 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpanding the Role of Diffusion Models for Robust Classifier Training
Feb 23, 2026Incorporating diffusion-generated synthetic data into adversarial training (AT) has been shown to substantially improve the training of robust image classifiers. In this work, we extend the role of diffusion models beyond merely generating synthetic data, examining whether their internal representations, which encode meaningful features of the data, can provide additional benefits for robust classifier training. Through systematic experiments, we show that diffusion models offer representations that are both diverse and partially robust, and that explicitly incorporating diffusion representations as an auxiliary learning signal during AT consistently improves robustness across settings. Furthermore, our representation analysis indicates that incorporating diffusion models into AT encourages more disentangled features, while diffusion representations and diffusion-generated synthetic data play complementary roles in shaping representations. Experiments on CIFAR-10, CIFAR-100, and ImageNet validate these findings, demonstrating the effectiveness of jointly leveraging diffusion representations and synthetic data within AT.
libcll: an Extendable Python Toolkit for Complementary-Label Learning
Nov 19, 2024
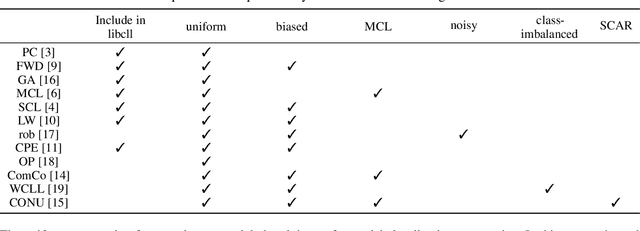


Complementary-label learning (CLL) is a weakly supervised learning paradigm for multiclass classification, where only complementary labels -- indicating classes an instance does not belong to -- are provided to the learning algorithm. Despite CLL's increasing popularity, previous studies highlight two main challenges: (1) inconsistent results arising from varied assumptions on complementary label generation, and (2) high barriers to entry due to the lack of a standardized evaluation platform across datasets and algorithms. To address these challenges, we introduce \texttt{libcll}, an extensible Python toolkit for CLL research. \texttt{libcll} provides a universal interface that supports a wide range of generation assumptions, both synthetic and real-world datasets, and key CLL algorithms. The toolkit is designed to mitigate inconsistencies and streamline the research process, with easy installation, comprehensive usage guides, and quickstart tutorials that facilitate efficient adoption and implementation of CLL techniques. Extensive ablation studies conducted with \texttt{libcll} demonstrate its utility in generating valuable insights to advance future CLL research.
MAX: Masked Autoencoder for X-ray Fluorescence in Geological Investigation
Oct 16, 2024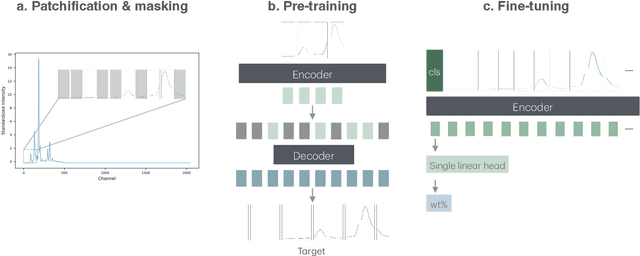
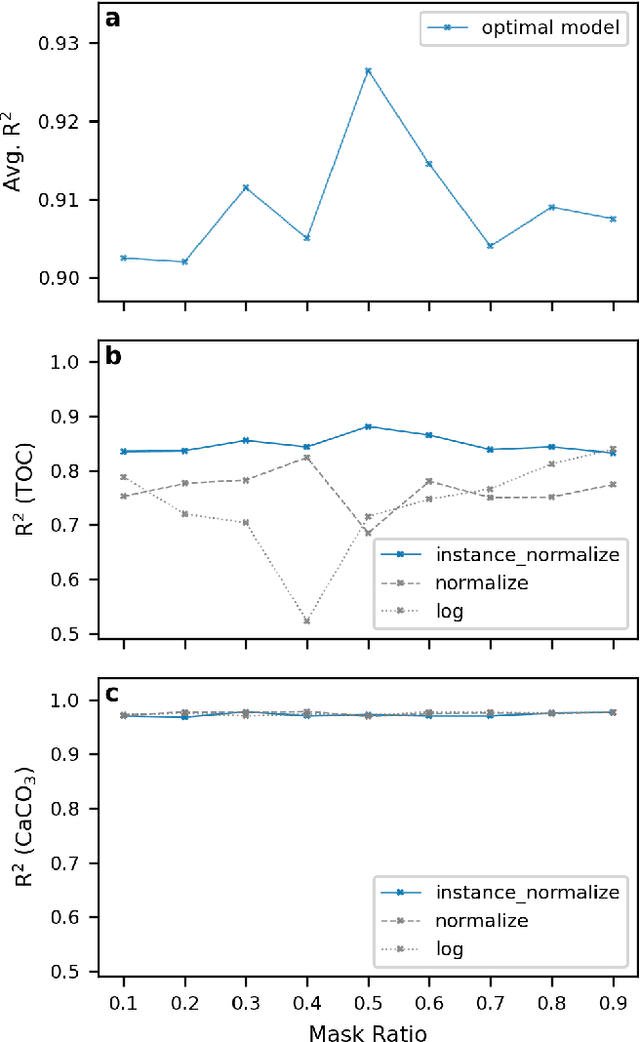
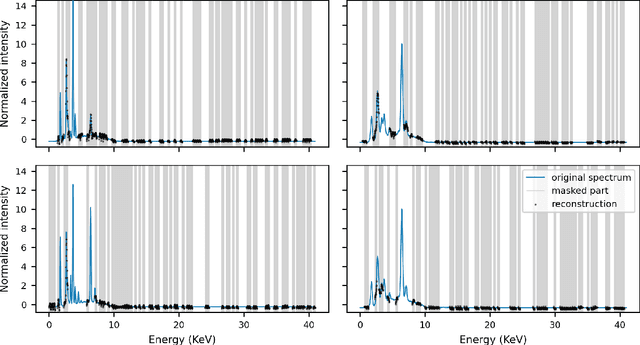
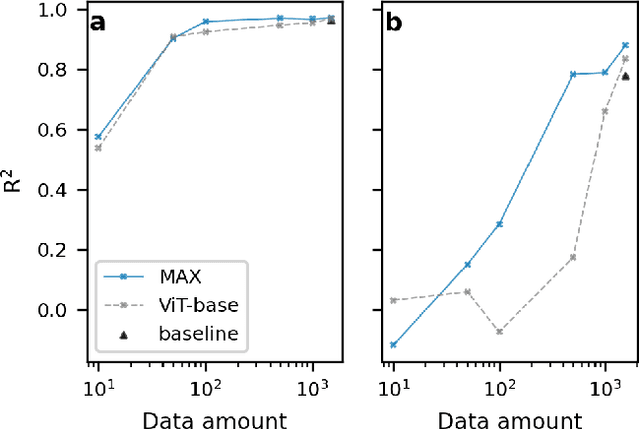
