 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDepth-Guided Metric-Aware Temporal Consistency for Monocular Video Human Mesh Recovery
Feb 04, 2026Monocular video human mesh recovery faces fundamental challenges in maintaining metric consistency and temporal stability due to inherent depth ambiguities and scale uncertainties. While existing methods rely primarily on RGB features and temporal smoothing, they struggle with depth ordering, scale drift, and occlusion-induced instabilities. We propose a comprehensive depth-guided framework that achieves metric-aware temporal consistency through three synergistic components: A Depth-Guided Multi-Scale Fusion module that adaptively integrates geometric priors with RGB features via confidence-aware gating; A Depth-guided Metric-Aware Pose and Shape (D-MAPS) estimator that leverages depth-calibrated bone statistics for scale-consistent initialization; A Motion-Depth Aligned Refinement (MoDAR) module that enforces temporal coherence through cross-modal attention between motion dynamics and geometric cues. Our method achieves superior results on three challenging benchmarks, demonstrating significant improvements in robustness against heavy occlusion and spatial accuracy while maintaining computational efficiency.
ConsisLoRA: Enhancing Content and Style Consistency for LoRA-based Style Transfer
Mar 13, 2025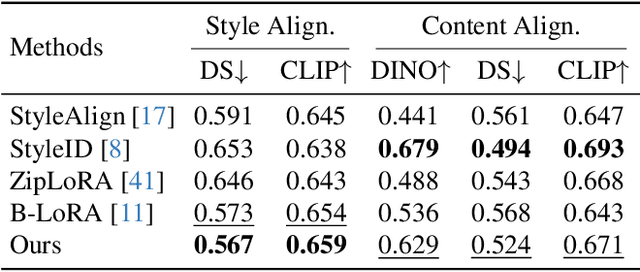

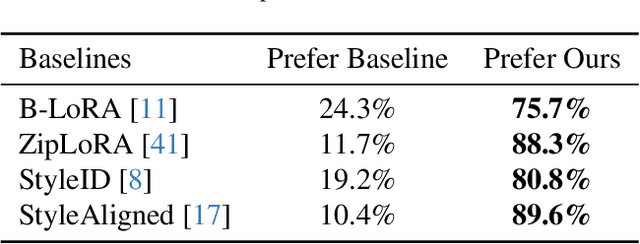
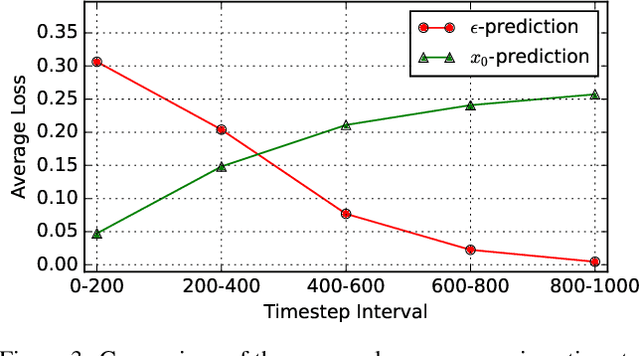
Style transfer involves transferring the style from a reference image to the content of a target image. Recent advancements in LoRA-based (Low-Rank Adaptation) methods have shown promise in effectively capturing the style of a single image. However, these approaches still face significant challenges such as content inconsistency, style misalignment, and content leakage. In this paper, we comprehensively analyze the limitations of the standard diffusion parameterization, which learns to predict noise, in the context of style transfer. To address these issues, we introduce ConsisLoRA, a LoRA-based method that enhances both content and style consistency by optimizing the LoRA weights to predict the original image rather than noise. We also propose a two-step training strategy that decouples the learning of content and style from the reference image. To effectively capture both the global structure and local details of the content image, we introduce a stepwise loss transition strategy. Additionally, we present an inference guidance method that enables continuous control over content and style strengths during inference. Through both qualitative and quantitative evaluations, our method demonstrates significant improvements in content and style consistency while effectively reducing content leakage.
