 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe ML-SUPERB 2.0 Challenge: Towards Inclusive ASR Benchmarking for All Language Varieties
Sep 08, 2025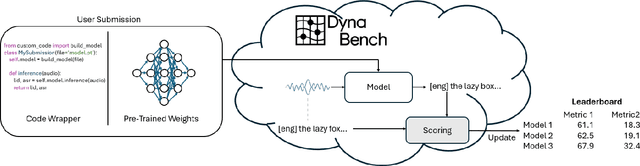
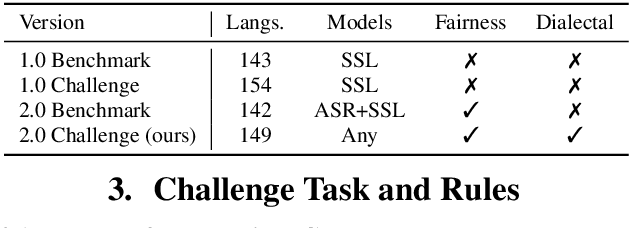
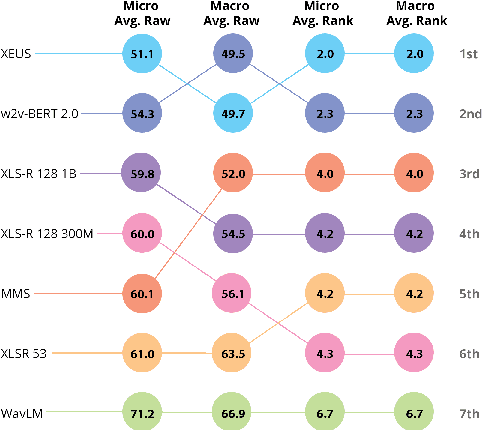
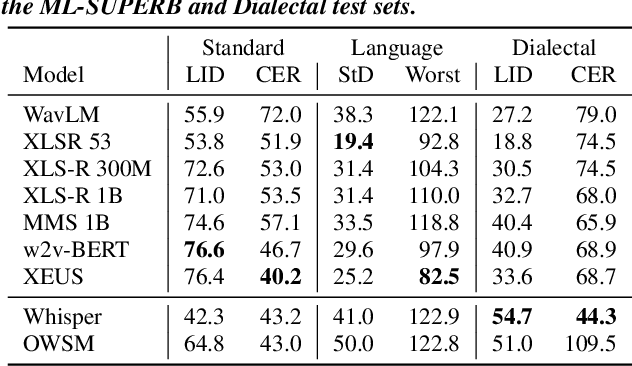
Recent improvements in multilingual ASR have not been equally distributed across languages and language varieties. To advance state-of-the-art (SOTA) ASR models, we present the Interspeech 2025 ML-SUPERB 2.0 Challenge. We construct a new test suite that consists of data from 200+ languages, accents, and dialects to evaluate SOTA multilingual speech models. The challenge also introduces an online evaluation server based on DynaBench, allowing for flexibility in model design and architecture for participants. The challenge received 5 submissions from 3 teams, all of which outperformed our baselines. The best-performing submission achieved an absolute improvement in LID accuracy of 23% and a reduction in CER of 18% when compared to the best baseline on a general multilingual test set. On accented and dialectal data, the best submission obtained 30.2% lower CER and 15.7% higher LID accuracy, showing the importance of community challenges in making speech technologies more inclusive.
