 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial-Aware Reduction Framework: Towards Efficient and Faithful Visual State Space Models
Jun 18, 2026Mamba demonstrates strong efficiency in modeling long visual sequences. However, when token reduction is applied to structurally enhanced Mamba variants, these models exhibit a severe performance collapse. We attribute this degradation to the spatially agnostic nature of existing reduction methods, which violate the two-dimensional structural premise required by the selective scanning mechanism. In this work, we propose STORM, a spatial-aware token reduction framework designed to maintain structural integrity throughout the compression process. STORM reformulates reduction into a structured operation on spatial units, enforcing localized constraints to maintain both grid topology and neighborhood coherence. As a plug-and-play module, STORM equips existing reduction pipelines with explicit spatial awareness without any training. Empirical results demonstrate that STORM achieves state-of-the-art pruning accuracy across diverse vision Mamba backbones under training-free settings. Notably, STORM delivers a substantial accuracy recovery on VMamba, outperforming prior methods by up to 63.3\% in top-1 accuracy. Meanwhile, STORM incurs only a 1.0\% accuracy drop on PlainMamba, achieving performance comparable to ViT.
AI-Salesman: Towards Reliable Large Language Model Driven Telemarketing
Nov 15, 2025Goal-driven persuasive dialogue, exemplified by applications like telemarketing, requires sophisticated multi-turn planning and strict factual faithfulness, which remains a significant challenge for even state-of-the-art Large Language Models (LLMs). A lack of task-specific data often limits previous works, and direct LLM application suffers from strategic brittleness and factual hallucination. In this paper, we first construct and release TeleSalesCorpus, the first real-world-grounded dialogue dataset for this domain. We then propose AI-Salesman, a novel framework featuring a dual-stage architecture. For the training stage, we design a Bayesian-supervised reinforcement learning algorithm that learns robust sales strategies from noisy dialogues. For the inference stage, we introduce the Dynamic Outline-Guided Agent (DOGA), which leverages a pre-built script library to provide dynamic, turn-by-turn strategic guidance. Moreover, we design a comprehensive evaluation framework that combines fine-grained metrics for key sales skills with the LLM-as-a-Judge paradigm. Experimental results demonstrate that our proposed AI-Salesman significantly outperforms baseline models in both automatic metrics and comprehensive human evaluations, showcasing its effectiveness in complex persuasive scenarios.
Deploying Models to Non-participating Clients in Federated Learning without Fine-tuning: A Hypernetwork-based Approach
Aug 18, 2025Federated Learning (FL) has emerged as a promising paradigm for privacy-preserving collaborative learning, yet data heterogeneity remains a critical challenge. While existing methods achieve progress in addressing data heterogeneity for participating clients, they fail to generalize to non-participating clients with in-domain distribution shifts and resource constraints. To mitigate this issue, we present HyperFedZero, a novel method that dynamically generates specialized models via a hypernetwork conditioned on distribution-aware embeddings. Our approach explicitly incorporates distribution-aware inductive biases into the model's forward pass, extracting robust distribution embeddings using a NoisyEmbed-enhanced extractor with a Balancing Penalty, effectively preventing feature collapse. The hypernetwork then leverages these embeddings to generate specialized models chunk-by-chunk for non-participating clients, ensuring adaptability to their unique data distributions. Extensive experiments on multiple datasets and models demonstrate HyperFedZero's remarkable performance, surpassing competing methods consistently with minimal computational, storage, and communication overhead. Moreover, ablation studies and visualizations further validate the necessity of each component, confirming meaningful adaptations and validating the effectiveness of HyperFedZero.
Graph Neural Networks in Modern AI-aided Drug Discovery
Jun 07, 2025Graph neural networks (GNNs), as topology/structure-aware models within deep learning, have emerged as powerful tools for AI-aided drug discovery (AIDD). By directly operating on molecular graphs, GNNs offer an intuitive and expressive framework for learning the complex topological and geometric features of drug-like molecules, cementing their role in modern molecular modeling. This review provides a comprehensive overview of the methodological foundations and representative applications of GNNs in drug discovery, spanning tasks such as molecular property prediction, virtual screening, molecular generation, biomedical knowledge graph construction, and synthesis planning. Particular attention is given to recent methodological advances, including geometric GNNs, interpretable models, uncertainty quantification, scalable graph architectures, and graph generative frameworks. We also discuss how these models integrate with modern deep learning approaches, such as self-supervised learning, multi-task learning, meta-learning and pre-training. Throughout this review, we highlight the practical challenges and methodological bottlenecks encountered when applying GNNs to real-world drug discovery pipelines, and conclude with a discussion on future directions.
