 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDepth-Guided Metric-Aware Temporal Consistency for Monocular Video Human Mesh Recovery
Feb 04, 2026Monocular video human mesh recovery faces fundamental challenges in maintaining metric consistency and temporal stability due to inherent depth ambiguities and scale uncertainties. While existing methods rely primarily on RGB features and temporal smoothing, they struggle with depth ordering, scale drift, and occlusion-induced instabilities. We propose a comprehensive depth-guided framework that achieves metric-aware temporal consistency through three synergistic components: A Depth-Guided Multi-Scale Fusion module that adaptively integrates geometric priors with RGB features via confidence-aware gating; A Depth-guided Metric-Aware Pose and Shape (D-MAPS) estimator that leverages depth-calibrated bone statistics for scale-consistent initialization; A Motion-Depth Aligned Refinement (MoDAR) module that enforces temporal coherence through cross-modal attention between motion dynamics and geometric cues. Our method achieves superior results on three challenging benchmarks, demonstrating significant improvements in robustness against heavy occlusion and spatial accuracy while maintaining computational efficiency.
PairEdit: Learning Semantic Variations for Exemplar-based Image Editing
Jun 09, 2025Recent advancements in text-guided image editing have achieved notable success by leveraging natural language prompts for fine-grained semantic control. However, certain editing semantics are challenging to specify precisely using textual descriptions alone. A practical alternative involves learning editing semantics from paired source-target examples. Existing exemplar-based editing methods still rely on text prompts describing the change within paired examples or learning implicit text-based editing instructions. In this paper, we introduce PairEdit, a novel visual editing method designed to effectively learn complex editing semantics from a limited number of image pairs or even a single image pair, without using any textual guidance. We propose a target noise prediction that explicitly models semantic variations within paired images through a guidance direction term. Moreover, we introduce a content-preserving noise schedule to facilitate more effective semantic learning. We also propose optimizing distinct LoRAs to disentangle the learning of semantic variations from content. Extensive qualitative and quantitative evaluations demonstrate that PairEdit successfully learns intricate semantics while significantly improving content consistency compared to baseline methods. Code will be available at https://github.com/xudonmao/PairEdit.
ConsisLoRA: Enhancing Content and Style Consistency for LoRA-based Style Transfer
Mar 13, 2025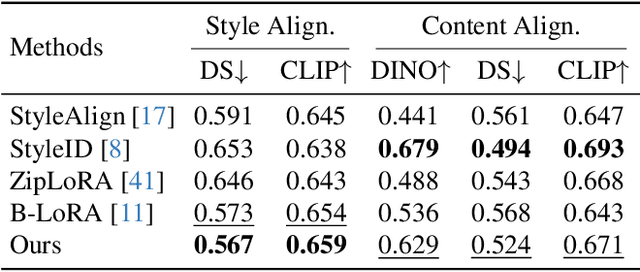

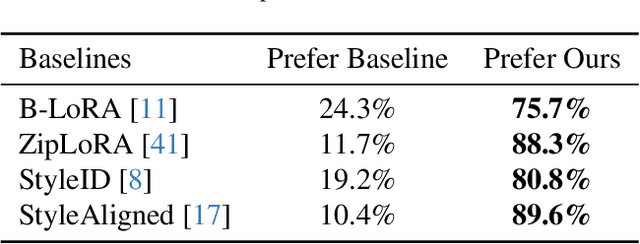
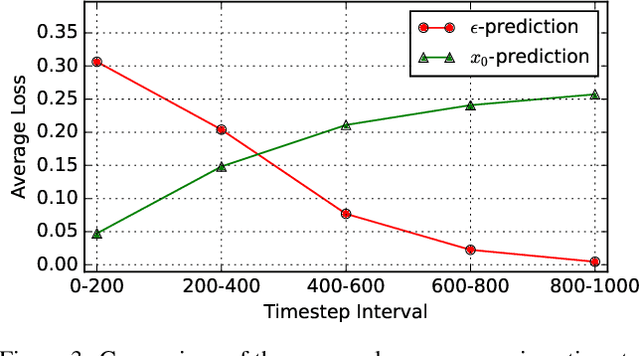
Style transfer involves transferring the style from a reference image to the content of a target image. Recent advancements in LoRA-based (Low-Rank Adaptation) methods have shown promise in effectively capturing the style of a single image. However, these approaches still face significant challenges such as content inconsistency, style misalignment, and content leakage. In this paper, we comprehensively analyze the limitations of the standard diffusion parameterization, which learns to predict noise, in the context of style transfer. To address these issues, we introduce ConsisLoRA, a LoRA-based method that enhances both content and style consistency by optimizing the LoRA weights to predict the original image rather than noise. We also propose a two-step training strategy that decouples the learning of content and style from the reference image. To effectively capture both the global structure and local details of the content image, we introduce a stepwise loss transition strategy. Additionally, we present an inference guidance method that enables continuous control over content and style strengths during inference. Through both qualitative and quantitative evaluations, our method demonstrates significant improvements in content and style consistency while effectively reducing content leakage.