libcll: an Extendable Python Toolkit for Complementary-Label Learning
Nov 19, 2024
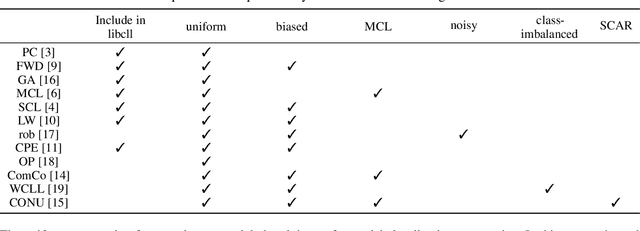


Complementary-label learning (CLL) is a weakly supervised learning paradigm for multiclass classification, where only complementary labels -- indicating classes an instance does not belong to -- are provided to the learning algorithm. Despite CLL's increasing popularity, previous studies highlight two main challenges: (1) inconsistent results arising from varied assumptions on complementary label generation, and (2) high barriers to entry due to the lack of a standardized evaluation platform across datasets and algorithms. To address these challenges, we introduce \texttt{libcll}, an extensible Python toolkit for CLL research. \texttt{libcll} provides a universal interface that supports a wide range of generation assumptions, both synthetic and real-world datasets, and key CLL algorithms. The toolkit is designed to mitigate inconsistencies and streamline the research process, with easy installation, comprehensive usage guides, and quickstart tutorials that facilitate efficient adoption and implementation of CLL techniques. Extensive ablation studies conducted with \texttt{libcll} demonstrate its utility in generating valuable insights to advance future CLL research.
Building a Taiwanese Mandarin Spoken Language Model: A First Attempt
Nov 11, 2024



This technical report presents our initial attempt to build a spoken large language model (LLM) for Taiwanese Mandarin, specifically tailored to enable real-time, speech-to-speech interaction in multi-turn conversations. Our end-to-end model incorporates a decoder-only transformer architecture and aims to achieve seamless interaction while preserving the conversational flow, including full-duplex capabilities allowing simultaneous speaking and listening. The paper also details the training process, including data preparation with synthesized dialogues and adjustments for real-time interaction. We also developed a platform to evaluate conversational fluency and response coherence in multi-turn dialogues. We hope the release of the report can contribute to the future development of spoken LLMs in Taiwanese Mandarin.
Investigating the Effects of Large-Scale Pseudo-Stereo Data and Different Speech Foundation Model on Dialogue Generative Spoken Language Model
Jul 02, 2024


