 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeACCEPT: Adaptive Codebook for Composite and Efficient Prompt Tuning
Oct 10, 2024



Prompt Tuning has been a popular Parameter-Efficient Fine-Tuning method attributed to its remarkable performance with few updated parameters on various large-scale pretrained Language Models (PLMs). Traditionally, each prompt has been considered indivisible and updated independently, leading the parameters increase proportionally as prompt length grows. To address this issue, we propose Adaptive Codebook for Composite and Efficient Prompt Tuning (ACCEPT). In our method, we refer to the concept of product quantization (PQ), allowing all soft prompts to share a set of learnable codebook vectors in each subspace, with each prompt differentiated by a set of adaptive weights. We achieve the superior performance on 17 diverse natural language tasks including natural language understanding (NLU) and question answering (QA) tasks by tuning only 0.3% of parameters of the PLMs. Our approach also excels in few-shot and large model settings, highlighting its significant potential.
Improving Facial Landmark Detection Accuracy and Efficiency with Knowledge Distillation
Apr 09, 2024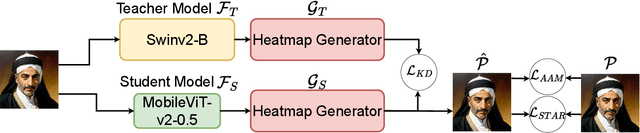

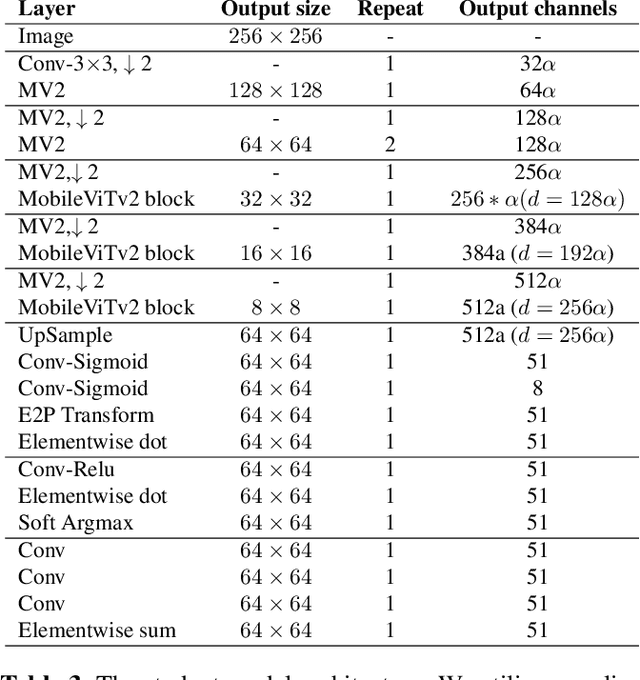
The domain of computer vision has experienced significant advancements in facial-landmark detection, becoming increasingly essential across various applications such as augmented reality, facial recognition, and emotion analysis. Unlike object detection or semantic segmentation, which focus on identifying objects and outlining boundaries, faciallandmark detection aims to precisely locate and track critical facial features. However, deploying deep learning-based facial-landmark detection models on embedded systems with limited computational resources poses challenges due to the complexity of facial features, especially in dynamic settings. Additionally, ensuring robustness across diverse ethnicities and expressions presents further obstacles. Existing datasets often lack comprehensive representation of facial nuances, particularly within populations like those in Taiwan. This paper introduces a novel approach to address these challenges through the development of a knowledge distillation method. By transferring knowledge from larger models to smaller ones, we aim to create lightweight yet powerful deep learning models tailored specifically for facial-landmark detection tasks. Our goal is to design models capable of accurately locating facial landmarks under varying conditions, including diverse expressions, orientations, and lighting environments. The ultimate objective is to achieve high accuracy and real-time performance suitable for deployment on embedded systems. This method was successfully implemented and achieved a top 6th place finish out of 165 participants in the IEEE ICME 2024 PAIR competition.