GPS: Distilling Compact Memories via Grid-based Patch Sampling for Efficient Online Class-Incremental Learning
Apr 15, 2025Online class-incremental learning aims to enable models to continuously adapt to new classes with limited access to past data, while mitigating catastrophic forgetting. Replay-based methods address this by maintaining a small memory buffer of previous samples, achieving competitive performance. For effective replay under constrained storage, recent approaches leverage distilled data to enhance the informativeness of memory. However, such approaches often involve significant computational overhead due to the use of bi-level optimization. Motivated by these limitations, we introduce Grid-based Patch Sampling (GPS), a lightweight and effective strategy for distilling informative memory samples without relying on a trainable model. GPS generates informative samples by sampling a subset of pixels from the original image, yielding compact low-resolution representations that preserve both semantic content and structural information. During replay, these representations are reassembled to support training and evaluation. Experiments on extensive benchmarks demonstrate that GRS can be seamlessly integrated into existing replay frameworks, leading to 3%-4% improvements in average end accuracy under memory-constrained settings, with limited computational overhead.
Ferret: An Efficient Online Continual Learning Framework under Varying Memory Constraints
Mar 15, 2025In the realm of high-frequency data streams, achieving real-time learning within varying memory constraints is paramount. This paper presents Ferret, a comprehensive framework designed to enhance online accuracy of Online Continual Learning (OCL) algorithms while dynamically adapting to varying memory budgets. Ferret employs a fine-grained pipeline parallelism strategy combined with an iterative gradient compensation algorithm, ensuring seamless handling of high-frequency data with minimal latency, and effectively counteracting the challenge of stale gradients in parallel training. To adapt to varying memory budgets, its automated model partitioning and pipeline planning optimizes performance regardless of memory limitations. Extensive experiments across 20 benchmarks and 5 integrated OCL algorithms show Ferret's remarkable efficiency, achieving up to 3.7$\times$ lower memory overhead to reach the same online accuracy compared to competing methods. Furthermore, Ferret consistently outperforms these methods across diverse memory budgets, underscoring its superior adaptability. These findings position Ferret as a premier solution for efficient and adaptive OCL framework in real-time environments.
E-3SFC: Communication-Efficient Federated Learning with Double-way Features Synthesizing
Feb 05, 2025The exponential growth in model sizes has significantly increased the communication burden in Federated Learning (FL). Existing methods to alleviate this burden by transmitting compressed gradients often face high compression errors, which slow down the model's convergence. To simultaneously achieve high compression effectiveness and lower compression errors, we study the gradient compression problem from a novel perspective. Specifically, we propose a systematical algorithm termed Extended Single-Step Synthetic Features Compressing (E-3SFC), which consists of three sub-components, i.e., the Single-Step Synthetic Features Compressor (3SFC), a double-way compression algorithm, and a communication budget scheduler. First, we regard the process of gradient computation of a model as decompressing gradients from corresponding inputs, while the inverse process is considered as compressing the gradients. Based on this, we introduce a novel gradient compression method termed 3SFC, which utilizes the model itself as a decompressor, leveraging training priors such as model weights and objective functions. 3SFC compresses raw gradients into tiny synthetic features in a single-step simulation, incorporating error feedback to minimize overall compression errors. To further reduce communication overhead, 3SFC is extended to E-3SFC, allowing double-way compression and dynamic communication budget scheduling. Our theoretical analysis under both strongly convex and non-convex conditions demonstrates that 3SFC achieves linear and sub-linear convergence rates with aggregation noise. Extensive experiments across six datasets and six models reveal that 3SFC outperforms state-of-the-art methods by up to 13.4% while reducing communication costs by 111.6 times. These findings suggest that 3SFC can significantly enhance communication efficiency in FL without compromising model performance.
