 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTessera: Unlocking Heterogeneous GPUs through Kernel-Granularity Disaggregation
Apr 11, 2026Disaggregation maps parts of an AI workload to different types of GPUs, offering a path to utilize modern heterogeneous GPU clusters. However, existing solutions operate at a coarse granularity and are tightly coupled to specific model architectures, leaving much room for performance improvement. This paper presents Tessera, the first kernel disaggregation system to improve performance and cost efficiency on heterogeneous GPUs for large model inference. Our key insight is that kernels within a single application exhibit diverse resource demands, making them the most suitable granularity for aligning computation with hardware capabilities. Tessera integrates offline analysis with online adaptation by extracting precise inter-kernel dependencies from PTX to ensure correctness, overlapping communication with computation through a pipelined execution model, and employing workload-aware scheduling with lightweight runtime adaptation. Extensive evaluations across five heterogeneous GPUs and four model architectures, scaling up to 16 GPUs, show that Tessera improves serving throughput and cost efficiency by up to 2.3x and 1.6x, respectively, compared to existing disaggregation methods, while generalizing to model architectures where prior approaches do not apply. Surprisingly, a heterogeneous GPU pair under Tessera can even exceed the throughput of two homogeneous high-end GPUs at a lower cost.
C2LLM Technical Report: A New Frontier in Code Retrieval via Adaptive Cross-Attention Pooling
Dec 24, 2025We present C2LLM - Contrastive Code Large Language Models, a family of code embedding models in both 0.5B and 7B sizes. Building upon Qwen-2.5-Coder backbones, C2LLM adopts a Pooling by Multihead Attention (PMA) module for generating sequence embedding from token embeddings, effectively 1) utilizing the LLM's causal representations acquired during pretraining, while also 2) being able to aggregate information from all tokens in the sequence, breaking the information bottleneck in EOS-based sequence embeddings, and 3) supporting flexible adaptation of embedding dimension, serving as an alternative to MRL. Trained on three million publicly available data, C2LLM models set new records on MTEB-Code among models of similar sizes, with C2LLM-7B ranking 1st on the overall leaderboard.
Mutual-Supervised Learning for Sequential-to-Parallel Code Translation
Jun 11, 2025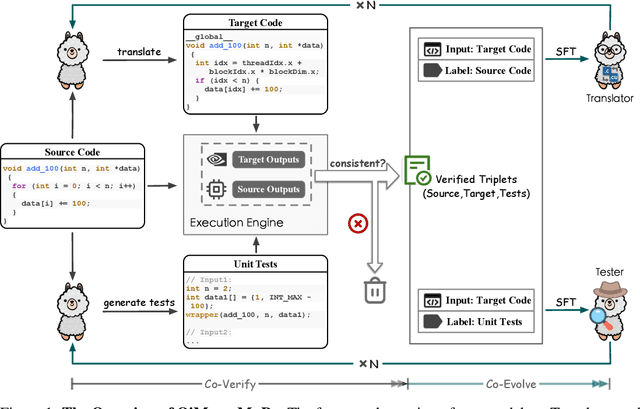
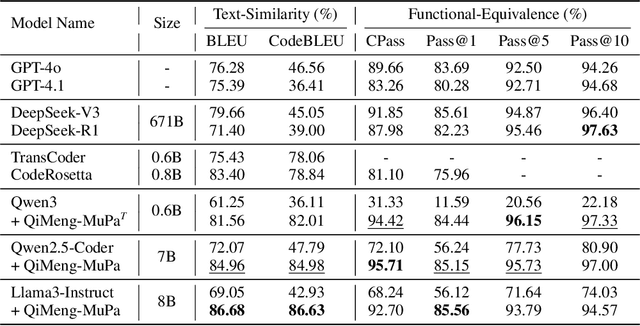
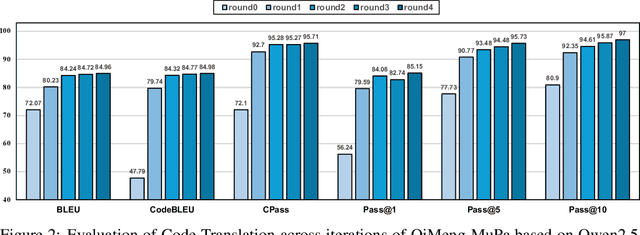
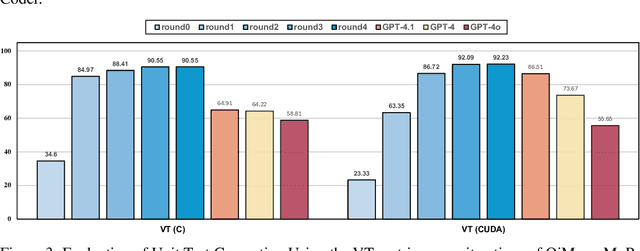
The rise of GPU-based high-performance computing (HPC) has driven the widespread adoption of parallel programming models such as CUDA. Yet, the inherent complexity of parallel programming creates a demand for the automated sequential-to-parallel approaches. However, data scarcity poses a significant challenge for machine learning-based sequential-to-parallel code translation. Although recent back-translation methods show promise, they still fail to ensure functional equivalence in the translated code. In this paper, we propose a novel Mutual-Supervised Learning (MSL) framework