 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApplications of Large Language Models in Data Processing: Innovative Approaches to Segmenting and Renewing Information
Paper and Code
Nov 27, 2023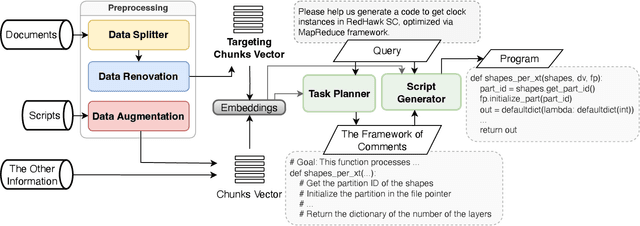
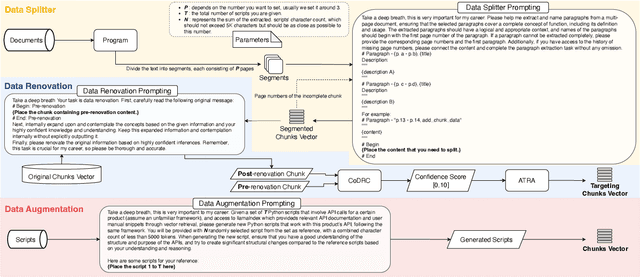


Our paper investigates effective methods for code generation in "specific-domain" applications, including the use of Large Language Models (LLMs) for data segmentation and renewal, as well as stimulating deeper thinking in LLMs through prompt adjustments. Using a real company product as an example, we provide user manuals, API documentation, and other data. The ideas discussed in this paper help segment and then convert this data into semantic vectors to better reflect their true positioning. Subsequently, user requirements are transformed into vectors to retrieve the most relevant content, achieving about 70% accuracy in simple to medium-complexity tasks through various prompt techniques. This paper is the first to enhance specific-domain code generation effectiveness from this perspective. Additionally, we experiment with generating more scripts from a limited number using llama2-based fine-tuning to test its effectiveness in professional domain code generation. This is a challenging and promising field, and once achieved, it will not only lead to breakthroughs in LLM development across multiple industries but also enable LLMs to understand and learn any new knowledge effectively.