CoRe: Context-Regularized Text Embedding Learning for Text-to-Image Personalization
Aug 28, 2024
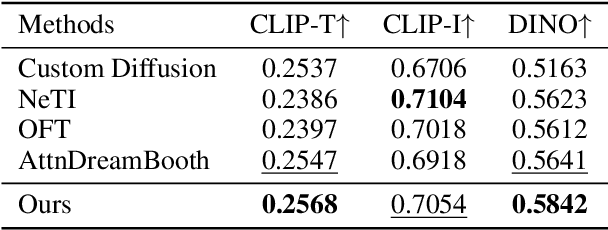
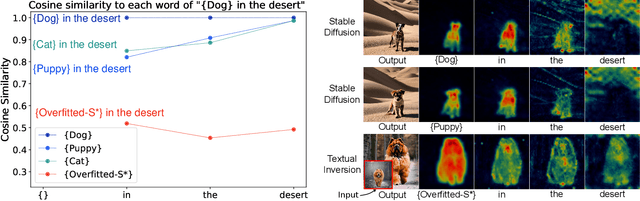
Recent advances in text-to-image personalization have enabled high-quality and controllable image synthesis for user-provided concepts. However, existing methods still struggle to balance identity preservation with text alignment. Our approach is based on the fact that generating prompt-aligned images requires a precise semantic understanding of the prompt, which involves accurately processing the interactions between the new concept and its surrounding context tokens within the CLIP text encoder. To address this, we aim to embed the new concept properly into the input embedding space of the text encoder, allowing for seamless integration with existing tokens. We introduce Context Regularization (CoRe), which enhances the learning of the new concept's text embedding by regularizing its context tokens in the prompt. This is based on the insight that appropriate output vectors of the text encoder for the context tokens can only be achieved if the new concept's text embedding is correctly learned. CoRe can be applied to arbitrary prompts without requiring the generation of corresponding images, thus improving the generalization of the learned text embedding. Additionally, CoRe can serve as a test-time optimization technique to further enhance the generations for specific prompts. Comprehensive experiments demonstrate that our method outperforms several baseline methods in both identity preservation and text alignment. Code will be made publicly available.
AttnDreamBooth: Towards Text-Aligned Personalized Text-to-Image Generation
Jun 07, 2024


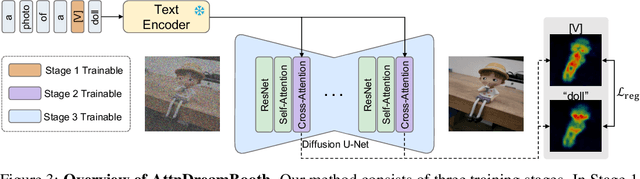
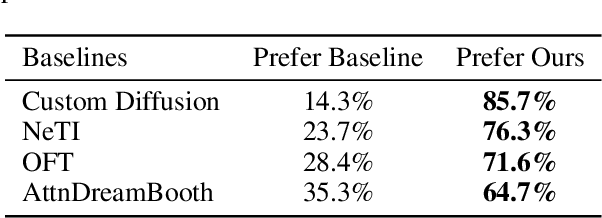
Recent advances in text-to-image models have enabled high-quality personalized image synthesis of user-provided concepts with flexible textual control. In this work, we analyze the limitations of two primary techniques in text-to-image personalization: Textual Inversion and DreamBooth. When integrating the learned concept into new prompts, Textual Inversion tends to overfit the concept, while DreamBooth often overlooks it. We attribute these issues to the incorrect learning of the embedding alignment for the concept. We introduce AttnDreamBooth, a novel approach that addresses these issues by separately learning the embedding alignment, the attention map, and the subject identity in different training stages. We also introduce a cross-attention map regularization term to enhance the learning of the attention map. Our method demonstrates significant improvements in identity preservation and text alignment compared to the baseline methods.
