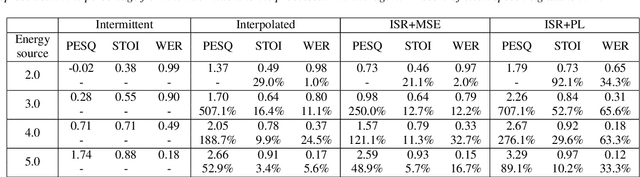
A large number of Internet of Things (IoT) devices today are powered by batteries, which are often expensive to maintain and may cause serious environmental pollution. To avoid these problems, researchers have begun to consider the use of energy systems based on energy-harvesting units for such devices. However, the power harvested from an ambient source is fundamentally small and unstable, resulting in frequent power failures during the operation of IoT applications involving, for example, intermittent speech signals and the streaming of videos. This paper presents a deep-learning-based speech recovery system that reconstructs intermittent speech signals from self-powered IoT devices. Our intermittent speech recovery system (ISR) consists of three stages: interpolation, recovery, and combination. The experimental results show that our recovery system increases speech quality by up to 707.1%, while increasing speech intelligibility by up to 92.1%. Most importantly, our ISR system also enhances the WER scores by up to 65.6%. To the best of our knowledge, this study is one of the first to reconstruct intermittent speech signals from self-powered-sensing IoT devices. These promising results suggest that even though self powered microphone devices function with weak energy sources, our ISR system can still maintain the performance of most speech-signal-based applications.