 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgelibcll: an Extendable Python Toolkit for Complementary-Label Learning
Nov 19, 2024
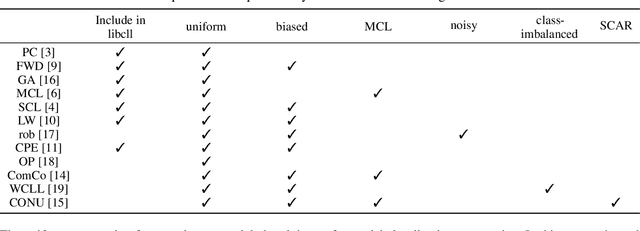


Complementary-label learning (CLL) is a weakly supervised learning paradigm for multiclass classification, where only complementary labels -- indicating classes an instance does not belong to -- are provided to the learning algorithm. Despite CLL's increasing popularity, previous studies highlight two main challenges: (1) inconsistent results arising from varied assumptions on complementary label generation, and (2) high barriers to entry due to the lack of a standardized evaluation platform across datasets and algorithms. To address these challenges, we introduce \texttt{libcll}, an extensible Python toolkit for CLL research. \texttt{libcll} provides a universal interface that supports a wide range of generation assumptions, both synthetic and real-world datasets, and key CLL algorithms. The toolkit is designed to mitigate inconsistencies and streamline the research process, with easy installation, comprehensive usage guides, and quickstart tutorials that facilitate efficient adoption and implementation of CLL techniques. Extensive ablation studies conducted with \texttt{libcll} demonstrate its utility in generating valuable insights to advance future CLL research.
CLCIFAR: CIFAR-Derived Benchmark Datasets with Human Annotated Complementary Labels
May 15, 2023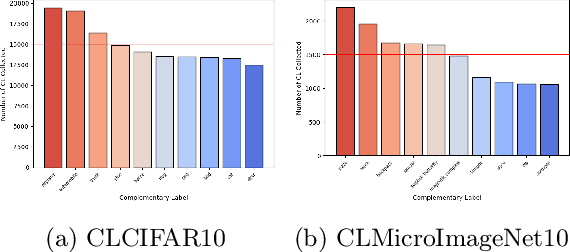
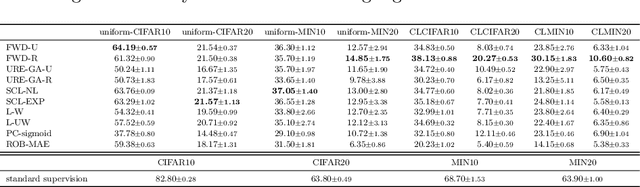
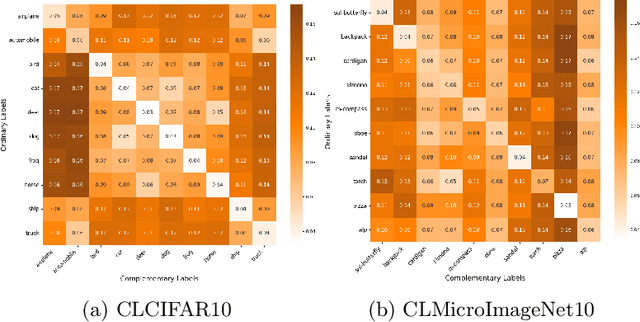
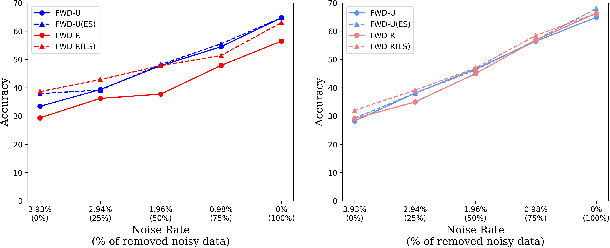
As a weakly-supervised learning paradigm, complementary label learning (CLL) aims to learn a multi-class classifier from only complementary labels, classes to which an instance does not belong. Despite various studies have addressed how to learn from CLL, those methods typically rely on some distributional assumptions on the complementary labels, and are benchmarked only on some synthetic datasets. It remains unclear how the noise or bias arising from the human annotation process would affect those CLL algorithms. To fill the gap, we design a protocol to collect complementary labels annotated by human. Two datasets, CLCIFAR10 and CLCIFAR20, based on CIFAR10 and CIFAR100, respectively, are collected. We analyzed the empirical transition matrices of the collected datasets, and observed that they are noisy and biased. We then performed extensive benchmark experiments on the collected datasets with various CLL algorithms to validate whether the existing algorithms can learn from the real-world complementary datasets. The dataset can be accessed with the following link: https://github.com/ntucllab/complementary_cifar.