Cross Initialization for Personalized Text-to-Image Generation
Dec 26, 2023Recently, there has been a surge in face personalization techniques, benefiting from the advanced capabilities of pretrained text-to-image diffusion models. Among these, a notable method is Textual Inversion, which generates personalized images by inverting given images into textual embeddings. However, methods based on Textual Inversion still struggle with balancing the trade-off between reconstruction quality and editability. In this study, we examine this issue through the lens of initialization. Upon closely examining traditional initialization methods, we identified a significant disparity between the initial and learned embeddings in terms of both scale and orientation. The scale of the learned embedding can be up to 100 times greater than that of the initial embedding. Such a significant change in the embedding could increase the risk of overfitting, thereby compromising the editability. Driven by this observation, we introduce a novel initialization method, termed Cross Initialization, that significantly narrows the gap between the initial and learned embeddings. This method not only improves both reconstruction and editability but also reduces the optimization steps from 5000 to 320. Furthermore, we apply a regularization term to keep the learned embedding close to the initial embedding. We show that when combined with Cross Initialization, this regularization term can effectively improve editability. We provide comprehensive empirical evidence to demonstrate the superior performance of our method compared to the baseline methods. Notably, in our experiments, Cross Initialization is the only method that successfully edits an individual's facial expression. Additionally, a fast version of our method allows for capturing an input image in roughly 26 seconds, while surpassing the baseline methods in terms of both reconstruction and editability. Code will be made publicly available.
Cycle Encoding of a StyleGAN Encoder for Improved Reconstruction and Editability
Jul 19, 2022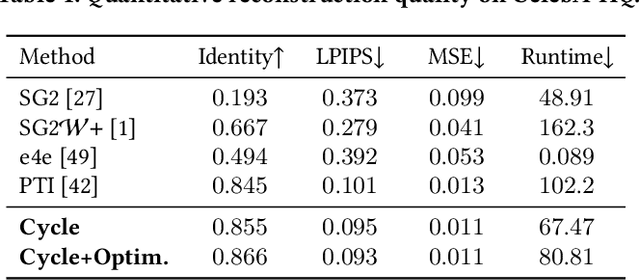
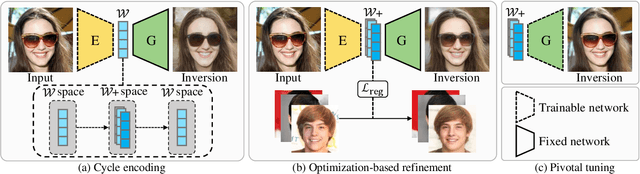
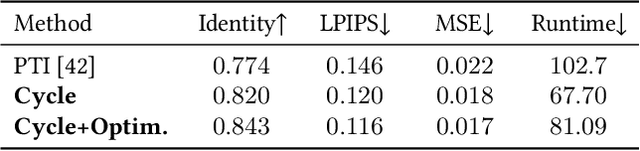
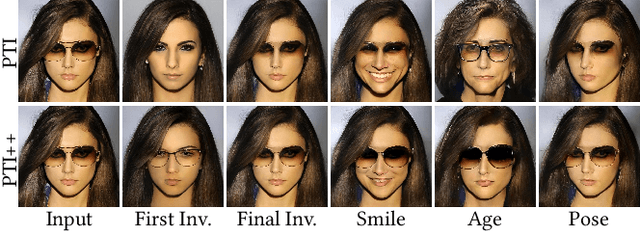
GAN inversion aims to invert an input image into the latent space of a pre-trained GAN. Despite the recent advances in GAN inversion, there remain challenges to mitigate the tradeoff between distortion and editability, i.e. reconstructing the input image accurately and editing the inverted image with a small visual quality drop. The recently proposed pivotal tuning model makes significant progress towards reconstruction and editability, by using a two-step approach that first inverts the input image into a latent code, called pivot code, and then alters the generator so that the input image can be accurately mapped into the pivot code. Here, we show that both reconstruction and editability can be improved by a proper design of the pivot code. We present a simple yet effective method, named cycle encoding, for a high-quality pivot code. The key idea of our method is to progressively train an encoder in varying spaces according to a cycle scheme: W->W+->W. This training methodology preserves the properties of both W and W+ spaces, i.e. high editability of W and low distortion of W+. To further decrease the distortion, we also propose to refine the pivot code with an optimization-based method, where a regularization term is introduced to reduce the degradation in editability. Qualitative and quantitative comparisons to several state-of-the-art methods demonstrate the superiority of our approach.
