 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAG: A Random-Forest-Based Generative Design Framework for Uncertainty-Aware Design of Metamaterials with Complex Functional Response Requirements
Jan 19, 2026Metamaterials design for advanced functionality often entails the inverse design on nonlinear and condition-dependent responses (e.g., stress-strain relation and dispersion relation), which are described by continuous functions. Most existing design methods focus on vector-valued responses (e.g., Young's modulus and bandgap width), while the inverse design of functional responses remains challenging due to their high-dimensionality, the complexity of accommodating design requirements in inverse-design frameworks, and non-existence or non-uniqueness of feasible solutions. Although generative design approaches have shown promise, they are often data-hungry, handle design requirements heuristically, and may generate infeasible designs without uncertainty quantification. To address these challenges, we introduce a RAndom-forest-based Generative approach (RAG). By leveraging the small-data compatibility of random forests, RAG enables data-efficient predictions of high-dimensional functional responses. During the inverse design, the framework estimates the likelihood through the ensemble which quantifies the trustworthiness of generated designs while reflecting the relative difficulty across different requirements. The one-to-many mapping is addressed through single-shot design generation by sampling from the conditional likelihood. We demonstrate RAG on: 1) acoustic metamaterials with prescribed partial passbands/stopbands, and 2) mechanical metamaterials with targeted snap-through responses, using 500 and 1057 samples, respectively. Its data-efficiency is benchmarked against neural networks on a public mechanical metamaterial dataset with nonlinear stress-strain relations. Our framework provides a lightweight, trustworthy pathway to inverse design involving functional responses, expensive simulations, and complex design requirements, beyond metamaterials.
Deep GraphRAG: A Balanced Approach to Hierarchical Retrieval and Adaptive Integration
Jan 16, 2026Graph-based Retrieval-Augmented Generation (GraphRAG) frameworks face a trade-off between the comprehensiveness of global search and the efficiency of local search. Existing methods are often challenged by navigating large-scale hierarchical graphs, optimizing retrieval paths, and balancing exploration-exploitation dynamics, frequently lacking robust multi-stage re-ranking. To overcome these deficits, we propose Deep GraphRAG, a framework designed for a balanced approach to hierarchical retrieval and adaptive integration. It introduces a hierarchical global-to-local retrieval strategy that integrates macroscopic inter-community and microscopic intra-community contextual relations. This strategy employs a three-stage process: (1) inter-community filtering, which prunes the search space using local context; (2) community-level refinement, which prioritizes relevant subgraphs via entity-interaction analysis; and (3) entity-level fine-grained search within target communities. A beam search-optimized dynamic re-ranking module guides this process, continuously filtering candidates to balance efficiency and global comprehensiveness. Deep GraphRAG also features a Knowledge Integration Module leveraging a compact LLM, trained with Dynamic Weighting Reward GRPO (DW-GRPO). This novel reinforcement learning approach dynamically adjusts reward weights to balance three key objectives: relevance, faithfulness, and conciseness. This training enables compact models (1.5B) to approach the performance of large models (70B) in the integration task. Evaluations on Natural Questions and HotpotQA demonstrate that Deep GraphRAG significantly outperforms baseline graph retrieval methods in both accuracy and efficiency.
Beyond Model Scaling: Test-Time Intervention for Efficient Deep Reasoning
Jan 16, 2026Large Reasoning Models (LRMs) excel at multi-step reasoning but often suffer from inefficient reasoning processes like overthinking and overshoot, where excessive or misdirected reasoning increases computational cost and degrades performance. Existing efficient reasoning methods operate in a closed-loop manner, lacking mechanisms for external intervention to guide the reasoning process. To address this, we propose Think-with-Me, a novel test-time interactive reasoning paradigm that introduces external feedback intervention into the reasoning process. Our key insights are that transitional conjunctions serve as natural points for intervention, signaling phases of self-validation or exploration and using transitional words appropriately to prolong the reasoning enhances performance, while excessive use affects performance. Building on these insights, Think-with-Me pauses reasoning at these points for external feedback, adaptively extending or terminating reasoning to reduce redundancy while preserving accuracy. The feedback is generated via a multi-criteria evaluation (rationality and completeness) and comes from either human or LLM proxies. We train the target model using Group Relative Policy Optimization (GRPO) to adapt to this interactive mode. Experiments show that Think-with-Me achieves a superior balance between accuracy and reasoning length under limited context windows. On AIME24, Think-with-Me outperforms QwQ-32B by 7.19% in accuracy while reducing average reasoning length by 81% under an 8K window. The paradigm also benefits security and creative tasks.