Applications of Large Language Models in Data Processing: Innovative Approaches to Segmenting and Renewing Information
Nov 27, 2023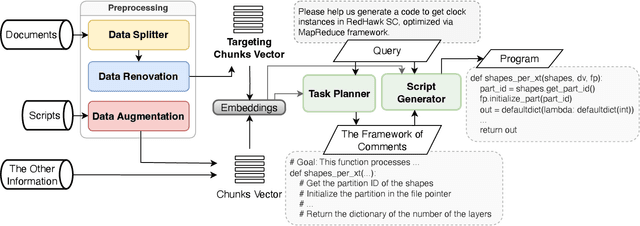
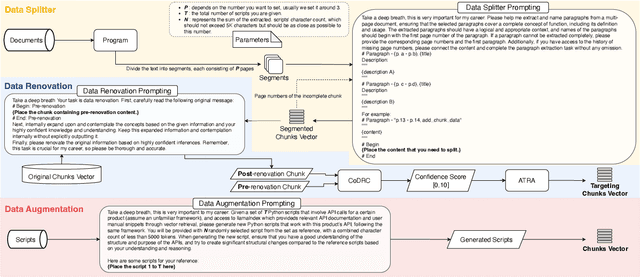


Our paper investigates effective methods for code generation in "specific-domain" applications, including the use of Large Language Models (LLMs) for data segmentation and renewal, as well as stimulating deeper thinking in LLMs through prompt adjustments. Using a real company product as an example, we provide user manuals, API documentation, and other data. The ideas discussed in this paper help segment and then convert this data into semantic vectors to better reflect their true positioning. Subsequently, user requirements are transformed into vectors to retrieve the most relevant content, achieving about 70% accuracy in simple to medium-complexity tasks through various prompt techniques. This paper is the first to enhance specific-domain code generation effectiveness from this perspective. Additionally, we experiment with generating more scripts from a limited number using llama2-based fine-tuning to test its effectiveness in professional domain code generation. This is a challenging and promising field, and once achieved, it will not only lead to breakthroughs in LLM development across multiple industries but also enable LLMs to understand and learn any new knowledge effectively.
Adapting pretrained speech model for Mandarin lyrics transcription and alignment
Nov 21, 2023



The tasks of automatic lyrics transcription and lyrics alignment have witnessed significant performance improvements in the past few years. However, most of the previous works only focus on English in which large-scale datasets are available. In this paper, we address lyrics transcription and alignment of polyphonic Mandarin pop music in a low-resource setting. To deal with the data scarcity issue, we adapt pretrained Whisper model and fine-tune it on a monophonic Mandarin singing dataset. With the use of data augmentation and source separation model, results show that the proposed method achieves a character error rate of less than 18% on a Mandarin polyphonic dataset for lyrics transcription, and a mean absolute error of 0.071 seconds for lyrics alignment. Our results demonstrate the potential of adapting a pretrained speech model for lyrics transcription and alignment in low-resource scenarios.
Domain-Generalized Face Anti-Spoofing with Unknown Attacks
Oct 18, 2023



Although face anti-spoofing (FAS) methods have achieved remarkable performance on specific domains or attack types, few studies have focused on the simultaneous presence of domain changes and unknown attacks, which is closer to real application scenarios. To handle domain-generalized unknown attacks, we introduce a new method, DGUA-FAS, which consists of a Transformer-based feature extractor and a synthetic unknown attack sample generator (SUASG). The SUASG network simulates unknown attack samples to assist the training of the feature extractor. Experimental results show that our method achieves superior performance on domain generalization FAS with known or unknown attacks.
