 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuitoBench: A High-Quality Open Time Series Forecasting Benchmark
Mar 27, 2026Time series forecasting is critical across finance, healthcare, and cloud computing, yet progress is constrained by a fundamental bottleneck: the scarcity of large-scale, high-quality benchmarks. To address this gap, we introduce \textsc{QuitoBench}, a regime-balanced benchmark for time series forecasting with coverage across eight trend$\times$seasonality$\times$forecastability (TSF) regimes, designed to capture forecasting-relevant properties rather than application-defined domain labels. The benchmark is built upon \textsc{Quito}, a billion-scale time series corpus of application traffic from Alipay spanning nine business domains. Benchmarking 10 models from deep learning, foundation models, and statistical baselines across 232,200 evaluation instances, we report four key findings: (i) a context-length crossover where deep learning models lead at short context ($L=96$) but foundation models dominate at long context ($L \ge 576$); (ii) forecastability is the dominant difficulty driver, producing a $3.64 \times$ MAE gap across regimes; (iii) deep learning models match or surpass foundation models at $59 \times$ fewer parameters; and (iv) scaling the amount of training data provides substantially greater benefit than scaling model size for both model families. These findings are validated by strong cross-benchmark and cross-metric consistency. Our open-source release enables reproducible, regime-aware evaluation for time series forecasting research.
F2LLM-v2: Inclusive, Performant, and Efficient Embeddings for a Multilingual World
Mar 19, 2026We present F2LLM-v2, a new family of general-purpose, multilingual embedding models in 8 distinct sizes ranging from 80M to 14B. Trained on a newly curated composite of 60 million publicly available high-quality data samples, F2LLM-v2 supports more than 200 languages, with a particular emphasis on previously underserved mid- and low-resource languages. By integrating a two-stage LLM-based embedding training pipeline with matryoshka learning, model pruning, and knowledge distillation techniques, we present models that are far more efficient than previous LLM-based embedding models while retaining competitive performances. Extensive evaluations confirm that F2LLM-v2-14B ranks first on 11 MTEB benchmarks, while the smaller models in the family also set a new state of the art for resource-constrained applications. To facilitate open-source embedding model research, we release all models, data, code, and intermediate checkpoints.
LLM as Graph Kernel: Rethinking Message Passing on Text-Rich Graphs
Mar 16, 2026Text-rich graphs, which integrate complex structural dependencies with abundant textual information, are ubiquitous yet remain challenging for existing learning paradigms. Conventional methods and even LLM-hybrids compress rich text into static embeddings or summaries before structural reasoning, creating an information bottleneck and detaching updates from the raw content. We argue that in text-rich graphs, the text is not merely a node attribute but the primary medium through which structural relationships are manifested. We introduce RAMP, a Raw-text Anchored Message Passing approach that moves beyond using LLMs as mere feature extractors and instead recasts the LLM itself as a graph-native aggregation operator. RAMP exploits the text-rich nature of the graph via a novel dual-representation scheme: it anchors inference on each node's raw text during each iteration while propagating dynamically optimized messages from neighbors. It further handles both discriminative and generative tasks under a single unified generative formulation. Extensive experiments show that RAMP effectively bridges the gap between graph propagation and deep text reasoning, achieving competitive performance and offering new insights into the role of LLMs as graph kernels for general-purpose graph learning.
SWE-Fuse: Empowering Software Agents via Issue-free Trajectory Learning and Entropy-aware RLVR Training
Mar 09, 2026Large language models (LLMs) have transformed the software engineering landscape. Recently, numerous LLM-based agents have been developed to address real-world software issue fixing tasks. Despite their state-of-the-art performance, Despite achieving state-of-the-art performance, these agents face a significant challenge: \textbf{Insufficient high-quality issue descriptions.} Real-world datasets often exhibit misalignments between issue descriptions and their corresponding solutions, introducing noise and ambiguity that mislead automated agents and limit their problem-solving effectiveness. We propose \textbf{\textit{SWE-Fuse}}, an issue-description-aware training framework that fuses issue-description-guided and issue-free samples for training SWE agents. It consists of two key modules: (1) An issue-free-driven trajectory learning module for mitigating potentially misleading issue descriptions while enabling the model to learn step-by-step debugging processes; and (2) An entropy-aware RLVR training module, which adaptively adjusts training dynamics through entropy-driven clipping. It applies relaxed clipping under high entropy to encourage exploration, and stricter clipping under low entropy to ensure training stability. We evaluate SWE-Fuse on the widely studied SWE-bench Verified benchmark shows to demonstrate its effectiveness in solving real-world software problems. Specifically, SWE-Fuse outperforms the best 8B and 32B baselines by 43.0\% and 60.2\% in solve rate, respectively. Furthermore, integrating SWE-Fuse with test-time scaling (TTS) enables further performance improvements, achieving solve rates of 49.8\% and 65.2\% under TTS@8 for the 8B and 32B models, respectively.
