 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRDPN6D: Residual-based Dense Point-wise Network for 6Dof Object Pose Estimation Based on RGB-D Images
May 14, 2024

In this work, we introduce a novel method for calculating the 6DoF pose of an object using a single RGB-D image. Unlike existing methods that either directly predict objects' poses or rely on sparse keypoints for pose recovery, our approach addresses this challenging task using dense correspondence, i.e., we regress the object coordinates for each visible pixel. Our method leverages existing object detection methods. We incorporate a re-projection mechanism to adjust the camera's intrinsic matrix to accommodate cropping in RGB-D images. Moreover, we transform the 3D object coordinates into a residual representation, which can effectively reduce the output space and yield superior performance. We conducted extensive experiments to validate the efficacy of our approach for 6D pose estimation. Our approach outperforms most previous methods, especially in occlusion scenarios, and demonstrates notable improvements over the state-of-the-art methods. Our code is available on https://github.com/AI-Application-and-Integration-Lab/RDPN6D.
Improving Facial Landmark Detection Accuracy and Efficiency with Knowledge Distillation
Apr 09, 2024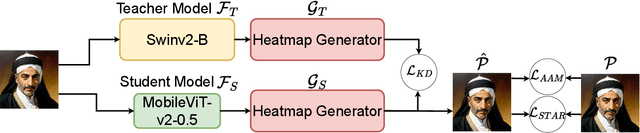

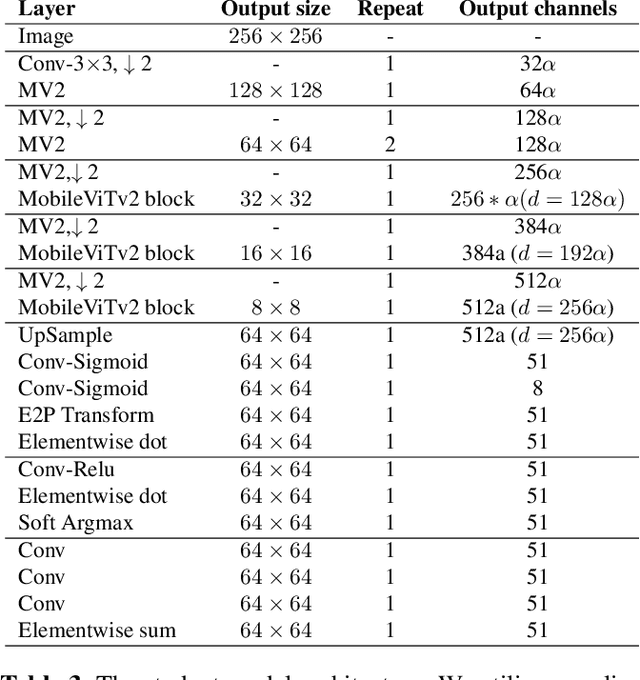
The domain of computer vision has experienced significant advancements in facial-landmark detection, becoming increasingly essential across various applications such as augmented reality, facial recognition, and emotion analysis. Unlike object detection or semantic segmentation, which focus on identifying objects and outlining boundaries, faciallandmark detection aims to precisely locate and track critical facial features. However, deploying deep learning-based facial-landmark detection models on embedded systems with limited computational resources poses challenges due to the complexity of facial features, especially in dynamic settings. Additionally, ensuring robustness across diverse ethnicities and expressions presents further obstacles. Existing datasets often lack comprehensive representation of facial nuances, particularly within populations like those in Taiwan. This paper introduces a novel approach to address these challenges through the development of a knowledge distillation method. By transferring knowledge from larger models to smaller ones, we aim to create lightweight yet powerful deep learning models tailored specifically for facial-landmark detection tasks. Our goal is to design models capable of accurately locating facial landmarks under varying conditions, including diverse expressions, orientations, and lighting environments. The ultimate objective is to achieve high accuracy and real-time performance suitable for deployment on embedded systems. This method was successfully implemented and achieved a top 6th place finish out of 165 participants in the IEEE ICME 2024 PAIR competition.
Domain-Generalized Face Anti-Spoofing with Unknown Attacks
Oct 18, 2023



Although face anti-spoofing (FAS) methods have achieved remarkable performance on specific domains or attack types, few studies have focused on the simultaneous presence of domain changes and unknown attacks, which is closer to real application scenarios. To handle domain-generalized unknown attacks, we introduce a new method, DGUA-FAS, which consists of a Transformer-based feature extractor and a synthetic unknown attack sample generator (SUASG). The SUASG network simulates unknown attack samples to assist the training of the feature extractor. Experimental results show that our method achieves superior performance on domain generalization FAS with known or unknown attacks.