Learning Locally, Revising Globally: Global Reviser for Federated Learning with Noisy Labels
Nov 30, 2024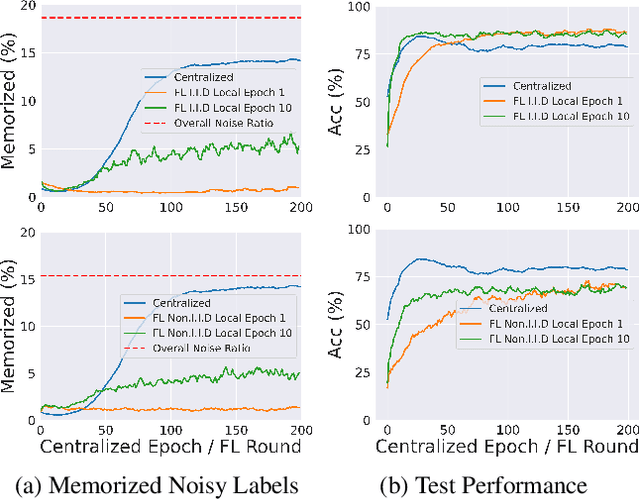
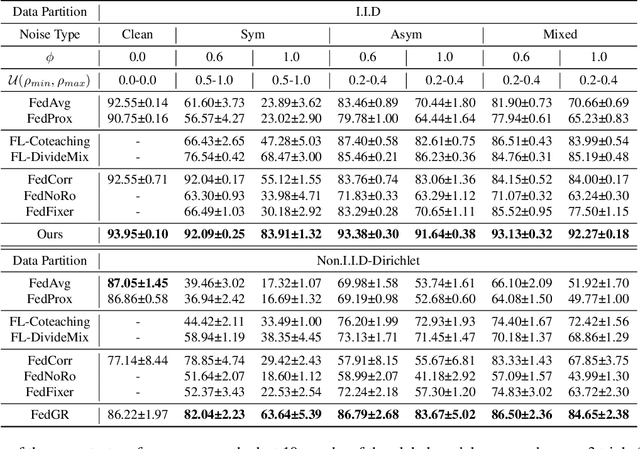
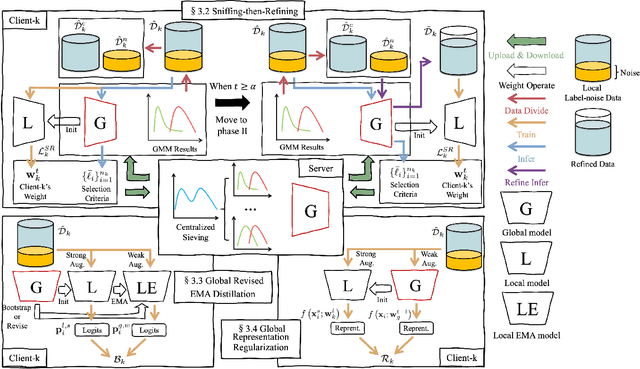
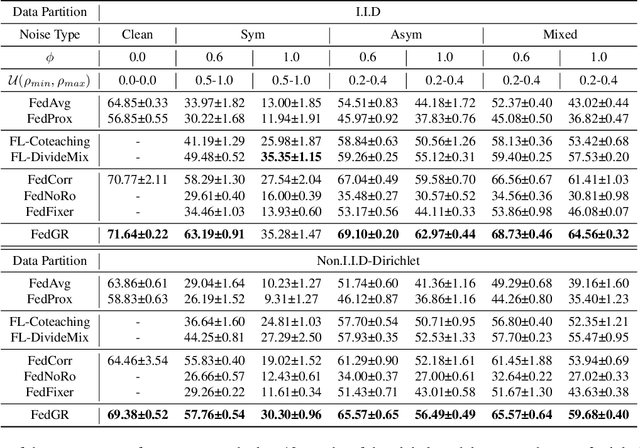
The success of most federated learning (FL) methods heavily depends on label quality, which is often inaccessible in real-world scenarios, such as medicine, leading to the federated label-noise (F-LN) problem. In this study, we observe that the global model of FL memorizes the noisy labels slowly. Based on the observations, we propose a novel approach dubbed Global Reviser for Federated Learning with Noisy Labels (FedGR) to enhance the label-noise robustness of FL. In brief, FedGR employs three novel modules to achieve noisy label sniffing and refining, local knowledge revising, and local model regularization. Specifically, the global model is adopted to infer local data proxies for global sample selection and refine incorrect labels. To maximize the utilization of local knowledge, we leverage the global model to revise the local exponential moving average (EMA) model of each client and distill it into the clients' models. Additionally, we introduce a global-to-local representation regularization to mitigate the overfitting of noisy labels. Extensive experiments on three F-LNL benchmarks against seven baseline methods demonstrate the effectiveness of the proposed FedGR.