CoRe: Context-Regularized Text Embedding Learning for Text-to-Image Personalization
Aug 28, 2024
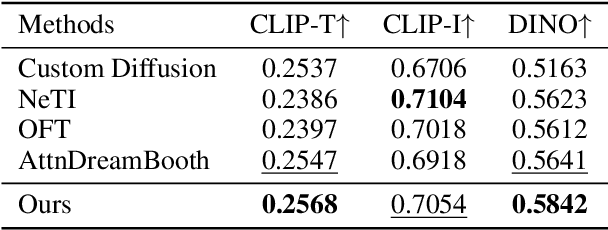
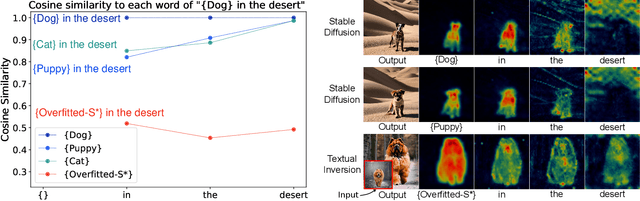
Recent advances in text-to-image personalization have enabled high-quality and controllable image synthesis for user-provided concepts. However, existing methods still struggle to balance identity preservation with text alignment. Our approach is based on the fact that generating prompt-aligned images requires a precise semantic understanding of the prompt, which involves accurately processing the interactions between the new concept and its surrounding context tokens within the CLIP text encoder. To address this, we aim to embed the new concept properly into the input embedding space of the text encoder, allowing for seamless integration with existing tokens. We introduce Context Regularization (CoRe), which enhances the learning of the new concept's text embedding by regularizing its context tokens in the prompt. This is based on the insight that appropriate output vectors of the text encoder for the context tokens can only be achieved if the new concept's text embedding is correctly learned. CoRe can be applied to arbitrary prompts without requiring the generation of corresponding images, thus improving the generalization of the learned text embedding. Additionally, CoRe can serve as a test-time optimization technique to further enhance the generations for specific prompts. Comprehensive experiments demonstrate that our method outperforms several baseline methods in both identity preservation and text alignment. Code will be made publicly available.
AttnDreamBooth: Towards Text-Aligned Personalized Text-to-Image Generation
Jun 07, 2024


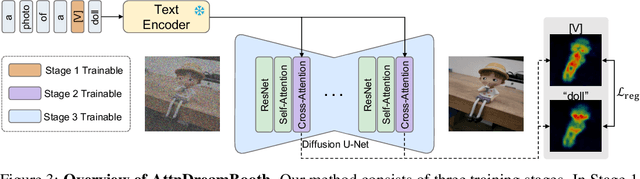
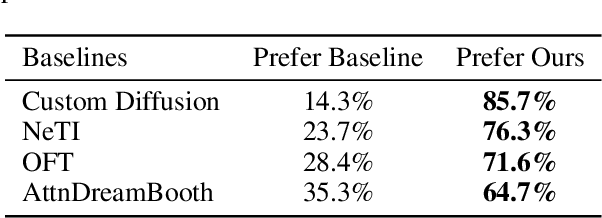
Recent advances in text-to-image models have enabled high-quality personalized image synthesis of user-provided concepts with flexible textual control. In this work, we analyze the limitations of two primary techniques in text-to-image personalization: Textual Inversion and DreamBooth. When integrating the learned concept into new prompts, Textual Inversion tends to overfit the concept, while DreamBooth often overlooks it. We attribute these issues to the incorrect learning of the embedding alignment for the concept. We introduce AttnDreamBooth, a novel approach that addresses these issues by separately learning the embedding alignment, the attention map, and the subject identity in different training stages. We also introduce a cross-attention map regularization term to enhance the learning of the attention map. Our method demonstrates significant improvements in identity preservation and text alignment compared to the baseline methods.
