 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerated Dynamic Importance Weighting with Versatile Divergence-Minimizing Estimators
May 25, 2026Importance weighting (IW) is a golden solver for joint distribution shift, where the joint distributions differ between the training and test data. To solve this problem, IW estimates test-to-training density ratios as importance weights and reweights the training losses accordingly. Recent advances in dynamic IW (DIW) integrate weight estimation into model training, enabling scalable IW for deep models and achieving strong performance on large modern datasets. Despite its promise, DIW remains limited in two aspects. First, it incurs substantial computational overhead by solving a kernel mean matching (KMM)-induced optimization problem to convergence in every mini-batch. Second, it relies solely on KMM for weight estimation, whereas the IW literature contains diverse estimation methods based on different divergence measures. In this paper, we propose accelerated DIW (ADIW), a unified and efficient IW framework for deep learning under joint distribution shift. ADIW performs a few lightweight projected gradient descent updates that warm-start from previously updated weights, substantially improving efficiency. Moreover, ADIW generalizes DIW into a unified divergence-minimization framework that supports diverse weight-estimation methods in a plug-and-play manner, including those based on the Kullback-Leibler divergence, squared distance, and Wasserstein-1 distance. We establish convergence guarantees for ADIW under mild conditions, and empirical results demonstrate that ADIW achieves state-of-the-art IW performance while being substantially more efficient.
Decomposing the Basic Abilities of Large Language Models: Mitigating Cross-Task Interference in Multi-Task Instruct-Tuning
May 07, 2026Recently, the prominent performance of large language models (LLMs) has been largely driven by multi-task instruct-tuning. Unfortunately, this training paradigm suffers from a key issue, named cross-task interference, due to conflicting gradients over shared parameters among different tasks. Some previous methods mitigate this issue by isolating task-specific parameters, e.g., task-specific neuron selection and mixture-of-experts. In this paper, we empirically reveal that the cross-task interference still exists for the existing solutions because of many parameters also shared by different tasks, and accordingly, we propose a novel solution, namely Basic Abilities Decomposition for multi-task Instruct-Tuning (BADIT). Specifically, we empirically find that certain parameters are consistently co-activated, and that co-activated parameters naturally organize into base groups. This motivates us to analogize that LLMs encode several orthogonal basic abilities, and that any task can be represented as a linear combination of these abilities. Accordingly, we propose BADIT that decomposes LLM parameters into orthogonal high-singular-value LoRA experts representing basic abilities, and dynamically enforces their orthogonality during training via spherical clustering of rank-1 components. We conduct extensive experiments on the SuperNI benchmark with 6 LLMs, and empirical results demonstrate that BADIT can outperform SOTA methods and mitigate the degree of cross-task interference.
Are Multimodal Large Language Models Good Annotators for Image Tagging?
Feb 24, 2026Image tagging, a fundamental vision task, traditionally relies on human-annotated datasets to train multi-label classifiers, which incurs significant labor and costs. While Multimodal Large Language Models (MLLMs) offer promising potential to automate annotation, their capability to replace human annotators remains underexplored. This paper aims to analyze the gap between MLLM-generated and human annotations and to propose an effective solution that enables MLLM-based annotation to replace manual labeling. Our analysis of MLLM annotations reveals that, under a conservative estimate, MLLMs can reduce annotation cost to as low as one-thousandth of the human cost, mainly accounting for GPU usage, which is nearly negligible compared to manual efforts. Their annotation quality reaches about 50\% to 80\% of human performance, while achieving over 90\% performance on downstream training tasks.Motivated by these findings, we propose TagLLM, a novel framework for image tagging, which aims to narrow the gap between MLLM-generated and human annotations. TagLLM comprises two components: Candidates generation, which employs structured group-wise prompting to efficiently produce a compact candidate set that covers as many true labels as possible while reducing subsequent annotation workload; and label disambiguation, which interactively calibrates the semantic concept of categories in the prompts and effectively refines the candidate labels. Extensive experiments show that TagLLM substantially narrows the gap between MLLM-generated and human annotations, especially in downstream training performance, where it closes about 60\% to 80\% of the difference.