Revisiting Discriminator in GAN Compression: A Generator-discriminator Cooperative Compression Scheme
Nov 09, 2021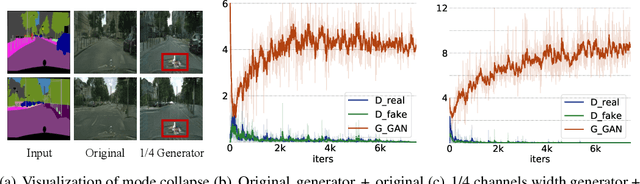
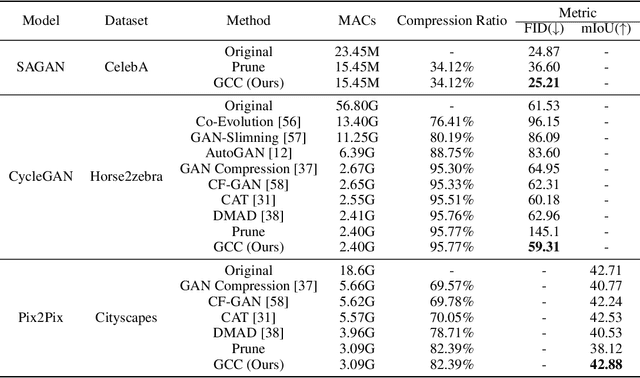
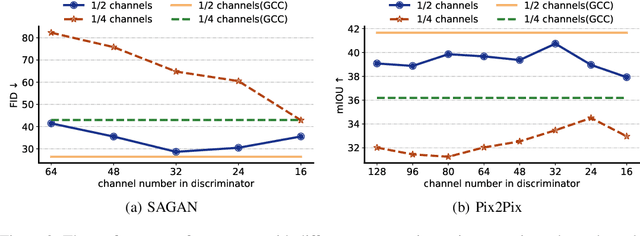

Recently, a series of algorithms have been explored for GAN compression, which aims to reduce tremendous computational overhead and memory usages when deploying GANs on resource-constrained edge devices. However, most of the existing GAN compression work only focuses on how to compress the generator, while fails to take the discriminator into account. In this work, we revisit the role of discriminator in GAN compression and design a novel generator-discriminator cooperative compression scheme for GAN compression, termed GCC. Within GCC, a selective activation discriminator automatically selects and activates convolutional channels according to a local capacity constraint and a global coordination constraint, which help maintain the Nash equilibrium with the lightweight generator during the adversarial training and avoid mode collapse. The original generator and discriminator are also optimized from scratch, to play as a teacher model to progressively refine the pruned generator and the selective activation discriminator. A novel online collaborative distillation scheme is designed to take full advantage of the intermediate feature of the teacher generator and discriminator to further boost the performance of the lightweight generator. Extensive experiments on various GAN-based generation tasks demonstrate the effectiveness and generalization of GCC. Among them, GCC contributes to reducing 80% computational costs while maintains comparable performance in image translation tasks. Our code and models are available at https://github.com/SJLeo/GCC.