Rethinking Generative Human Video Coding with Implicit Motion Transformation
Jun 12, 2025Beyond traditional hybrid-based video codec, generative video codec could achieve promising compression performance by evolving high-dimensional signals into compact feature representations for bitstream compactness at the encoder side and developing explicit motion fields as intermediate supervision for high-quality reconstruction at the decoder side. This paradigm has achieved significant success in face video compression. However, compared to facial videos, human body videos pose greater challenges due to their more complex and diverse motion patterns, i.e., when using explicit motion guidance for Generative Human Video Coding (GHVC), the reconstruction results could suffer severe distortions and inaccurate motion. As such, this paper highlights the limitations of explicit motion-based approaches for human body video compression and investigates the GHVC performance improvement with the aid of Implicit Motion Transformation, namely IMT. In particular, we propose to characterize complex human body signal into compact visual features and transform these features into implicit motion guidance for signal reconstruction. Experimental results demonstrate the effectiveness of the proposed IMT paradigm, which can facilitate GHVC to achieve high-efficiency compression and high-fidelity synthesis.
Generative Models at the Frontier of Compression: A Survey on Generative Face Video Coding
Jun 09, 2025The rise of deep generative models has greatly advanced video compression, reshaping the paradigm of face video coding through their powerful capability for semantic-aware representation and lifelike synthesis. Generative Face Video Coding (GFVC) stands at the forefront of this revolution, which could characterize complex facial dynamics into compact latent codes for bitstream compactness at the encoder side and leverages powerful deep generative models to reconstruct high-fidelity face signal from the compressed latent codes at the decoder side. As such, this well-designed GFVC paradigm could enable high-fidelity face video communication at ultra-low bitrate ranges, far surpassing the capabilities of the latest Versatile Video Coding (VVC) standard. To pioneer foundational research and accelerate the evolution of GFVC, this paper presents the first comprehensive survey of GFVC technologies, systematically bridging critical gaps between theoretical innovation and industrial standardization. In particular, we first review a broad range of existing GFVC methods with different feature representations and optimization strategies, and conduct a thorough benchmarking analysis. In addition, we construct a large-scale GFVC-compressed face video database with subjective Mean Opinion Scores (MOSs) based on human perception, aiming to identify the most appropriate quality metrics tailored to GFVC. Moreover, we summarize the GFVC standardization potentials with a unified high-level syntax and develop a low-complexity GFVC system which are both expected to push forward future practical deployments and applications. Finally, we envision the potential of GFVC in industrial applications and deliberate on the current challenges and future opportunities.
Compressing Human Body Video with Interactive Semantics: A Generative Approach
May 22, 2025In this paper, we propose to compress human body video with interactive semantics, which can facilitate video coding to be interactive and controllable by manipulating semantic-level representations embedded in the coded bitstream. In particular, the proposed encoder employs a 3D human model to disentangle nonlinear dynamics and complex motion of human body signal into a series of configurable embeddings, which are controllably edited, compactly compressed, and efficiently transmitted. Moreover, the proposed decoder can evolve the mesh-based motion fields from these decoded semantics to realize the high-quality human body video reconstruction. Experimental results illustrate that the proposed framework can achieve promising compression performance for human body videos at ultra-low bitrate ranges compared with the state-of-the-art video coding standard Versatile Video Coding (VVC) and the latest generative compression schemes. Furthermore, the proposed framework enables interactive human body video coding without any additional pre-/post-manipulation processes, which is expected to shed light on metaverse-related digital human communication in the future.
Leveraging Diffusion Knowledge for Generative Image Compression with Fractal Frequency-Aware Band Learning
Mar 14, 2025By optimizing the rate-distortion-realism trade-off, generative image compression approaches produce detailed, realistic images instead of the only sharp-looking reconstructions produced by rate-distortion-optimized models. In this paper, we propose a novel deep learning-based generative image compression method injected with diffusion knowledge, obtaining the capacity to recover more realistic textures in practical scenarios. Efforts are made from three perspectives to navigate the rate-distortion-realism trade-off in the generative image compression task. First, recognizing the strong connection between image texture and frequency-domain characteristics, we design a Fractal Frequency-Aware Band Image Compression (FFAB-IC) network to effectively capture the directional frequency components inherent in natural images. This network integrates commonly used fractal band feature operations within a neural non-linear mapping design, enhancing its ability to retain essential given information and filter out unnecessary details. Then, to improve the visual quality of image reconstruction under limited bandwidth, we integrate diffusion knowledge into the encoder and implement diffusion iterations into the decoder process, thus effectively recovering lost texture details. Finally, to fully leverage the spatial and frequency intensity information, we incorporate frequency- and content-aware regularization terms to regularize the training of the generative image compression network. Extensive experiments in quantitative and qualitative evaluations demonstrate the superiority of the proposed method, advancing the boundaries of achievable distortion-realism pairs, i.e., our method achieves better distortions at high realism and better realism at low distortion than ever before.