Recent efforts in Spoken Dialogue Modeling aim to synthesize spoken dialogue without the need for direct transcription, thereby preserving the wealth of non-textual information inherent in speech. However, this approach faces a challenge when speakers talk simultaneously, requiring stereo dialogue data with speakers recorded on separate channels, a notably scarce resource. To address this, we have developed an innovative pipeline capable of transforming single-channel dialogue data into pseudo-stereo data. This expanded our training dataset from a mere 2,000 to an impressive 17,600 hours, significantly enriching the diversity and quality of the training examples available. The inclusion of this pseudo-stereo data has proven to be effective in improving the performance of spoken dialogue language models. Additionally, we explored the use of discrete units of different speech foundation models for spoken dialogue generation.
Codec-SUPERB: An In-Depth Analysis of Sound Codec Models
Feb 20, 2024
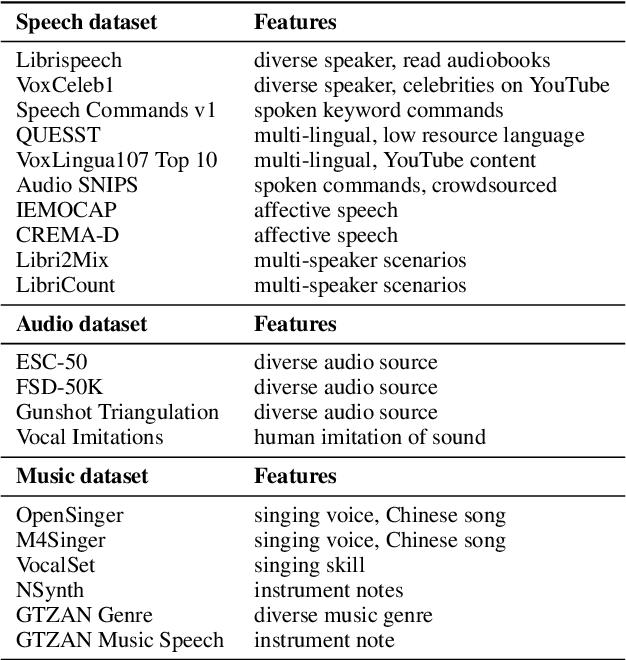
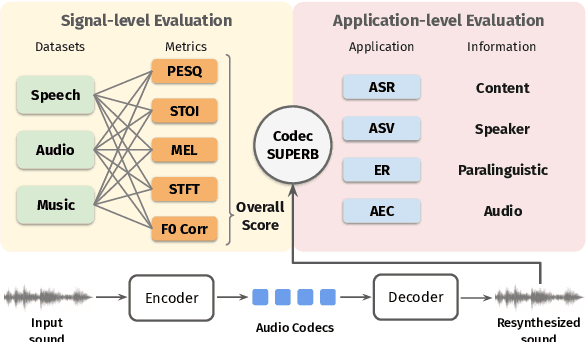
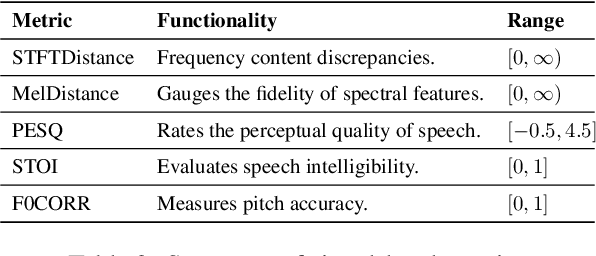
The sound codec's dual roles in minimizing data transmission latency and serving as tokenizers underscore its critical importance. Recent years have witnessed significant developments in codec models. The ideal sound codec should preserve content, paralinguistics, speakers, and audio information. However, the question of which codec achieves optimal sound information preservation remains unanswered, as in different papers, models are evaluated on their selected experimental settings. This study introduces Codec-SUPERB, an acronym for Codec sound processing Universal PERformance Benchmark. It is an ecosystem designed to assess codec models across representative sound applications and signal-level metrics rooted in sound domain knowledge.Codec-SUPERB simplifies result sharing through an online leaderboard, promoting collaboration within a community-driven benchmark database, thereby stimulating new development cycles for codecs. Furthermore, we undertake an in-depth analysis to offer insights into codec models from both application and signal perspectives, diverging from previous codec papers mainly concentrating on signal-level comparisons. Finally, we will release codes, the leaderboard, and data to accelerate progress within the community.
Findings of the 2023 ML-SUPERB Challenge: Pre-Training and Evaluation over More Languages and Beyond