Enhancing Label Sharing Efficiency in Complementary-Label Learning with Label Augmentation
May 15, 2023Complementary-label Learning (CLL) is a form of weakly supervised learning that trains an ordinary classifier using only complementary labels, which are the classes that certain instances do not belong to. While existing CLL studies typically use novel loss functions or training techniques to solve this problem, few studies focus on how complementary labels collectively provide information to train the ordinary classifier. In this paper, we fill the gap by analyzing the implicit sharing of complementary labels on nearby instances during training. Our analysis reveals that the efficiency of implicit label sharing is closely related to the performance of existing CLL models. Based on this analysis, we propose a novel technique that enhances the sharing efficiency via complementary-label augmentation, which explicitly propagates additional complementary labels to each instance. We carefully design the augmentation process to enrich the data with new and accurate complementary labels, which provide CLL models with fresh and valuable information to enhance the sharing efficiency. We then verify our proposed technique by conducting thorough experiments on both synthetic and real-world datasets. Our results confirm that complementary-label augmentation can systematically improve empirical performance over state-of-the-art CLL models.
Reduction from Complementary-Label Learning to Probability Estimates
Sep 20, 2022
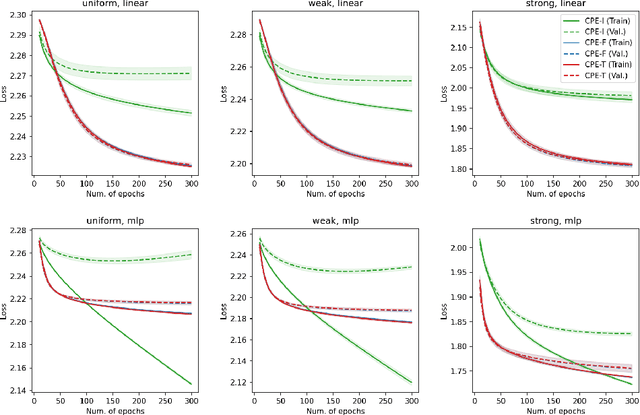

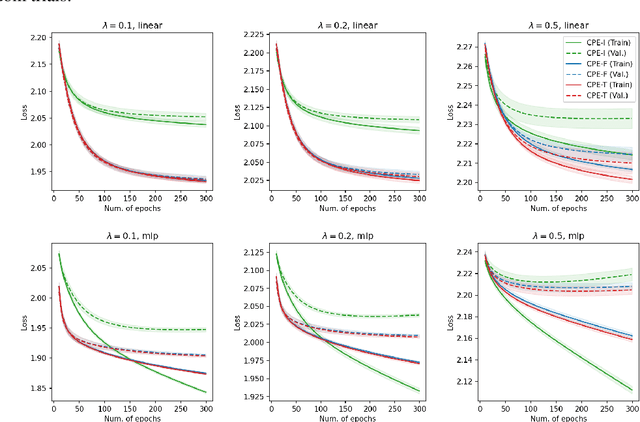
Complementary-Label Learning (CLL) is a weakly-supervised learning problem that aims to learn a multi-class classifier from only complementary labels, which indicate a class to which an instance does not belong. Existing approaches mainly adopt the paradigm of reduction to ordinary classification, which applies specific transformations and surrogate losses to connect CLL back to ordinary classification. Those approaches, however, face several limitations, such as the tendency to overfit or be hooked on deep models. In this paper, we sidestep those limitations with a novel perspective--reduction to probability estimates of complementary classes. We prove that accurate probability estimates of complementary labels lead to good classifiers through a simple decoding step. The proof establishes a reduction framework from CLL to probability estimates. The framework offers explanations of several key CLL approaches as its special cases and allows us to design an improved algorithm that is more robust in noisy environments. The framework also suggests a validation procedure based on the quality of probability estimates, leading to an alternative way to validate models with only complementary labels. The flexible framework opens a wide range of unexplored opportunities in using deep and non-deep models for probability estimates to solve the CLL problem. Empirical experiments further verified the framework's efficacy and robustness in various settings.