BrokenBind: Universal Modality Exploration beyond Dataset Boundaries
Feb 06, 2026Multi-modal learning combines various modalities to provide a comprehensive understanding of real-world problems. A common strategy is to directly bind different modalities together in a specific joint embedding space. However, the capability of existing methods is restricted within the modalities presented in the given dataset, thus they are biased when generalizing to unpresented modalities in downstream tasks. As a result, due to such inflexibility, the viability of previous methods is seriously hindered by the cost of acquiring multi-modal datasets. In this paper, we introduce BrokenBind, which focuses on binding modalities that are presented from different datasets. To achieve this, BrokenBind simultaneously leverages multiple datasets containing the modalities of interest and one shared modality. Though the two datasets do not correspond to each other due to distribution mismatch, we can capture their relationship to generate pseudo embeddings to fill in the missing modalities of interest, enabling flexible and generalized multi-modal learning. Under our framework, any two modalities can be bound together, free from the dataset limitation, to achieve universal modality exploration. Further, to reveal the capability of our method, we study intensified scenarios where more than two datasets are needed for modality binding and show the effectiveness of BrokenBind in low-data regimes. Through extensive evaluation, we carefully justify the superiority of BrokenBind compared to well-known multi-modal baseline methods.
On the Role of Label Noise in the Feature Learning Process
May 25, 2025Deep learning with noisy labels presents significant challenges. In this work, we theoretically characterize the role of label noise from a feature learning perspective. Specifically, we consider a signal-noise data distribution, where each sample comprises a label-dependent signal and label-independent noise, and rigorously analyze the training dynamics of a two-layer convolutional neural network under this data setup, along with the presence of label noise. Our analysis identifies two key stages. In Stage I, the model perfectly fits all the clean samples (i.e., samples without label noise) while ignoring the noisy ones (i.e., samples with noisy labels). During this stage, the model learns the signal from the clean samples, which generalizes well on unseen data. In Stage II, as the training loss converges, the gradient in the direction of noise surpasses that of the signal, leading to overfitting on noisy samples. Eventually, the model memorizes the noise present in the noisy samples and degrades its generalization ability. Furthermore, our analysis provides a theoretical basis for two widely used techniques for tackling label noise: early stopping and sample selection. Experiments on both synthetic and real-world setups validate our theory.
Learning without Isolation: Pathway Protection for Continual Learning
May 24, 2025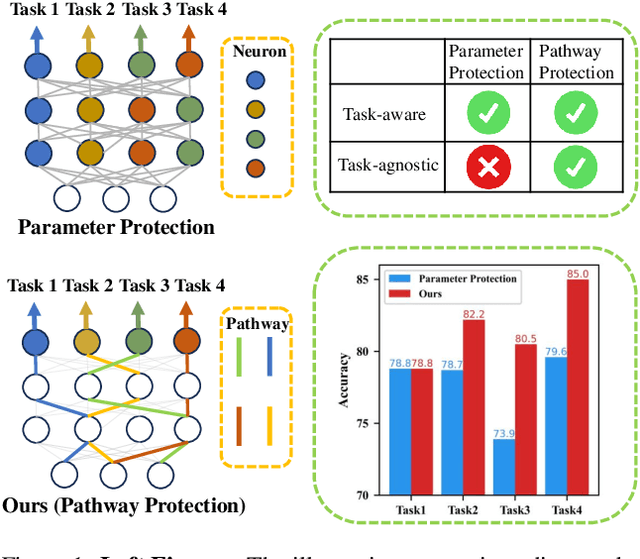