OpAgent: Operator Agent for Web Navigation
Feb 14, 2026To fulfill user instructions, autonomous web agents must contend with the inherent complexity and volatile nature of real-world websites. Conventional paradigms predominantly rely on Supervised Fine-Tuning (SFT) or Offline Reinforcement Learning (RL) using static datasets. However, these methods suffer from severe distributional shifts, as offline trajectories fail to capture the stochastic state transitions and real-time feedback of unconstrained wide web environments. In this paper, we propose a robust Online Reinforcement Learning WebAgent, designed to optimize its policy through direct, iterative interactions with unconstrained wide websites. Our approach comprises three core innovations: 1) Hierarchical Multi-Task Fine-tuning: We curate a comprehensive mixture of datasets categorized by functional primitives -- Planning, Acting, and Grounding -- establishing a Vision-Language Model (VLM) with strong instruction-following capabilities for Web GUI tasks. 2) Online Agentic RL in the Wild: We develop an online interaction environment and fine-tune the VLM using a specialized RL pipeline. We introduce a Hybrid Reward Mechanism that combines a ground-truth-agnostic WebJudge for holistic outcome assessment with a Rule-based Decision Tree (RDT) for progress reward. This system effectively mitigates the credit assignment challenge in long-horizon navigation. Notably, our RL-enhanced model achieves a 38.1\% success rate (pass@5) on WebArena, outperforming all existing monolithic baselines. 3) Operator Agent: We introduce a modular agentic framework, namely \textbf{OpAgent}, orchestrating a Planner, Grounder, Reflector, and Summarizer. This synergy enables robust error recovery and self-correction, elevating the agent's performance to a new State-of-the-Art (SOTA) success rate of \textbf{71.6\%}.
From One-to-One to Many-to-Many: Dynamic Cross-Layer Injection for Deep Vision-Language Fusion
Jan 15, 2026Vision-Language Models (VLMs) create a severe visual feature bottleneck by using a crude, asymmetric connection that links only the output of the vision encoder to the input of the large language model (LLM). This static architecture fundamentally limits the ability of LLMs to achieve comprehensive alignment with hierarchical visual knowledge, compromising their capacity to accurately integrate local details with global semantics into coherent reasoning. To resolve this, we introduce Cross-Layer Injection (CLI), a novel and lightweight framework that forges a dynamic many-to-many bridge between the two modalities. CLI consists of two synergistic, parameter-efficient components: an Adaptive Multi-Projection (AMP) module that harmonizes features from diverse vision layers, and an Adaptive Gating Fusion (AGF) mechanism that empowers the LLM to selectively inject the most relevant visual information based on its real-time decoding context. We validate the effectiveness and versatility of CLI by integrating it into LLaVA-OneVision and LLaVA-1.5. Extensive experiments on 18 diverse benchmarks demonstrate significant performance improvements, establishing CLI as a scalable paradigm that unlocks deeper multimodal understanding by granting LLMs on-demand access to the full visual hierarchy.
C2LLM Technical Report: A New Frontier in Code Retrieval via Adaptive Cross-Attention Pooling
Dec 24, 2025We present C2LLM - Contrastive Code Large Language Models, a family of code embedding models in both 0.5B and 7B sizes. Building upon Qwen-2.5-Coder backbones, C2LLM adopts a Pooling by Multihead Attention (PMA) module for generating sequence embedding from token embeddings, effectively 1) utilizing the LLM's causal representations acquired during pretraining, while also 2) being able to aggregate information from all tokens in the sequence, breaking the information bottleneck in EOS-based sequence embeddings, and 3) supporting flexible adaptation of embedding dimension, serving as an alternative to MRL. Trained on three million publicly available data, C2LLM models set new records on MTEB-Code among models of similar sizes, with C2LLM-7B ranking 1st on the overall leaderboard.