Active Refinement for Multi-Label Learning: A Pseudo-Label Approach
Sep 29, 2021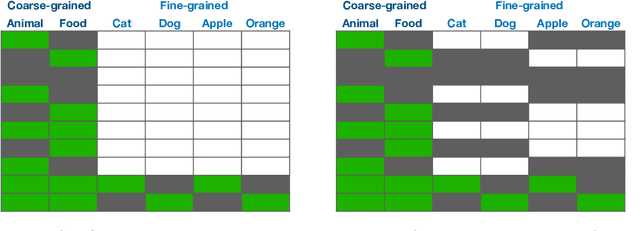
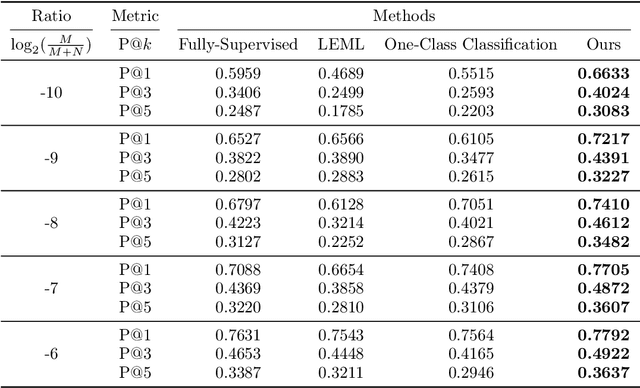
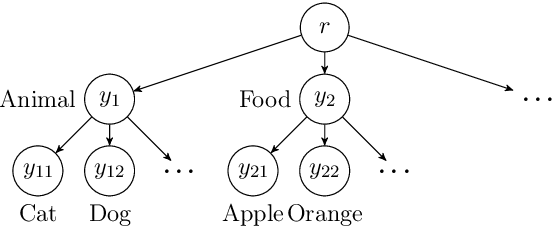
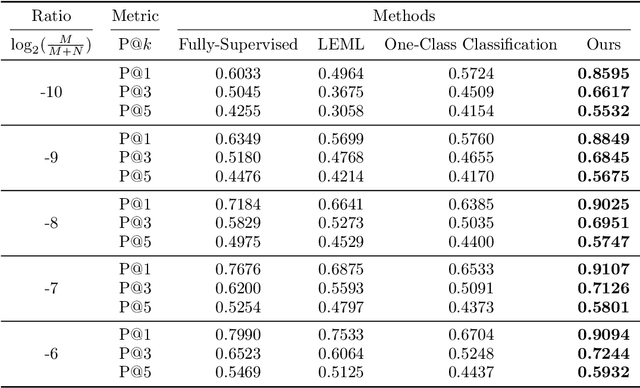
The goal of multi-label learning (MLL) is to associate a given instance with its relevant labels from a set of concepts. Previous works of MLL mainly focused on the setting where the concept set is assumed to be fixed, while many real-world applications require introducing new concepts into the set to meet new demands. One common need is to refine the original coarse concepts and split them into finer-grained ones, where the refinement process typically begins with limited labeled data for the finer-grained concepts. To address the need, we formalize the problem into a special weakly supervised MLL problem to not only learn the fine-grained concepts efficiently but also allow interactive queries to strategically collect more informative annotations to further improve the classifier. The key idea within our approach is to learn to assign pseudo-labels to the unlabeled entries, and in turn leverage the pseudo-labels to train the underlying classifier and to inform a better query strategy. Experimental results demonstrate that our pseudo-label approach is able to accurately recover the missing ground truth, boosting the prediction performance significantly over the baseline methods and facilitating a competitive active learning strategy.