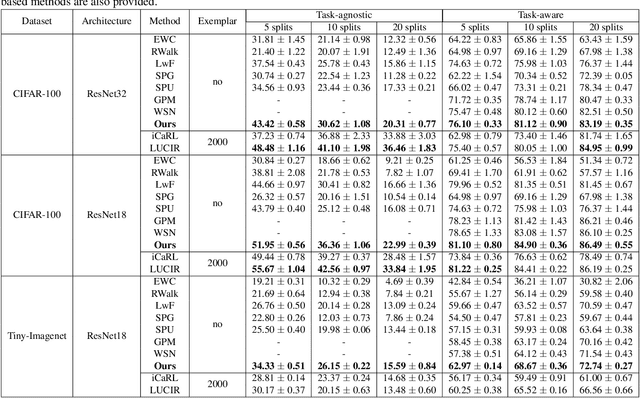
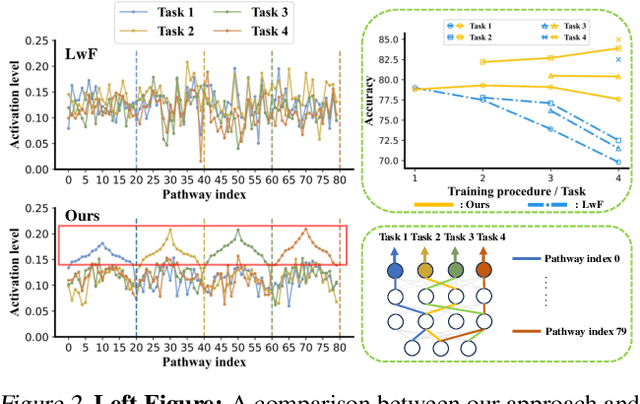
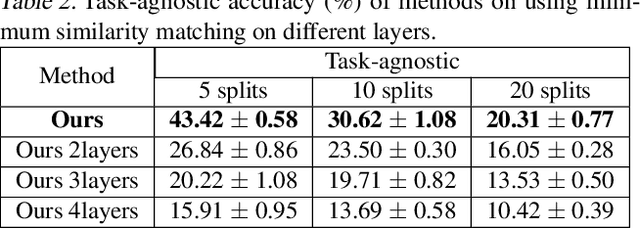
Deep networks are prone to catastrophic forgetting during sequential task learning, i.e., losing the knowledge about old tasks upon learning new tasks. To this end, continual learning(CL) has emerged, whose existing methods focus mostly on regulating or protecting the parameters associated with the previous tasks. However, parameter protection is often impractical, since the size of parameters for storing the old-task knowledge increases linearly with the number of tasks, otherwise it is hard to preserve the parameters related to the old-task knowledge. In this work, we bring a dual opinion from neuroscience and physics to CL: in the whole networks, the pathways matter more than the parameters when concerning the knowledge acquired from the old tasks. Following this opinion, we propose a novel CL framework, learning without isolation(LwI), where model fusion is formulated as graph matching and the pathways occupied by the old tasks are protected without being isolated. Thanks to the sparsity of activation channels in a deep network, LwI can adaptively allocate available pathways for a new task, realizing pathway protection and addressing catastrophic forgetting in a parameter-efficient manner. Experiments on popular benchmark datasets demonstrate the superiority of the proposed LwI.
Robust Multi-View Learning via Representation Fusion of Sample-Level Attention and Alignment of Simulated Perturbation
Mar 06, 2025



Recently, multi-view learning (MVL) has garnered significant attention due to its ability to fuse discriminative information from multiple views. However, real-world multi-view datasets are often heterogeneous and imperfect, which usually makes MVL methods designed for specific combinations of views lack application potential and limits their effectiveness. To address this issue, we propose a novel robust MVL method (namely RML) with simultaneous representation fusion and alignment. Specifically, we introduce a simple yet effective multi-view transformer fusion network where we transform heterogeneous multi-view data into homogeneous word embeddings, and then integrate multiple views by the sample-level attention mechanism to obtain a fused representation. Furthermore, we propose a simulated perturbation based multi-view contrastive learning framework that dynamically generates the noise and unusable perturbations for simulating imperfect data conditions. The simulated noisy and unusable data obtain two distinct fused representations, and we utilize contrastive learning to align them for learning discriminative and robust representations. Our RML is self-supervised and can also be applied for downstream tasks as a regularization. In experiments, we employ it in unsupervised multi-view clustering, noise-label classification, and as a plug-and-play module for cross-modal hashing retrieval. Extensive comparison experiments and ablation studies validate the effectiveness of RML.