Pre-training foundation models has become the de-facto procedure for deep learning approaches, yet its application remains limited in the geological studies, where in needs of the model transferability to break the shackle of data scarcity. Here we target on the X-ray fluorescence (XRF) scanning data, a standard high-resolution measurement in extensive scientific drilling projects. We propose a scalable self-supervised learner, masked autoencoders on XRF spectra (MAX), to pre-train a foundation model covering geological records from multiple regions of the Pacific and Southern Ocean. In pre-training, we find that masking a high proportion of the input spectrum (50\%) yields a nontrivial and meaningful self-supervisory task. For downstream tasks, we select the quantification of XRF spectra into two costly geochemical measurements, CaCO$_3$ and total organic carbon, due to their importance in understanding the paleo-oceanic carbon system. Our results show that MAX, requiring only one-third of the data, outperforms models without pre-training in terms of quantification accuracy. Additionally, the model's generalizability improves by more than 60\% in zero-shot tests on new materials, with explainability further ensuring its robustness. Thus, our approach offers a promising pathway to overcome data scarcity in geological discovery by leveraging the self-supervised foundation model and fast-acquired XRF scanning data.
Reducing Source-Private Bias in Extreme Universal Domain Adaptation
Oct 15, 2024Universal Domain Adaptation (UniDA) aims to transfer knowledge from a labeled source domain to an unlabeled target domain without assuming how much the label-sets of the two domains intersect. The goal of UniDA is to achieve robust performance on the target domain across different intersection levels. However, existing literature has not sufficiently explored performance under extreme intersection levels. Our experiments reveal that state-of-the-art methods struggle when the source domain has significantly more non-overlapping classes than overlapping ones, a setting we refer to as Extreme UniDA. In this paper, we demonstrate that classical partial domain alignment, which focuses on aligning only overlapping-class data between domains, is limited in mitigating the bias of feature extractors toward source-private classes in extreme UniDA scenarios. We argue that feature extractors trained with source supervised loss distort the intrinsic structure of the target data due to the inherent differences between source-private classes and the target data. To mitigate this bias, we propose using self-supervised learning to preserve the structure of the target data. Our approach can be easily integrated into existing frameworks. We apply the proposed approach to two distinct training paradigms-adversarial-based and optimal-transport-based-and show consistent improvements across various intersection levels, with significant gains in extreme UniDA settings.