for sequential-to-parallel code translation to address the functional equivalence issue. MSL consists of two models, a Translator and a Tester. Through an iterative loop consisting of Co-verify and Co-evolve steps, the Translator and the Tester mutually generate data for each other and improve collectively. The Tester generates unit tests to verify and filter functionally equivalent translated code, thereby evolving the Translator, while the Translator generates translated code as augmented input to evolve the Tester. Experimental results demonstrate that MuSL significantly enhances the performance of the base model: when applied to Qwen2.5-Coder, it not only improves Pass@1 by up to 28.91% and boosts Tester performance by 68.90%, but also outperforms the previous state-of-the-art method CodeRosetta by 1.56 and 6.92 in BLEU and CodeBLEU scores, while achieving performance comparable to DeepSeek-R1 and GPT-4.1. Our code is available at https://github.com/kcxain/musl.
KV Inversion: KV Embeddings Learning for Text-Conditioned Real Image Action Editing
Sep 28, 2023
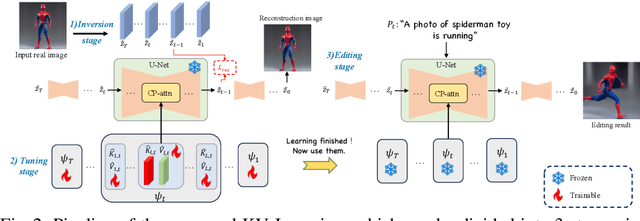


Text-conditioned image editing is a recently emerged and highly practical task, and its potential is immeasurable. However, most of the concurrent methods are unable to perform action editing, i.e. they can not produce results that conform to the action semantics of the editing prompt and preserve the content of the original image. To solve the problem of action editing, we propose KV Inversion, a method that can achieve satisfactory reconstruction performance and action editing, which can solve two major problems: 1) the edited result can match the corresponding action, and 2) the edited object can retain the texture and identity of the original real image. In addition, our method does not require training the Stable Diffusion model itself, nor does it require scanning a large-scale dataset to perform time-consuming training.
PointSee: Image Enhances Point Cloud
Nov 03, 2022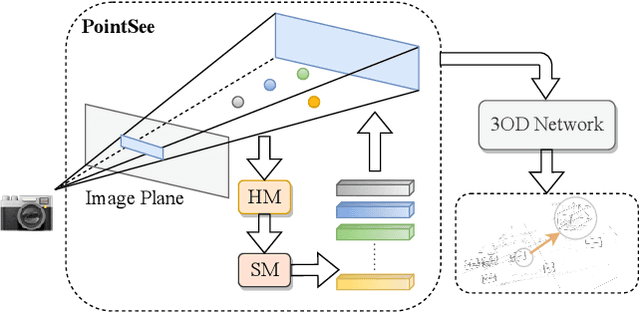



There is a trend to fuse multi-modal information for 3D object detection (3OD). However, the challenging problems of low lightweightness, poor flexibility of plug-and-play, and inaccurate alignment of features are still not well-solved, when designing multi-modal fusion newtorks. We propose PointSee, a lightweight, flexible and effective multi-modal fusion solution to facilitate various 3OD networks by semantic feature enhancement of LiDAR point clouds assembled with scene images. Beyond the existing wisdom of 3OD, PointSee consists of a hidden module (HM) and a seen module (SM): HM decorates LiDAR point clouds using 2D image information in an offline fusion manner, leading to minimal or even no adaptations of existing 3OD networks; SM further enriches the LiDAR point clouds by acquiring point-wise representative semantic features, leading to enhanced performance of existing 3OD networks. Besides the new architecture of PointSee, we propose a simple yet efficient training strategy, to ease the potential inaccurate regressions of 2D object detection networks. Extensive experiments on the popular outdoor/indoor benchmarks show numerical improvements of our PointSee over twenty-two state-of-the-arts.