Linear Classifier: An Often-Forgotten Baseline for Text Classification
Jun 12, 2023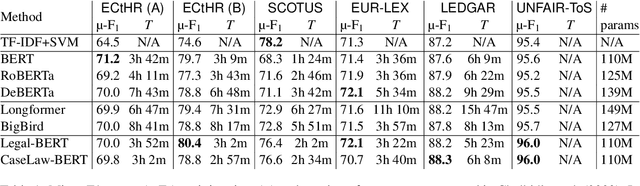
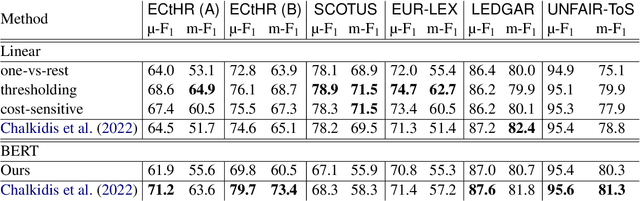
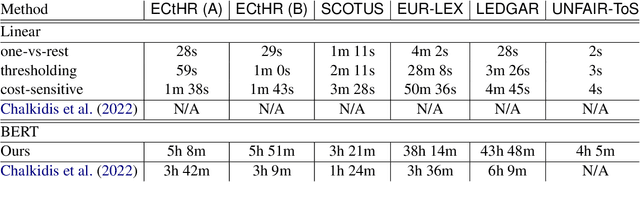

Large-scale pre-trained language models such as BERT are popular solutions for text classification. Due to the superior performance of these advanced methods, nowadays, people often directly train them for a few epochs and deploy the obtained model. In this opinion paper, we point out that this way may only sometimes get satisfactory results. We argue the importance of running a simple baseline like linear classifiers on bag-of-words features along with advanced methods. First, for many text data, linear methods show competitive performance, high efficiency, and robustness. Second, advanced models such as BERT may only achieve the best results if properly applied. Simple baselines help to confirm whether the results of advanced models are acceptable. Our experimental results fully support these points.
NASTAR: Noise Adaptive Speech Enhancement with Target-Conditional Resampling
Jun 18, 2022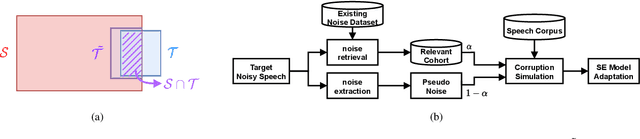
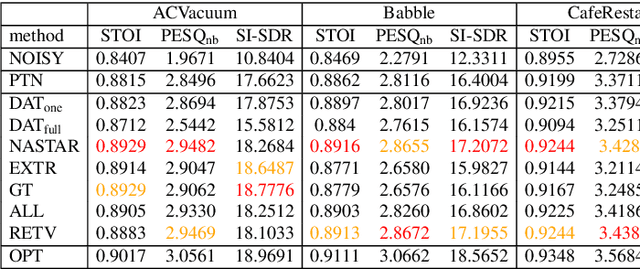
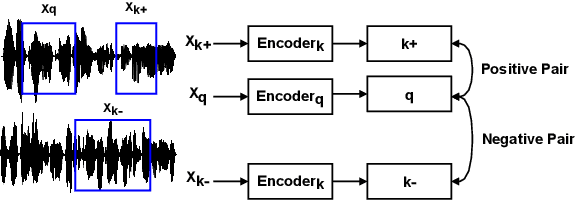
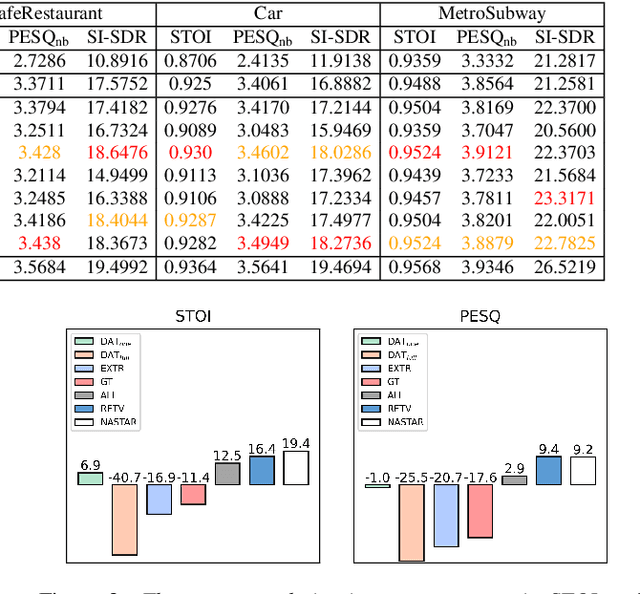
For deep learning-based speech enhancement (SE) systems, the training-test acoustic mismatch can cause notable performance degradation. To address the mismatch issue, numerous noise adaptation strategies have been derived. In this paper, we propose a novel method, called noise adaptive speech enhancement with target-conditional resampling (NASTAR), which reduces mismatches with only one sample (one-shot) of noisy speech in the target environment. NASTAR uses a feedback mechanism to simulate adaptive training data via a noise extractor and a retrieval model. The noise extractor estimates the target noise from the noisy speech, called pseudo-noise. The noise retrieval model retrieves relevant noise samples from a pool of noise signals according to the noisy speech, called relevant-cohort. The pseudo-noise and the relevant-cohort set are jointly sampled and mixed with the source speech corpus to prepare simulated training data for noise adaptation. Experimental results show that NASTAR can effectively use one noisy speech sample to adapt an SE model to a target condition. Moreover, both the noise extractor and the noise retrieval model contribute to model adaptation. To our best knowledge, NASTAR is the first work to perform one-shot noise adaptation through noise extraction and retrieval.
