 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDouble-Calibration: Towards Trustworthy LLMs via Calibrating Knowledge and Reasoning Confidence
Jan 17, 2026Trustworthy reasoning in Large Language Models (LLMs) is challenged by their propensity for hallucination. While augmenting LLMs with Knowledge Graphs (KGs) improves factual accuracy, existing KG-augmented methods fail to quantify epistemic uncertainty in both the retrieved evidence and LLMs' reasoning. To bridge this gap, we introduce DoublyCal, a framework built on a novel double-calibration principle. DoublyCal employs a lightweight proxy model to first generate KG evidence alongside a calibrated evidence confidence. This calibrated supporting evidence then guides a black-box LLM, yielding final predictions that are not only more accurate but also well-calibrated, with confidence scores traceable to the uncertainty of the supporting evidence. Experiments on knowledge-intensive benchmarks show that DoublyCal significantly improves both the accuracy and confidence calibration of black-box LLMs with low token cost.
Wavelet-guided Misalignment-aware Network for Visible-Infrared Object Detection
Jul 27, 2025Visible-infrared object detection aims to enhance the detection robustness by exploiting the complementary information of visible and infrared image pairs. However, its performance is often limited by frequent misalignments caused by resolution disparities, spatial displacements, and modality inconsistencies. To address this issue, we propose the Wavelet-guided Misalignment-aware Network (WMNet), a unified framework designed to adaptively address different cross-modal misalignment patterns. WMNet incorporates wavelet-based multi-frequency analysis and modality-aware fusion mechanisms to improve the alignment and integration of cross-modal features. By jointly exploiting low and high-frequency information and introducing adaptive guidance across modalities, WMNet alleviates the adverse effects of noise, illumination variation, and spatial misalignment. Furthermore, it enhances the representation of salient target features while suppressing spurious or misleading information, thereby promoting more accurate and robust detection. Extensive evaluations on the DVTOD, DroneVehicle, and M3FD datasets demonstrate that WMNet achieves state-of-the-art performance on misaligned cross-modal object detection tasks, confirming its effectiveness and practical applicability.
PairEdit: Learning Semantic Variations for Exemplar-based Image Editing
Jun 09, 2025Recent advancements in text-guided image editing have achieved notable success by leveraging natural language prompts for fine-grained semantic control. However, certain editing semantics are challenging to specify precisely using textual descriptions alone. A practical alternative involves learning editing semantics from paired source-target examples. Existing exemplar-based editing methods still rely on text prompts describing the change within paired examples or learning implicit text-based editing instructions. In this paper, we introduce PairEdit, a novel visual editing method designed to effectively learn complex editing semantics from a limited number of image pairs or even a single image pair, without using any textual guidance. We propose a target noise prediction that explicitly models semantic variations within paired images through a guidance direction term. Moreover, we introduce a content-preserving noise schedule to facilitate more effective semantic learning. We also propose optimizing distinct LoRAs to disentangle the learning of semantic variations from content. Extensive qualitative and quantitative evaluations demonstrate that PairEdit successfully learns intricate semantics while significantly improving content consistency compared to baseline methods. Code will be available at https://github.com/xudonmao/PairEdit.
Joint System Latency and Data Freshness Optimization for Cache-enabled Mobile Crowdsensing Networks
Jan 24, 2025



Mobile crowdsensing (MCS) networks enable large-scale data collection by leveraging the ubiquity of mobile devices. However, frequent sensing and data transmission can lead to significant resource consumption. To mitigate this issue, edge caching has been proposed as a solution for storing recently collected data. Nonetheless, this approach may compromise data freshness. In this paper, we investigate the trade-off between re-using cached task results and re-sensing tasks in cache-enabled MCS networks, aiming to minimize system latency while maintaining information freshness. To this end, we formulate a weighted delay and age of information (AoI) minimization problem, jointly optimizing sensing decisions, user selection, channel selection, task allocation, and caching strategies. The problem is a mixed-integer non-convex programming problem which is intractable. Therefore, we decompose the long-term problem into sequential one-shot sub-problems and design a framework that optimizes system latency, task sensing decision, and caching strategy subproblems. When one task is re-sensing, the one-shot problem simplifies to the system latency minimization problem, which can be solved optimally. The task sensing decision is then made by comparing the system latency and AoI. Additionally, a Bayesian update strategy is developed to manage the cached task results. Building upon this framework, we propose a lightweight and time-efficient algorithm that makes real-time decisions for the long-term optimization problem. Extensive simulation results validate the effectiveness of our approach.
Graph Similarity Computation via Interpretable Neural Node Alignment
Dec 13, 2024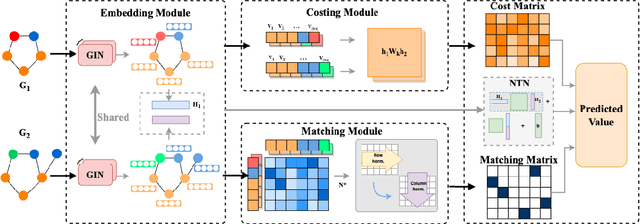