ConsisLoRA: Enhancing Content and Style Consistency for LoRA-based Style Transfer
Mar 13, 2025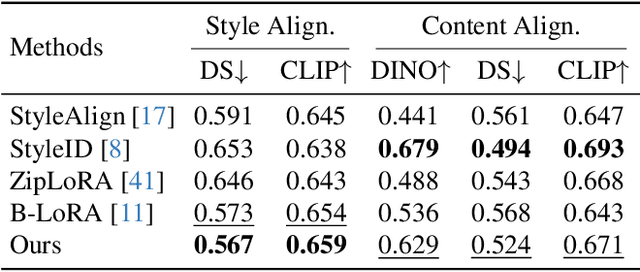

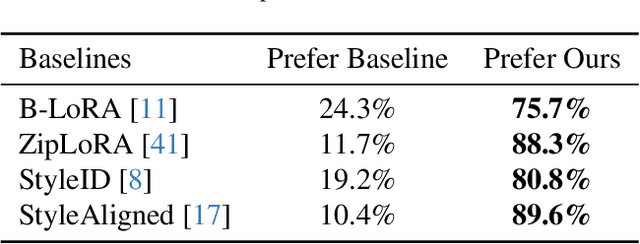
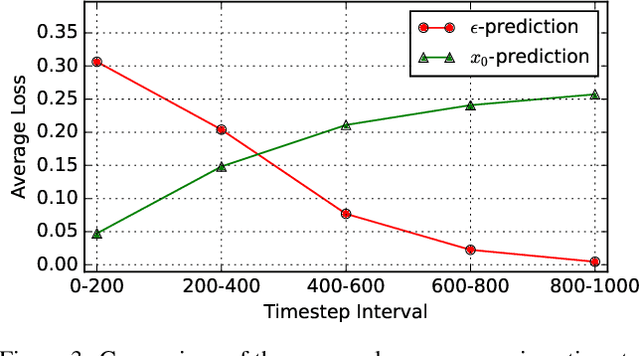
Style transfer involves transferring the style from a reference image to the content of a target image. Recent advancements in LoRA-based (Low-Rank Adaptation) methods have shown promise in effectively capturing the style of a single image. However, these approaches still face significant challenges such as content inconsistency, style misalignment, and content leakage. In this paper, we comprehensively analyze the limitations of the standard diffusion parameterization, which learns to predict noise, in the context of style transfer. To address these issues, we introduce ConsisLoRA, a LoRA-based method that enhances both content and style consistency by optimizing the LoRA weights to predict the original image rather than noise. We also propose a two-step training strategy that decouples the learning of content and style from the reference image. To effectively capture both the global structure and local details of the content image, we introduce a stepwise loss transition strategy. Additionally, we present an inference guidance method that enables continuous control over content and style strengths during inference. Through both qualitative and quantitative evaluations, our method demonstrates significant improvements in content and style consistency while effectively reducing content leakage.
Pleno-Generation: A Scalable Generative Face Video Compression Framework with Bandwidth Intelligence
Feb 24, 2025



Generative model based compact video compression is typically operated within a relative narrow range of bitrates, and often with an emphasis on ultra-low rate applications. There has been an increasing consensus in the video communication industry that full bitrate coverage should be enabled by generative coding. However, this is an extremely difficult task, largely because generation and compression, although related, have distinct goals and trade-offs. The proposed Pleno-Generation (PGen) framework distinguishes itself through its exceptional capabilities in ensuring the robustness of video coding by utilizing a wider range of bandwidth for generation via bandwidth intelligence. In particular, we initiate our research of PGen with face video coding, and PGen offers a paradigm shift that prioritizes high-fidelity reconstruction over pursuing compact bitstream. The novel PGen framework leverages scalable representation and layered reconstruction for Generative Face Video Compression (GFVC), in an attempt to imbue the bitstream with intelligence in different granularity. Experimental results illustrate that the proposed PGen framework can facilitate existing GFVC algorithms to better deliver high-fidelity and faithful face videos. In addition, the proposed framework can allow a greater space of flexibility for coding applications and show superior RD performance with a much wider bitrate range in terms of various quality evaluations. Moreover, in comparison with the latest Versatile Video Coding (VVC) codec, the proposed scheme achieves competitive Bj{\o}ntegaard-delta-rate savings for perceptual-level evaluations.
Standardizing Generative Face Video Compression using Supplemental Enhancement Information
Oct 19, 2024This paper proposes a Generative Face Video Compression (GFVC) approach using Supplemental Enhancement Information (SEI), where a series of compact spatial and temporal representations of a face video signal (i.e., 2D/3D key-points, facial semantics and compact features) can be coded using SEI message and inserted into the coded video bitstream. At the time of writing, the proposed GFVC approach is an official "technology under consideration" (TuC) for standardization by the Joint Video Experts Team (JVET) of ISO/IEC JVT 1/SC 29 and ITU-T SG16. To the best of the authors' knowledge, the JVET work on the proposed SEI-based GFVC approach is the first standardization activity for generative video compression. The proposed SEI approach has not only advanced the reconstruction quality of early-day Model-Based Coding (MBC) via the state-of-the-art generative technique, but also established a new SEI definition for future GFVC applications and deployment. Experimental results illustrate that the proposed SEI-based GFVC approach can achieve remarkable rate-distortion performance compared with the latest Versatile Video Coding (VVC) standard, whilst also potentially enabling a wide variety of functionalities including user-specified animation/filtering and metaverse-related applications.