SEOFP-NET: Compression and Acceleration of Deep Neural Networks for Speech Enhancement Using Sign-Exponent-Only Floating-Points
Nov 08, 2021
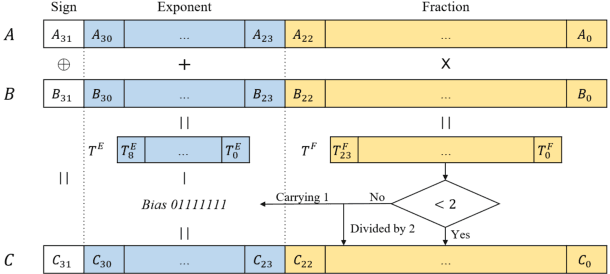
Numerous compression and acceleration strategies have achieved outstanding results on classification tasks in various fields, such as computer vision and speech signal processing. Nevertheless, the same strategies have yielded ungratified performance on regression tasks because the nature between these and classification tasks differs. In this paper, a novel sign-exponent-only floating-point network (SEOFP-NET) technique is proposed to compress the model size and accelerate the inference time for speech enhancement, a regression task of speech signal processing. The proposed method compressed the sizes of deep neural network (DNN)-based speech enhancement models by quantizing the fraction bits of single-precision floating-point parameters during training. Before inference implementation, all parameters in the trained SEOFP-NET model are slightly adjusted to accelerate the inference time by replacing the floating-point multiplier with an integer-adder. For generalization, the SEOFP-NET technique is introduced to different speech enhancement tasks in speech signal processing with different model architectures under various corpora. The experimental results indicate that the size of SEOFP-NET models can be significantly compressed by up to 81.249% without noticeably downgrading their speech enhancement performance, and the inference time can be accelerated to 1.212x compared with the baseline models. The results also verify that the proposed SEOFP-NET can cooperate with other efficiency strategies to achieve a synergy effect for model compression. In addition, the just noticeable difference (JND) was applied to the user study experiment to statistically analyze the effect of speech enhancement on listening. The results indicate that the listeners cannot facilely differentiate between the enhanced speech signals processed by the baseline model and the proposed SEOFP-NET.