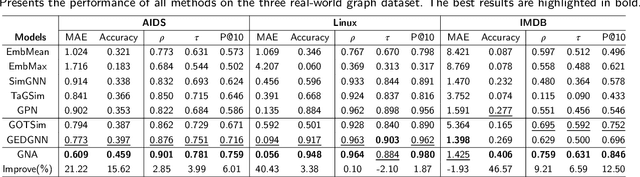
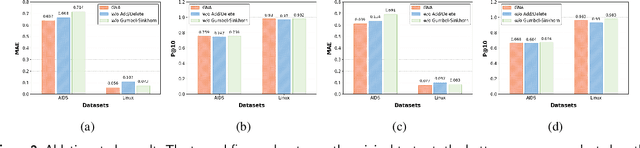
\Graph similarity computation is an essential task in many real-world graph-related applications such as retrieving the similar drugs given a query chemical compound or finding the user's potential friends from the social network database. Graph Edit Distance (GED) and Maximum Common Subgraphs (MCS) are the two commonly used domain-agnostic metrics to evaluate graph similarity in practice. Unfortunately, computing the exact GED is known to be a NP-hard problem. To solve this limitation, neural network based models have been proposed to approximate the calculations of GED/MCS. However, deep learning models are well-known ``black boxes'', thus the typically characteristic one-to-one node/subgraph alignment process in the classical computations of GED and MCS cannot be seen. Existing methods have paid attention to approximating the node/subgraph alignment (soft alignment), but the one-to-one node alignment (hard alignment) has not yet been solved. To fill this gap, in this paper we propose a novel interpretable neural node alignment model without relying on node alignment ground truth information. Firstly, the quadratic assignment problem in classical GED computation is relaxed to a linear alignment via embedding the features in the node embedding space. Secondly, a differentiable Gumbel-Sinkhorn module is proposed to unsupervised generate the optimal one-to-one node alignment matrix. Experimental results in real-world graph datasets demonstrate that our method outperforms the state-of-the-art methods in graph similarity computation and graph retrieval tasks, achieving up to 16\% reduction in the Mean Squared Error and up to 12\% improvement in the retrieval evaluation metrics, respectively.
Exploring ChatGPT-based Augmentation Strategies for Contrastive Aspect-based Sentiment Analysis
Sep 17, 2024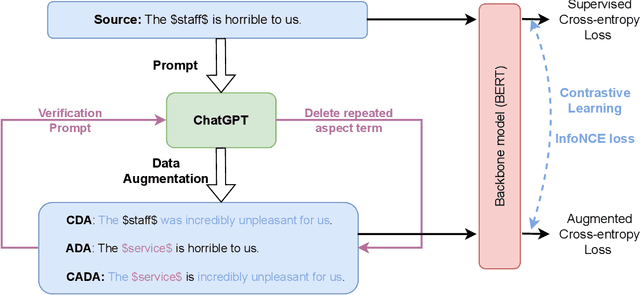

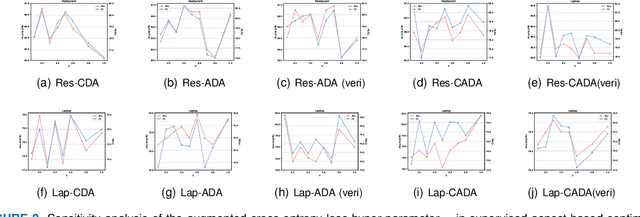
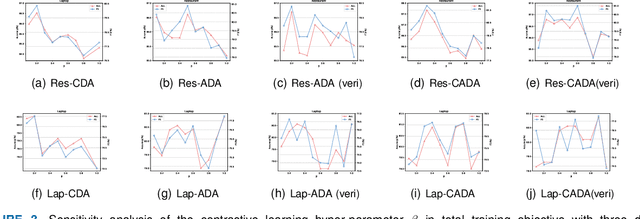
Aspect-based sentiment analysis (ABSA) involves identifying sentiment towards specific aspect terms in a sentence and allows us to uncover nuanced perspectives and attitudes on particular aspects of a product, service, or topic. However, the scarcity of labeled data poses a significant challenge to training high-quality models. To address this issue, we explore the potential of data augmentation using ChatGPT, a well-performing large language model (LLM), to enhance the sentiment classification performance towards aspect terms. Specifically, we explore three data augmentation strategies based on ChatGPT: context-focused, aspect-focused, and context-aspect data augmentation techniques. Context-focused data augmentation focuses on changing the word expression of context words in the sentence while keeping aspect terms unchanged. In contrast, aspect-focused data augmentation aims to change aspect terms but keep context words unchanged. Context-Aspect data augmentation integrates the above two data augmentations to generate augmented samples. Furthermore, we incorporate contrastive learning into the ABSA tasks to improve performance. Extensive experiments show that all three data augmentation techniques lead to performance improvements, with the context-aspect data augmentation strategy performing best and surpassing the performance of the baseline models.
Two-Timescale Synchronization and Migration for Digital Twin Networks: A Multi-Agent Deep Reinforcement Learning Approach
Sep 02, 2024



