 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKV Inversion: KV Embeddings Learning for Text-Conditioned Real Image Action Editing
Paper and Code
Sep 28, 2023
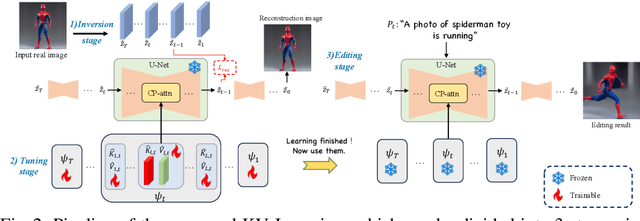


Text-conditioned image editing is a recently emerged and highly practical task, and its potential is immeasurable. However, most of the concurrent methods are unable to perform action editing, i.e. they can not produce results that conform to the action semantics of the editing prompt and preserve the content of the original image. To solve the problem of action editing, we propose KV Inversion, a method that can achieve satisfactory reconstruction performance and action editing, which can solve two major problems: 1) the edited result can match the corresponding action, and 2) the edited object can retain the texture and identity of the original real image. In addition, our method does not require training the Stable Diffusion model itself, nor does it require scanning a large-scale dataset to perform time-consuming training.