TableRAG: Million-Token Table Understanding with Language Models
Oct 07, 2024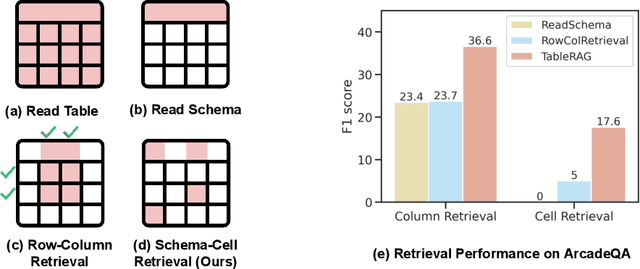
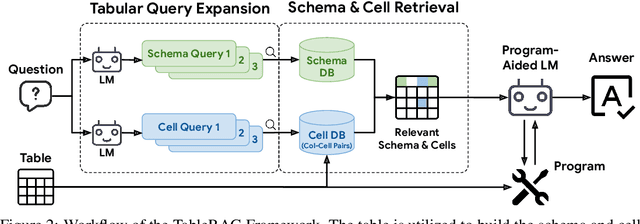
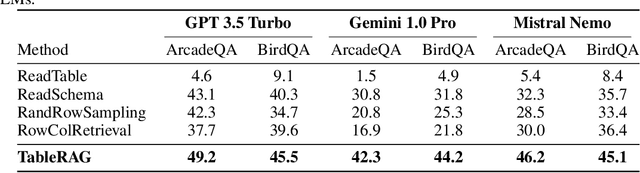
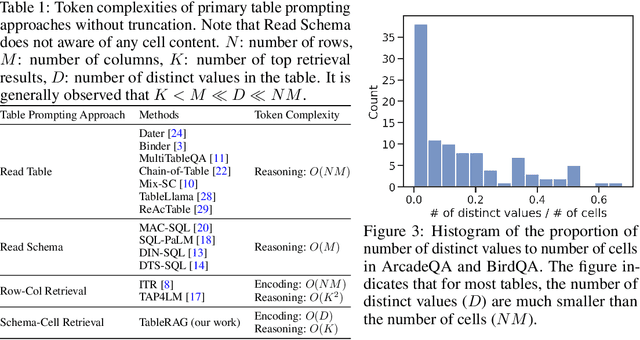
Recent advancements in language models (LMs) have notably enhanced their ability to reason with tabular data, primarily through program-aided mechanisms that manipulate and analyze tables. However, these methods often require the entire table as input, leading to scalability challenges due to the positional bias or context length constraints. In response to these challenges, we introduce TableRAG, a Retrieval-Augmented Generation (RAG) framework specifically designed for LM-based table understanding. TableRAG leverages query expansion combined with schema and cell retrieval to pinpoint crucial information before providing it to the LMs. This enables more efficient data encoding and precise retrieval, significantly reducing prompt lengths and mitigating information loss. We have developed two new million-token benchmarks from the Arcade and BIRD-SQL datasets to thoroughly evaluate TableRAG's effectiveness at scale. Our results demonstrate that TableRAG's retrieval design achieves the highest retrieval quality, leading to the new state-of-the-art performance on large-scale table understanding.
Defending Text-to-image Diffusion Models: Surprising Efficacy of Textual Perturbations Against Backdoor Attacks
Aug 28, 2024Text-to-image diffusion models have been widely adopted in real-world applications due to their ability to generate realistic images from textual descriptions. However, recent studies have shown that these methods are vulnerable to backdoor attacks. Despite the significant threat posed by backdoor attacks on text-to-image diffusion models, countermeasures remain under-explored. In this paper, we address this research gap by demonstrating that state-of-the-art backdoor attacks against text-to-image diffusion models can be effectively mitigated by a surprisingly simple defense strategy - textual perturbation. Experiments show that textual perturbations are effective in defending against state-of-the-art backdoor attacks with minimal sacrifice to generation quality. We analyze the efficacy of textual perturbation from two angles: text embedding space and cross-attention maps. They further explain how backdoor attacks have compromised text-to-image diffusion models, providing insights for studying future attack and defense strategies. Our code is available at https://github.com/oscarchew/t2i-backdoor-defense.