Digital twins (DTs) have emerged as a promising enabler for representing the real-time states of physical worlds and realizing self-sustaining systems. In practice, DTs of physical devices, such as mobile users (MUs), are commonly deployed in multi-access edge computing (MEC) networks for the sake of reducing latency. To ensure the accuracy and fidelity of DTs, it is essential for MUs to regularly synchronize their status with their DTs. However, MU mobility introduces significant challenges to DT synchronization. Firstly, MU mobility triggers DT migration which could cause synchronization failures. Secondly, MUs require frequent synchronization with their DTs to ensure DT fidelity. Nonetheless, DT migration among MEC servers, caused by MU mobility, may occur infrequently. Accordingly, we propose a two-timescale DT synchronization and migration framework with reliability consideration by establishing a non-convex stochastic problem to minimize the long-term average energy consumption of MUs. We use Lyapunov theory to convert the reliability constraints and reformulate the new problem as a partially observable Markov decision-making process (POMDP). Furthermore, we develop a heterogeneous agent proximal policy optimization with Beta distribution (Beta-HAPPO) method to solve it. Numerical results show that our proposed Beta-HAPPO method achieves significant improvements in energy savings when compared with other benchmarks.
Self-supervised Topic Taxonomy Discovery in the Box Embedding Space
Aug 27, 2024Topic taxonomy discovery aims at uncovering topics of different abstraction levels and constructing hierarchical relations between them. Unfortunately, most of prior work can hardly model semantic scopes of words and topics by holding the Euclidean embedding space assumption. What's worse, they infer asymmetric hierarchical relations by symmetric distances between topic embeddings. As a result, existing methods suffer from problems of low-quality topics at high abstraction levels and inaccurate hierarchical relations. To alleviate these problems, this paper develops a Box embedding-based Topic Model (BoxTM) that maps words and topics into the box embedding space, where the asymmetric metric is defined to properly infer hierarchical relations among topics. Additionally, our BoxTM explicitly infers upper-level topics based on correlation between specific topics through recursive clustering on topic boxes. Finally, extensive experiments validate high-quality of the topic taxonomy learned by BoxTM.
Lost in UNet: Improving Infrared Small Target Detection by Underappreciated Local Features
Jun 19, 2024
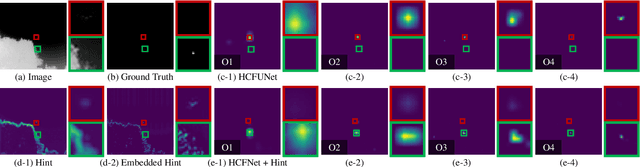


Many targets are often very small in infrared images due to the long-distance imaging meachnism. UNet and its variants, as popular detection backbone networks, downsample the local features early and cause the irreversible loss of these local features, leading to both the missed and false detection of small targets in infrared images. We propose HintU, a novel network to recover the local features lost by various UNet-based methods for effective infrared small target detection. HintU has two key contributions. First, it introduces the "Hint" mechanism for the first time, i.e., leveraging the prior knowledge of target locations to highlight critical local features. Second, it improves the mainstream UNet-based architecture to preserve target pixels even after downsampling. HintU can shift the focus of various networks (e.g., vanilla UNet, UNet++, UIUNet, MiM+, and HCFNet) from the irrelevant background pixels to a more restricted area from the beginning. Experimental results on three datasets NUDT-SIRST, SIRSTv2 and IRSTD1K demonstrate that HintU enhances the performance of existing methods with only an additional 1.88 ms cost (on RTX Titan). Additionally, the explicit constraints of HintU enhance the generalization ability of UNet-based methods. Code is available at https://github.com/Wuzhou-Quan/HintU.
AttnDreamBooth: Towards Text-Aligned Personalized Text-to-Image Generation
Jun 07, 2024


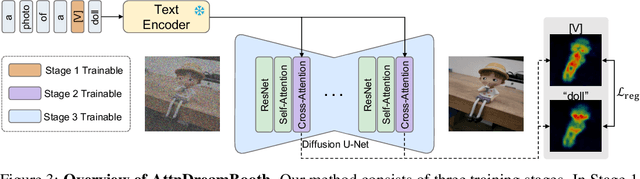
Recent advances in text-to-image models have enabled high-quality personalized image synthesis of user-provided concepts with flexible textual control. In this work, we analyze the limitations of two primary techniques in text-to-image personalization: Textual Inversion and DreamBooth. When integrating the learned concept into new prompts, Textual Inversion tends to overfit the concept, while DreamBooth often overlooks it. We attribute these issues to the incorrect learning of the embedding alignment for the concept. We introduce AttnDreamBooth, a novel approach that addresses these issues by separately learning the embedding alignment, the attention map, and the subject identity in different training stages. We also introduce a cross-attention map regularization term to enhance the learning of the attention map. Our method demonstrates significant improvements in identity preservation and text alignment compared to the baseline methods.