 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApplications of Large Language Models in Data Processing: Innovative Approaches to Segmenting and Renewing Information
Nov 27, 2023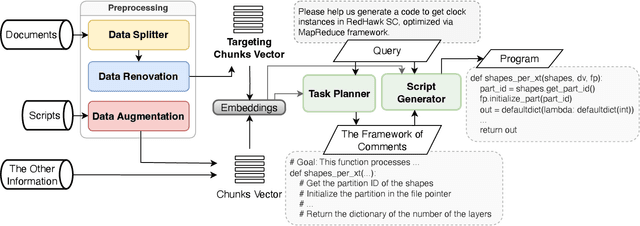
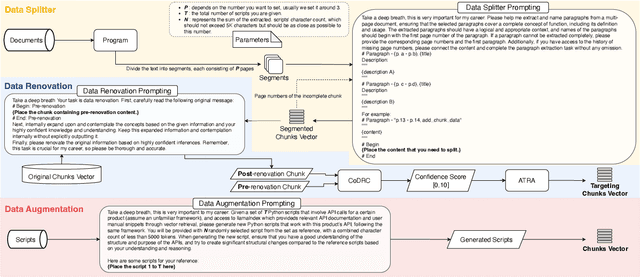


Our paper investigates effective methods for code generation in "specific-domain" applications, including the use of Large Language Models (LLMs) for data segmentation and renewal, as well as stimulating deeper thinking in LLMs through prompt adjustments. Using a real company product as an example, we provide user manuals, API documentation, and other data. The ideas discussed in this paper help segment and then convert this data into semantic vectors to better reflect their true positioning. Subsequently, user requirements are transformed into vectors to retrieve the most relevant content, achieving about 70% accuracy in simple to medium-complexity tasks through various prompt techniques. This paper is the first to enhance specific-domain code generation effectiveness from this perspective. Additionally, we experiment with generating more scripts from a limited number using llama2-based fine-tuning to test its effectiveness in professional domain code generation. This is a challenging and promising field, and once achieved, it will not only lead to breakthroughs in LLM development across multiple industries but also enable LLMs to understand and learn any new knowledge effectively.
Diffusion model based data generation for partial differential equations
Jun 19, 2023



In a preliminary attempt to address the problem of data scarcity in physics-based machine learning, we introduce a novel methodology for data generation in physics-based simulations. Our motivation is to overcome the limitations posed by the limited availability of numerical data. To achieve this, we leverage a diffusion model that allows us to generate synthetic data samples and test them for two canonical cases: (a) the steady 2-D Poisson equation, and (b) the forced unsteady 2-D Navier-Stokes (NS) {vorticity-transport} equation in a confined box. By comparing the generated data samples against outputs from classical solvers, we assess their accuracy and examine their adherence to the underlying physics laws. In this way, we emphasize the importance of not only satisfying visual and statistical comparisons with solver data but also ensuring the generated data's conformity to physics laws, thus enabling their effective utilization in downstream tasks.
Systematic Analysis of Image Generation using GANs
Aug 30, 2019

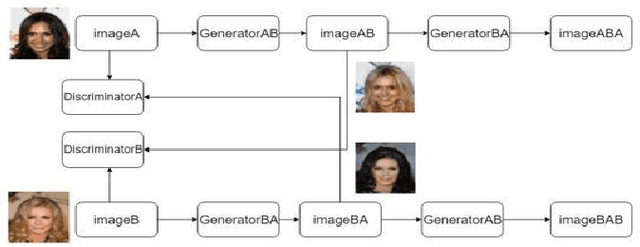

Generative Adversarial Networks have been crucial in the developments made in unsupervised learning in recent times. Exemplars of image synthesis from text or other images, these networks have shown remarkable improvements over conventional methods in terms of performance. Trained on the adversarial training philosophy, these networks aim to estimate the potential distribution from the real data and then use this as input to generate the synthetic data. Based on this fundamental principle, several frameworks can be generated that are paragon implementations in several real-life applications such as art synthesis, generation of high resolution outputs and synthesis of images from human drawn sketches, to name a few. While theoretically GANs present better results and prove to be an improvement over conventional methods in many factors, the implementation of these frameworks for dedicated applications remains a challenge. This study explores and presents a taxonomy of these frameworks and their use in various image to image synthesis and text to image synthesis applications. The basic GANs, as well as a variety of different niche frameworks, are critically analyzed. The advantages of GANs for image generation over conventional methods as well their disadvantages amongst other frameworks are presented. The future applications of GANs in industries such as healthcare, art and entertainment are also discussed.