Accurate Forgetting for Heterogeneous Federated Continual Learning
Feb 20, 2025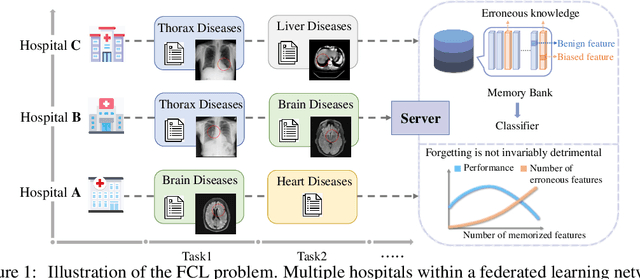
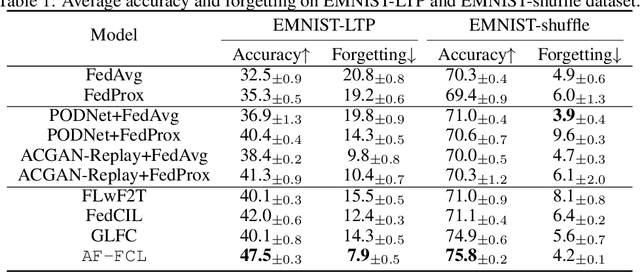
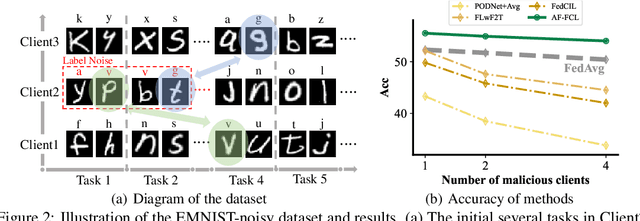
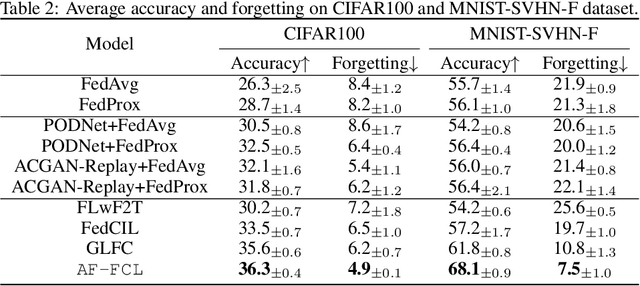
Recent years have witnessed a burgeoning interest in federated learning (FL). However, the contexts in which clients engage in sequential learning remain under-explored. Bridging FL and continual learning (CL) gives rise to a challenging practical problem: federated continual learning (FCL). Existing research in FCL primarily focuses on mitigating the catastrophic forgetting issue of continual learning while collaborating with other clients. We argue that the forgetting phenomena are not invariably detrimental. In this paper, we consider a more practical and challenging FCL setting characterized by potentially unrelated or even antagonistic data/tasks across different clients. In the FL scenario, statistical heterogeneity and data noise among clients may exhibit spurious correlations which result in biased feature learning. While existing CL strategies focus on a complete utilization of previous knowledge, we found that forgetting biased information is beneficial in our study. Therefore, we propose a new concept accurate forgetting (AF) and develop a novel generative-replay method~\method~which selectively utilizes previous knowledge in federated networks. We employ a probabilistic framework based on a normalizing flow model to quantify the credibility of previous knowledge. Comprehensive experiments affirm the superiority of our method over baselines.
Learning Locally, Revising Globally: Global Reviser for Federated Learning with Noisy Labels
Nov 30, 2024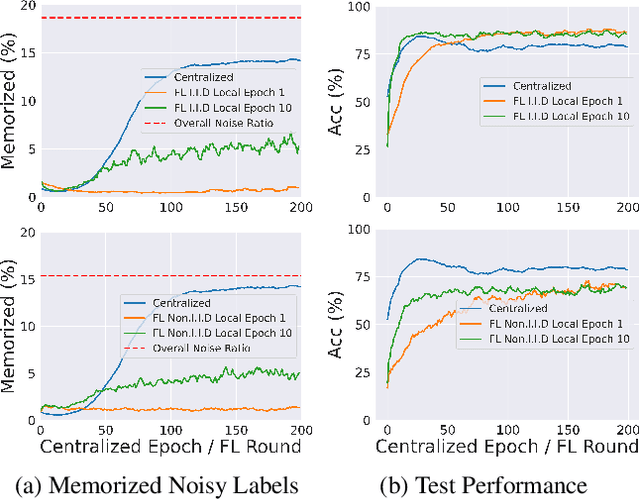
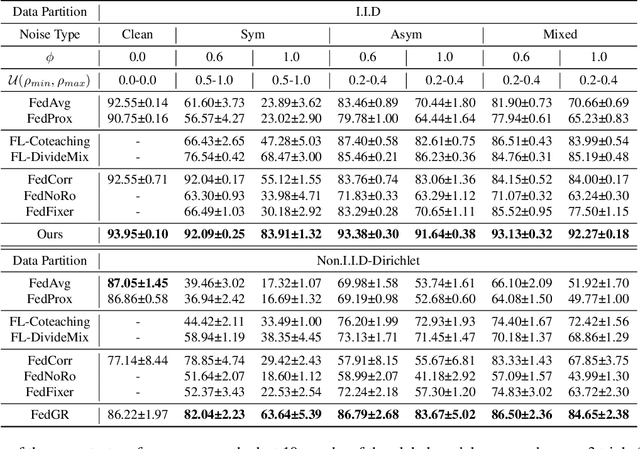
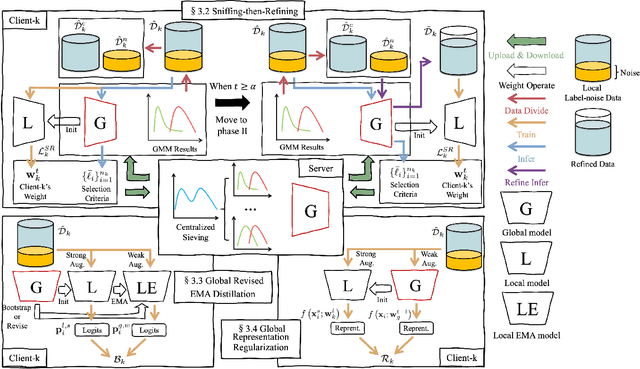
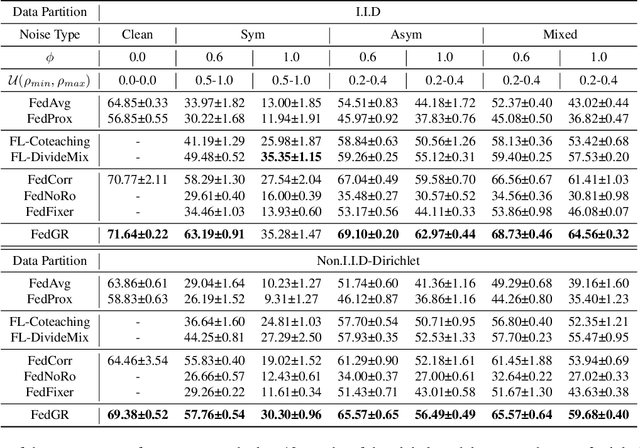
The success of most federated learning (FL) methods heavily depends on label quality, which is often inaccessible in real-world scenarios, such as medicine, leading to the federated label-noise (F-LN) problem. In this study, we observe that the global model of FL memorizes the noisy labels slowly. Based on the observations, we propose a novel approach dubbed Global Reviser for Federated Learning with Noisy Labels (FedGR) to enhance the label-noise robustness of FL. In brief, FedGR employs three novel modules to achieve noisy label sniffing and refining, local knowledge revising, and local model regularization. Specifically, the global