Oct 09, 2023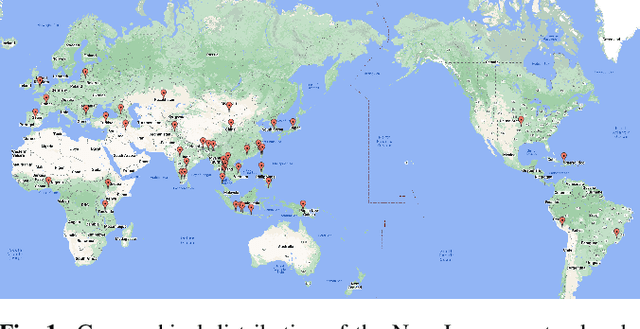

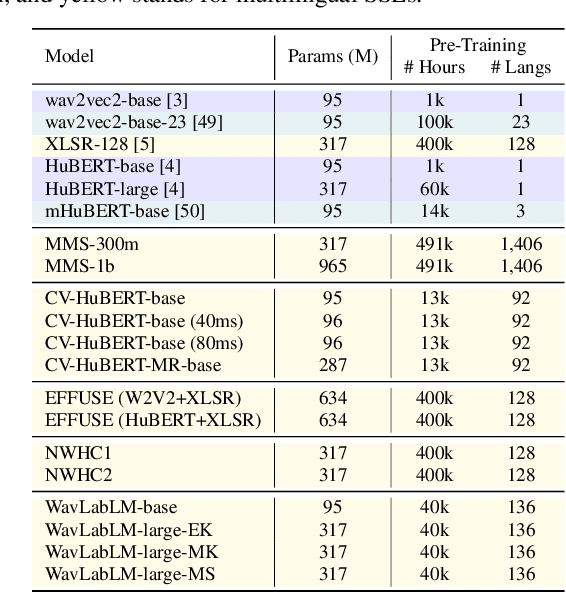
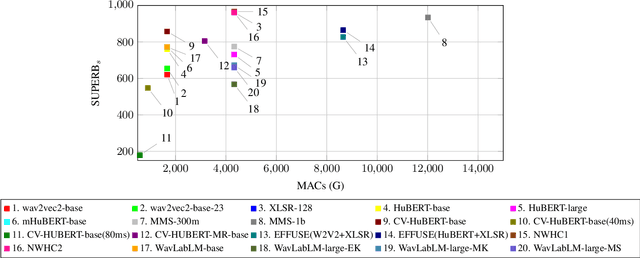
The 2023 Multilingual Speech Universal Performance Benchmark (ML-SUPERB) Challenge expands upon the acclaimed SUPERB framework, emphasizing self-supervised models in multilingual speech recognition and language identification. The challenge comprises a research track focused on applying ML-SUPERB to specific multilingual subjects, a Challenge Track for model submissions, and a New Language Track where language resource researchers can contribute and evaluate their low-resource language data in the context of the latest progress in multilingual speech recognition. The challenge garnered 12 model submissions and 54 language corpora, resulting in a comprehensive benchmark encompassing 154 languages. The findings indicate that merely scaling models is not the definitive solution for multilingual speech tasks, and a variety of speech/voice types present significant challenges in multilingual speech processing.
Exploring Speech Recognition, Translation, and Understanding with Discrete Speech Units: A Comparative Study
Sep 27, 2023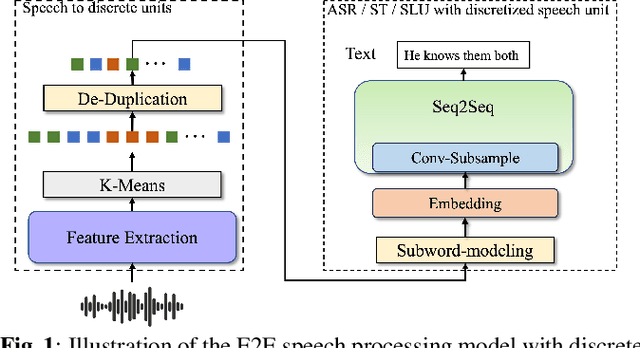
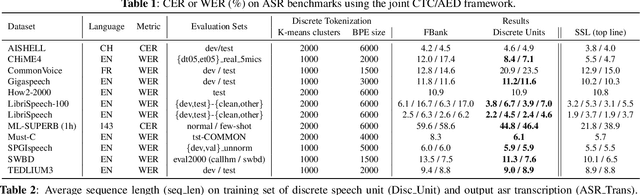
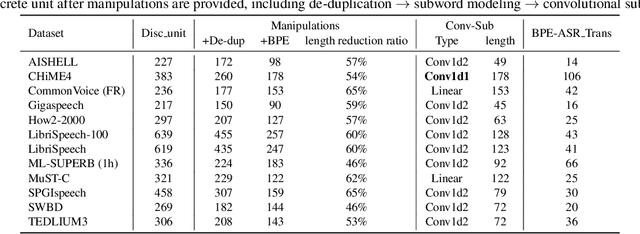
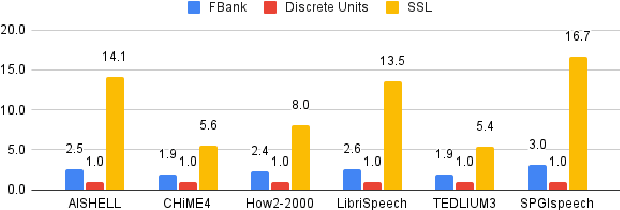
Speech signals, typically sampled at rates in the tens of thousands per second, contain redundancies, evoking inefficiencies in sequence modeling. High-dimensional speech features such as spectrograms are often used as the input for the subsequent model. However, they can still be redundant. Recent investigations proposed the use of discrete speech units derived from self-supervised learning representations, which significantly compresses the size of speech data. Applying various methods, such as de-duplication and subword modeling, can further compress the speech sequence length. Hence, training time is significantly reduced while retaining notable performance. In this study, we undertake a comprehensive and systematic exploration into the application of discrete units within end-to-end speech processing models. Experiments on 12 automatic speech recognition, 3 speech translation, and 1 spoken language understanding corpora demonstrate that discrete units achieve reasonably good results in almost all the settings. We intend to release our configurations and trained models to foster future research efforts.