SLIM: Spuriousness Mitigation with Minimal Human Annotations
Jul 08, 2024
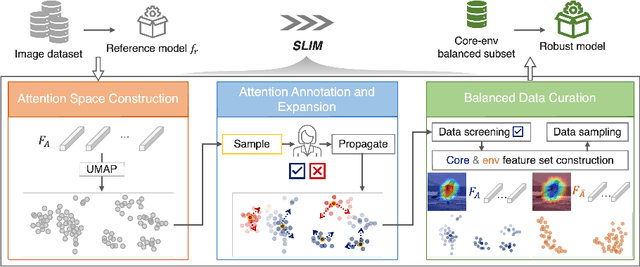
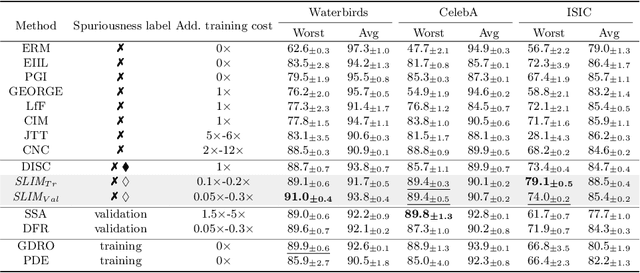

Recent studies highlight that deep learning models often learn spurious features mistakenly linked to labels, compromising their reliability in real-world scenarios where such correlations do not hold. Despite the increasing research effort, existing solutions often face two main challenges: they either demand substantial annotations of spurious attributes, or they yield less competitive outcomes with expensive training when additional annotations are absent. In this paper, we introduce SLIM, a cost-effective and performance-targeted approach to reducing spurious correlations in deep learning. Our method leverages a human-in-the-loop protocol featuring a novel attention labeling mechanism with a constructed attention representation space. SLIM significantly reduces the need for exhaustive additional labeling, requiring human input for fewer than 3% of instances. By prioritizing data quality over complicated training strategies, SLIM curates a smaller yet more feature-balanced data subset, fostering the development of spuriousness-robust models. Experimental validations across key benchmarks demonstrate that SLIM competes with or exceeds the performance of leading methods while significantly reducing costs. The SLIM framework thus presents a promising path for developing reliable models more efficiently. Our code is available in https://github.com/xiweix/SLIM.git/.
CAD-DA: Controllable Anomaly Detection after Domain Adaptation by Statistical Inference
Oct 23, 2023We propose a novel statistical method for testing the results of anomaly detection (AD) under domain adaptation (DA), which we call CAD-DA -- controllable AD under DA. The distinct advantage of the CAD-DA lies in its ability to control the probability of misidentifying anomalies under a pre-specified level $\alpha$ (e.g., 0.05). The challenge within this DA setting is the necessity to account for the influence of DA to ensure the validity of the inference results. Our solution to this challenge leverages the concept of conditional Selective Inference to handle the impact of DA. To our knowledge, this is the first work capable of conducting a valid statistical inference within the context of DA. We evaluate the performance of the CAD-DA method on both synthetic and real-world datasets.
From SMOTE to Mixup for Deep Imbalanced Classification
Aug 29, 2023Given imbalanced data, it is hard to train a good classifier using deep learning because of the poor generalization of minority classes. Traditionally, the well-known synthetic minority oversampling technique (SMOTE) for data augmentation, a data mining approach for imbalanced learning, has been used to improve this generalization. However, it is unclear whether SMOTE also benefits deep learning. In this work, we study why the original SMOTE is insufficient for deep learning, and enhance SMOTE using soft labels. Connecting the resulting soft SMOTE with Mixup, a modern data augmentation technique, leads to a unified framework that puts traditional and modern data augmentation techniques under the same umbrella. A careful study within this framework shows that Mixup improves generalization by implicitly achieving uneven margins between majority and minority classes. We then propose a novel margin-aware Mixup technique that more explicitly achieves uneven margins. Extensive experimental results demonstrate that our proposed technique yields state-of-the-art performance on deep imbalanced classification while achieving superior performance on extremely imbalanced data. The code is open-sourced in our developed package https://github.com/ntucllab/imbalanced-DL to foster future research in this direction.
Score-based Conditional Generation with Fewer Labeled Data by Self-calibrating Classifier Guidance
Jul 09, 2023Score-based Generative Models (SGMs) are a popular family of deep generative models that achieves leading image generation quality. Earlier studies have extended SGMs to tackle class-conditional generation by coupling an unconditional SGM with the guidance of a trained classifier. Nevertheless, such classifier-guided SGMs do not always achieve accurate conditional generation, especially when trained with fewer labeled data. We argue that the issue is rooted in unreliable gradients of the classifier and the inability to fully utilize unlabeled data during training. We then propose to improve classifier-guided SGMs by letting the classifier calibrate itself. Our key idea is to use principles from energy-based models to convert the classifier as another view of the unconditional SGM. Then, existing loss for the unconditional SGM can be adopted to calibrate the classifier using both labeled and unlabeled data. Empirical results validate that the proposed approach significantly improves the conditional generation quality across different percentages of labeled data. The improved performance makes the proposed approach consistently superior to other conditional SGMs when using fewer labeled data. The results confirm the potential of the proposed approach for generative modeling with limited labeled data.