PRIOR: Personalized Prior for Reactivating the Information Overlooked in Federated Learning
Oct 13, 2023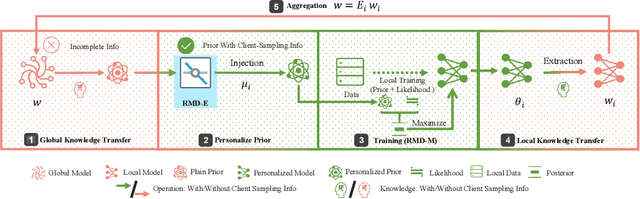
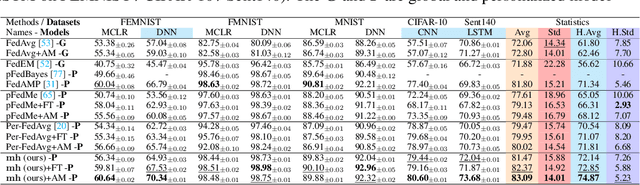
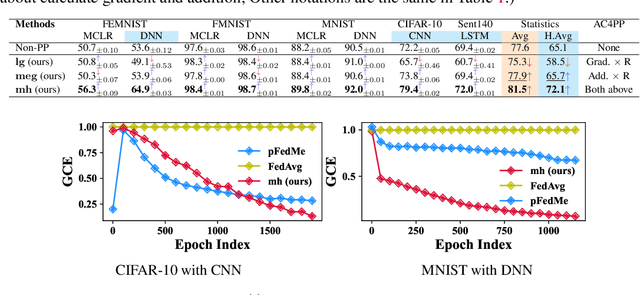
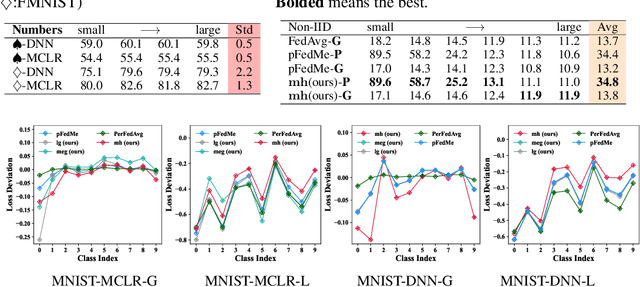
Classical federated learning (FL) enables training machine learning models without sharing data for privacy preservation, but heterogeneous data characteristic degrades the performance of the localized model. Personalized FL (PFL) addresses this by synthesizing personalized models from a global model via training on local data. Such a global model may overlook the specific information that the clients have been sampled. In this paper, we propose a novel scheme to inject personalized prior knowledge into the global model in each client, which attempts to mitigate the introduced incomplete information problem in PFL. At the heart of our proposed approach is a framework, the PFL with Bregman Divergence (pFedBreD), decoupling the personalized prior from the local objective function regularized by Bregman divergence for greater adaptability in personalized scenarios. We also relax the mirror descent (RMD) to extract the prior explicitly to provide optional strategies. Additionally, our pFedBreD is backed up by a convergence analysis. Sufficient experiments demonstrate that our method reaches the state-of-the-art performances on 5 datasets and outperforms other methods by up to 3.5% across 8 benchmarks. Extensive analyses verify the robustness and necessity of proposed designs.
CodeFuse-13B: A Pretrained Multi-lingual Code Large Language Model
Oct 10, 2023Code Large Language Models (Code LLMs) have gained significant attention in the industry due to their wide applications in the full lifecycle of software engineering. However, the effectiveness of existing models in understanding non-English inputs for multi-lingual code-related tasks is still far from well studied. This paper introduces CodeFuse-13B, an open-sourced pre-trained code LLM. It is specifically designed for code-related tasks with both English and Chinese prompts and supports over 40 programming languages. CodeFuse achieves its effectiveness by utilizing a high quality pre-training dataset that is carefully filtered by program analyzers and optimized during the training process. Extensive experiments are conducted using real-world usage scenarios, the industry-standard benchmark HumanEval-x, and the specially designed CodeFuseEval for Chinese prompts. To assess the effectiveness of CodeFuse, we actively collected valuable human feedback from the AntGroup's software development process where CodeFuse has been successfully deployed. The results demonstrate that CodeFuse-13B achieves a HumanEval pass@1 score of 37.10%, positioning it as one of the top multi-lingual code LLMs with similar parameter sizes. In practical scenarios, such as code generation, code translation, code comments, and testcase generation, CodeFuse performs better than other models when confronted with Chinese prompts.