SketchBodyNet: A Sketch-Driven Multi-faceted Decoder Network for 3D Human Reconstruction
Oct 10, 2023



Reconstructing 3D human shapes from 2D images has received increasing attention recently due to its fundamental support for many high-level 3D applications. Compared with natural images, freehand sketches are much more flexible to depict various shapes, providing a high potential and valuable way for 3D human reconstruction. However, such a task is highly challenging. The sparse abstract characteristics of sketches add severe difficulties, such as arbitrariness, inaccuracy, and lacking image details, to the already badly ill-posed problem of 2D-to-3D reconstruction. Although current methods have achieved great success in reconstructing 3D human bodies from a single-view image, they do not work well on freehand sketches. In this paper, we propose a novel sketch-driven multi-faceted decoder network termed SketchBodyNet to address this task. Specifically, the network consists of a backbone and three separate attention decoder branches, where a multi-head self-attention module is exploited in each decoder to obtain enhanced features, followed by a multi-layer perceptron. The multi-faceted decoders aim to predict the camera, shape, and pose parameters, respectively, which are then associated with the SMPL model to reconstruct the corresponding 3D human mesh. In learning, existing 3D meshes are projected via the camera parameters into 2D synthetic sketches with joints, which are combined with the freehand sketches to optimize the model. To verify our method, we collect a large-scale dataset of about 26k freehand sketches and their corresponding 3D meshes containing various poses of human bodies from 14 different angles. Extensive experimental results demonstrate our SketchBodyNet achieves superior performance in reconstructing 3D human meshes from freehand sketches.
KSS-ICP: Point Cloud Registration based on Kendall Shape Space
Nov 05, 2022Point cloud registration is a popular topic which has been widely used in 3D model reconstruction, location, and retrieval. In this paper, we propose a new registration method, KSS-ICP, to address the rigid registration task in Kendall shape space (KSS) with Iterative Closest Point (ICP). The KSS is a quotient space that removes influences of translations, scales, and rotations for shape feature-based analysis. Such influences can be concluded as the similarity transformations that do not change the shape feature. The point cloud representation in KSS is invariant to similarity transformations. We utilize such property to design the KSS-ICP for point cloud registration. To tackle the difficulty to achieve the KSS representation in general, the proposed KSS-ICP formulates a practical solution that does not require complex feature analysis, data training, and optimization. With a simple implementation, KSS-ICP achieves more accurate registration from point clouds. It is robust to similarity transformation, non-uniform density, noise, and defective parts. Experiments show that KSS-ICP has better performance than the state of the art.
Voxel Structure-based Mesh Reconstruction from a 3D Point Cloud
Apr 23, 2021
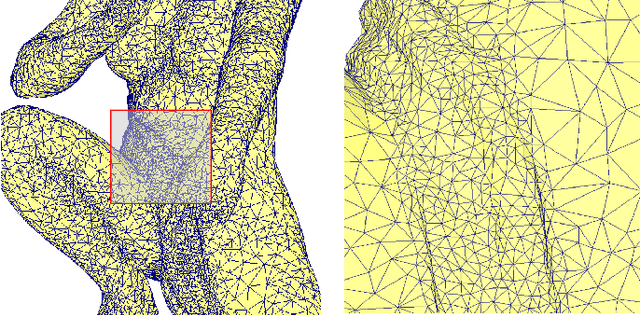


Mesh reconstruction from a 3D point cloud is an important topic in the fields of computer graphic, computer vision, and multimedia analysis. In this paper, we propose a voxel structure-based mesh reconstruction framework. It provides the intrinsic metric to improve the accuracy of local region detection. Based on the detected local regions, an initial reconstructed mesh can be obtained. With the mesh optimization in our framework, the initial reconstructed mesh is optimized into an isotropic one with the important geometric features such as external and internal edges. The experimental results indicate that our framework shows great advantages over peer ones in terms of mesh quality, geometric feature keeping, and processing speed.