F2LLM Technical Report: Matching SOTA Embedding Performance with 6 Million Open-Source Data
Oct 02, 2025

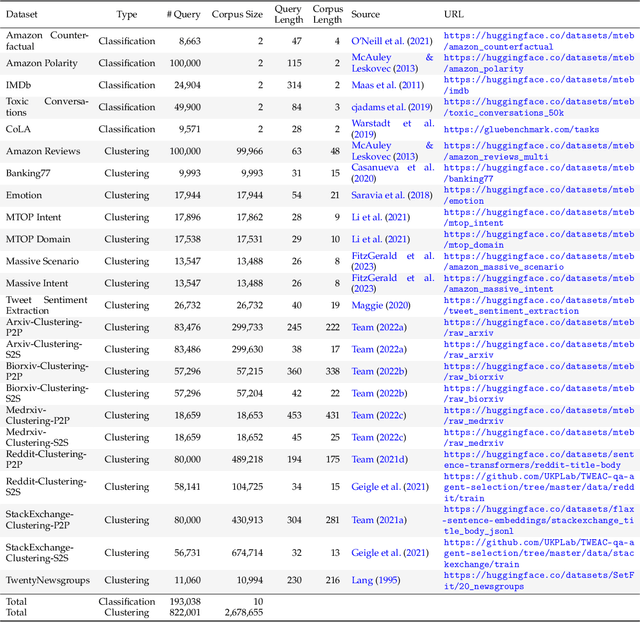
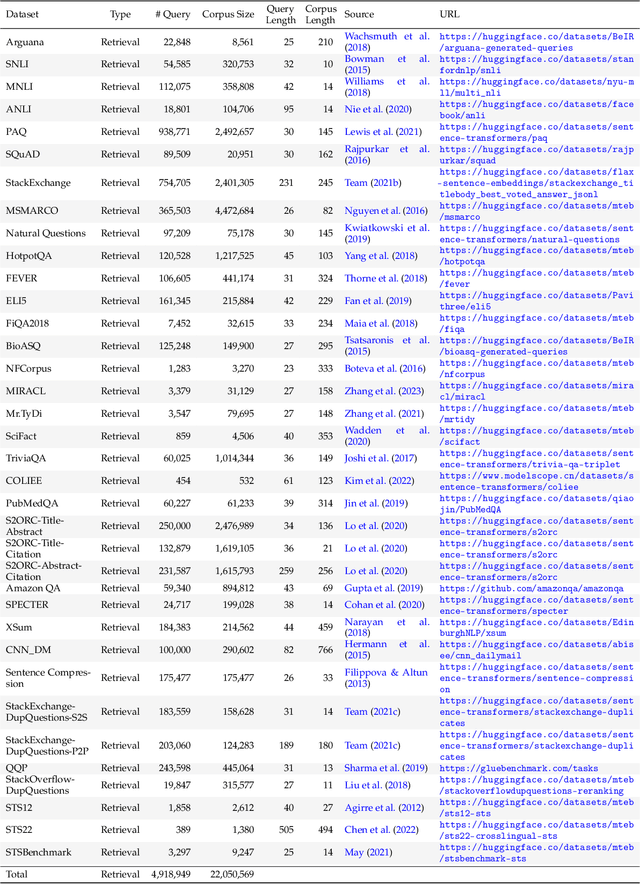
We introduce F2LLM - Foundation to Feature Large Language Models, a suite of state-of-the-art embedding models in three sizes: 0.6B, 1.7B, and 4B. Unlike previous top-ranking embedding models that require massive contrastive pretraining, sophisticated training pipelines, and costly synthetic training data, F2LLM is directly finetuned from foundation models on 6 million query-document-negative tuples curated from open-source, non-synthetic datasets, striking a strong balance between training cost, model size, and embedding performance. On the MTEB English leaderboard, F2LLM-4B ranks 2nd among models with approximately 4B parameters and 7th overall, while F2LLM-1.7B ranks 1st among models in the 1B-2B size range. To facilitate future research in the field, we release the models, training dataset, and code, positioning F2LLM as a strong, reproducible, and budget-friendly baseline for future works.