CLCIFAR: CIFAR-Derived Benchmark Datasets with Human Annotated Complementary Labels
May 15, 2023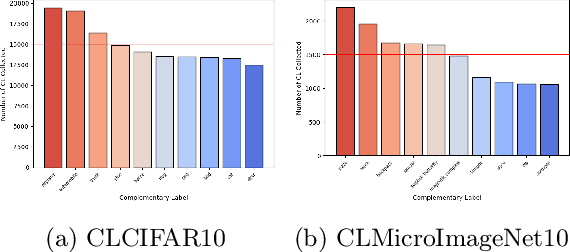
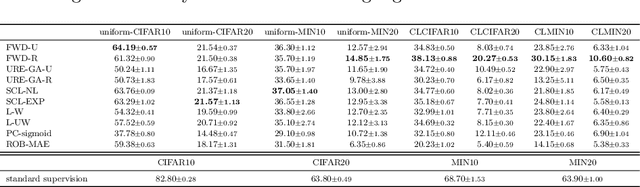
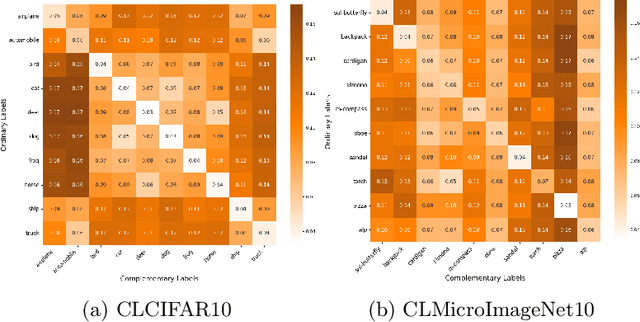
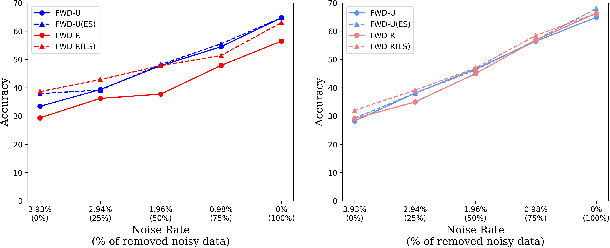
As a weakly-supervised learning paradigm, complementary label learning (CLL) aims to learn a multi-class classifier from only complementary labels, classes to which an instance does not belong. Despite various studies have addressed how to learn from CLL, those methods typically rely on some distributional assumptions on the complementary labels, and are benchmarked only on some synthetic datasets. It remains unclear how the noise or bias arising from the human annotation process would affect those CLL algorithms. To fill the gap, we design a protocol to collect complementary labels annotated by human. Two datasets, CLCIFAR10 and CLCIFAR20, based on CIFAR10 and CIFAR100, respectively, are collected. We analyzed the empirical transition matrices of the collected datasets, and observed that they are noisy and biased. We then performed extensive benchmark experiments on the collected datasets with various CLL algorithms to validate whether the existing algorithms can learn from the real-world complementary datasets. The dataset can be accessed with the following link: https://github.com/ntucllab/complementary_cifar.