 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgelibcll: an Extendable Python Toolkit for Complementary-Label Learning
Paper and Code

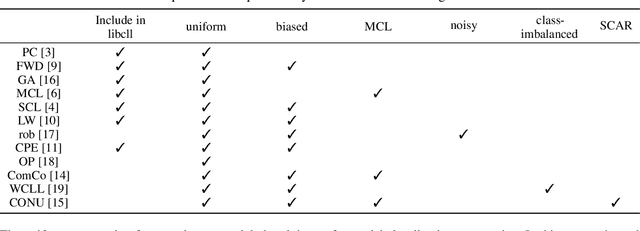


Complementary-label learning (CLL) is a weakly supervised learning paradigm for multiclass classification, where only complementary labels -- indicating classes an instance does not belong to -- are provided to the learning algorithm. Despite CLL's increasing popularity, previous studies highlight two main challenges: (1) inconsistent results arising from varied assumptions on complementary label generation, and (2) high barriers to entry due to the lack of a standardized evaluation platform across datasets and algorithms. To address these challenges, we introduce \texttt{libcll}, an extensible Python toolkit for CLL research. \texttt{libcll} provides a universal interface that supports a wide range of generation assumptions, both synthetic and real-world datasets, and key CLL algorithms. The toolkit is designed to mitigate inconsistencies and streamline the research process, with easy installation, comprehensive usage guides, and quickstart tutorials that facilitate efficient adoption and implementation of CLL techniques. Extensive ablation studies conducted with \texttt{libcll} demonstrate its utility in generating valuable insights to advance future CLL research.