Systematic Analysis of MCP Security
Aug 18, 2025The Model Context Protocol (MCP) has emerged as a universal standard that enables AI agents to seamlessly connect with external tools, significantly enhancing their functionality. However, while MCP brings notable benefits, it also introduces significant vulnerabilities, such as Tool Poisoning Attacks (TPA), where hidden malicious instructions exploit the sycophancy of large language models (LLMs) to manipulate agent behavior. Despite these risks, current academic research on MCP security remains limited, with most studies focusing on narrow or qualitative analyses that fail to capture the diversity of real-world threats. To address this gap, we present the MCP Attack Library (MCPLIB), which categorizes and implements 31 distinct attack methods under four key classifications: direct tool injection, indirect tool injection, malicious user attacks, and LLM inherent attack. We further conduct a quantitative analysis of the efficacy of each attack. Our experiments reveal key insights into MCP vulnerabilities, including agents' blind reliance on tool descriptions, sensitivity to file-based attacks, chain attacks exploiting shared context, and difficulty distinguishing external data from executable commands. These insights, validated through attack experiments, underscore the urgency for robust defense strategies and informed MCP design. Our contributions include 1) constructing a comprehensive MCP attack taxonomy, 2) introducing a unified attack framework MCPLIB, and 3) conducting empirical vulnerability analysis to enhance MCP security mechanisms. This work provides a foundational framework, supporting the secure evolution of MCP ecosystems.
Code Graph Model (CGM): A Graph-Integrated Large Language Model for Repository-Level Software Engineering Tasks
May 22, 2025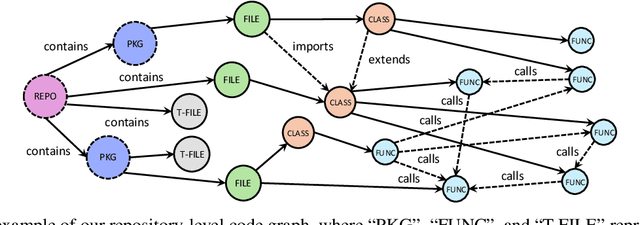
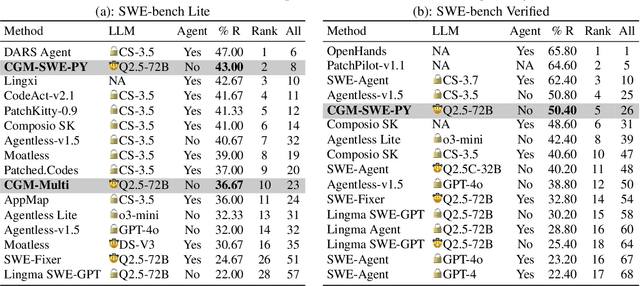
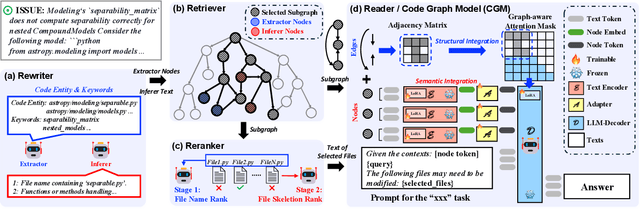

Recent advances in Large Language Models (LLMs) have shown promise in function-level code generation, yet repository-level software engineering tasks remain challenging. Current solutions predominantly rely on proprietary LLM agents, which introduce unpredictability and limit accessibility, raising concerns about data privacy and model customization. This paper investigates whether open-source LLMs can effectively address repository-level tasks without requiring agent-based approaches. We demonstrate this is possible by enabling LLMs to comprehend functions and files within codebases through their semantic information and structural dependencies. To this end, we introduce Code Graph Models (CGMs), which integrate repository code graph structures into the LLM's attention mechanism and map node attributes to the LLM's input space using a specialized adapter. When combined with an agentless graph RAG framework, our approach achieves a 43.00% resolution rate on the SWE-bench Lite benchmark using the open-source Qwen2.5-72B model. This performance ranks first among open weight models, second among methods with open-source systems, and eighth overall, surpassing the previous best open-source model-based method by 12.33%.