Intermittent Speech Recovery
Jun 09, 2021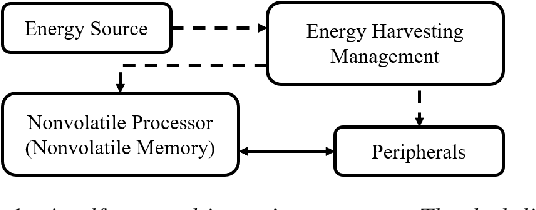

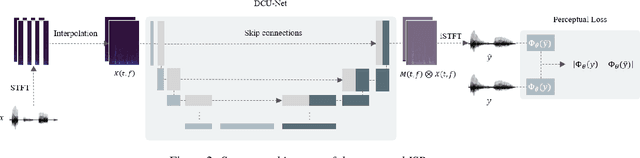
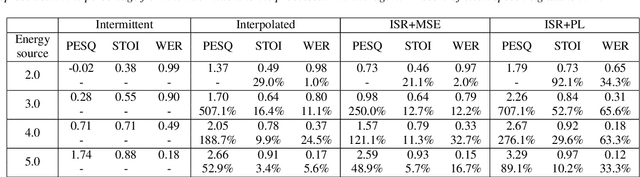
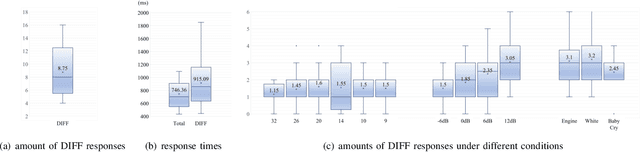
A large number of Internet of Things (IoT) devices today are powered by batteries, which are often expensive to maintain and may cause serious environmental pollution. To avoid these problems, researchers have begun to consider the use of energy systems based on energy-harvesting units for such devices. However, the power harvested from an ambient source is fundamentally small and unstable, resulting in frequent power failures during the operation of IoT applications involving, for example, intermittent speech signals and the streaming of videos. This paper presents a deep-learning-based speech recovery system that reconstructs intermittent speech signals from self-powered IoT devices. Our intermittent speech recovery system (ISR) consists of three stages: interpolation, recovery, and combination. The experimental results show that our recovery system increases speech quality by up to 707.1%, while increasing speech intelligibility by up to 92.1%. Most importantly, our ISR system also enhances the WER scores by up to 65.6%. To the best of our knowledge, this study is one of the first to reconstruct intermittent speech signals from self-powered-sensing IoT devices. These promising results suggest that even though self powered microphone devices function with weak energy sources, our ISR system can still maintain the performance of most speech-signal-based applications.
SERIL: Noise Adaptive Speech Enhancement using Regularization-based Incremental Learning
May 24, 2020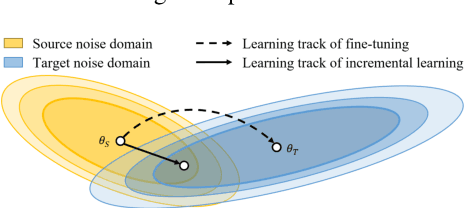
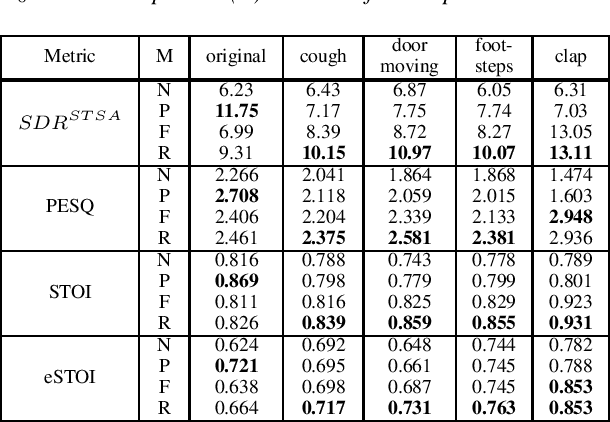

Numerous noise adaptation techniques have been proposed to address the mismatch problem in speech enhancement (SE) by fine-tuning deep-learning (DL)-based models. However, adaptation to a target domain can lead to catastrophic forgetting of the previously learnt noise environments. Because SE models are commonly used in embedded devices, re-visiting previous noise environments is a common situation in speech enhancement. In this paper, we propose a novel regularization-based incremental learning SE (SERIL) strategy, which can complement these noise adaptation strategies without having to access previous training data. The experimental results show that, when faced with a new noise domain, the SERIL model outperforms the unadapted SE model in various metrics: PESQ, STOI, eSTOI, and short-time spectral amplitude SDR. Meanwhile, compared with the traditional fine-tuning adaptive SE model, the SERIL model can significantly reduce the forgetting of previous noise environments by 52%. The promising results indicate that the SERIL model can effectively overcome the catastrophic forgetting problem and can be suitably deployed in real-world applications, where the noise environment changes frequently.