model is adopted to infer local data proxies for global sample selection and refine incorrect labels. To maximize the utilization of local knowledge, we leverage the global model to revise the local exponential moving average (EMA) model of each client and distill it into the clients' models. Additionally, we introduce a global-to-local representation regularization to mitigate the overfitting of noisy labels. Extensive experiments on three F-LNL benchmarks against seven baseline methods demonstrate the effectiveness of the proposed FedGR.
On Unsupervised Prompt Learning for Classification with Black-box Language Models
Oct 04, 2024
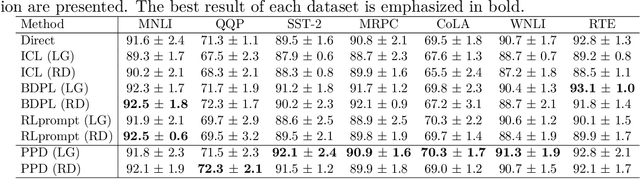


Large language models (LLMs) have achieved impressive success in text-formatted learning problems, and most popular LLMs have been deployed in a black-box fashion. Meanwhile, fine-tuning is usually necessary for a specific downstream task to obtain better performance, and this functionality is provided by the owners of the black-box LLMs. To fine-tune a black-box LLM, labeled data are always required to adjust the model parameters. However, in many real-world applications, LLMs can label textual datasets with even better quality than skilled human annotators, motivating us to explore the possibility of fine-tuning black-box LLMs with unlabeled data. In this paper, we propose unsupervised prompt learning for classification with black-box LLMs, where the learning parameters are the prompt itself and the pseudo labels of unlabeled data. Specifically, the prompt is modeled as a sequence of discrete tokens, and every token has its own to-be-learned categorical distribution. On the other hand, for learning the pseudo labels, we are the first to consider the in-context learning (ICL) capabilities of LLMs: we first identify reliable pseudo-labeled data using the LLM, and then assign pseudo labels to other unlabeled data based on the prompt, allowing the pseudo-labeled data to serve as in-context demonstrations alongside the prompt. Those in-context demonstrations matter: previously, they are involved when the prompt is used for prediction while they are not involved when the prompt is trained; thus, taking them into account during training makes the prompt-learning and prompt-using stages more consistent. Experiments on benchmark datasets show the effectiveness of our proposed algorithm. After unsupervised prompt learning, we can use the pseudo-labeled dataset for further fine-tuning by the owners of the black-box LLMs.