The ByteDance Speaker Diarization System for the VoxCeleb Speaker Recognition Challenge 2021
Sep 05, 2021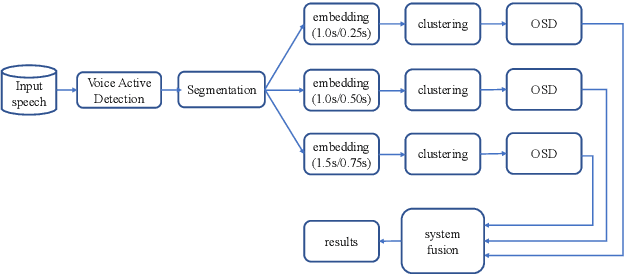

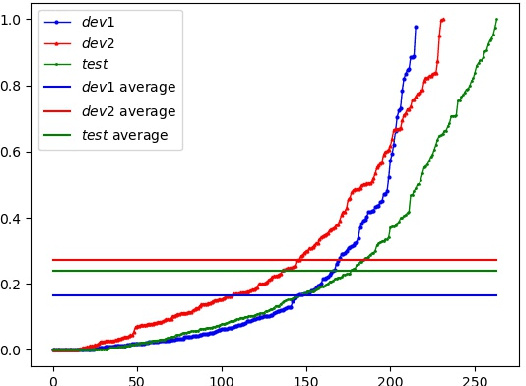
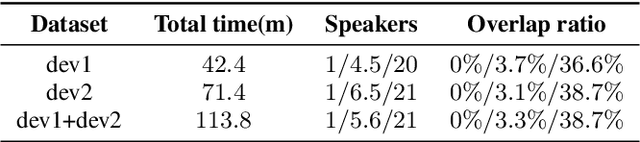
This paper describes the ByteDance speaker diarization system for the fourth track of the VoxCeleb Speaker Recognition Challenge 2021 (VoxSRC-21). The VoxSRC-21 provides both the dev set and test set of VoxConverse for use in validation and a standalone test set for evaluation. We first collect the duration and signal-to-noise ratio (SNR) of all audio and find that the distribution of the VoxConverse's test set and the VoxSRC-21's test set is more closer. Our system consists of voice active detection (VAD), speaker embedding extraction, spectral clustering followed by a re-clustering step based on agglomerative hierarchical clustering (AHC) and overlapped speech detection and handling. Finally, we integrate systems with different time scales using DOVER-Lap. Our best system achieves 5.15\% of the diarization error rate (DER) on evaluation set, ranking the second at the diarization track of the challenge.
Image-to-image Translation via Hierarchical Style Disentanglement
Mar 02, 2021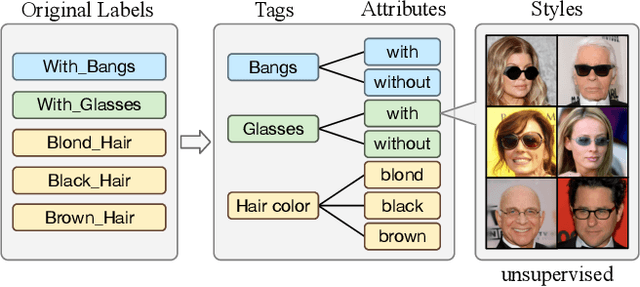


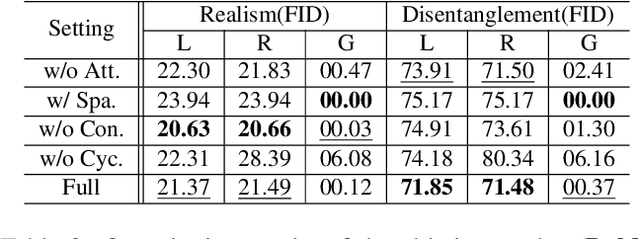
Recently, image-to-image translation has made significant progress in achieving both multi-label (\ie, translation conditioned on different labels) and multi-style (\ie, generation with diverse styles) tasks. However, due to the unexplored independence and exclusiveness in the labels, existing endeavors are defeated by involving uncontrolled manipulations to the translation results. In this paper, we propose Hierarchical Style Disentanglement (HiSD) to address this issue. Specifically, we organize the labels into a hierarchical tree structure, in which independent tags, exclusive attributes, and disentangled styles are allocated from top to bottom. Correspondingly, a new translation process is designed to adapt the above structure, in which the styles are identified for controllable translations. Both qualitative and quantitative results on the CelebA-HQ dataset verify the ability of the proposed HiSD. We hope our method will serve as a solid baseline and provide fresh insights with the hierarchically organized annotations for future research in image-to-image translation. The code has been released at https://github.com/imlixinyang/HiSD.